Vjerojatnost normalno raspoređene slučajne varijable. Normalni zakon distribucije vjerovatnoće kontinuirane slučajne varijable. Odnos sa drugim distribucijama
Zamena φ(x)=π /4 ,f(x)=1/(b-a)
D[π /4]=( /720) ).
№319 Cube edge x izmjereno približno a . Uzimajući u obzir ivicu kocke kao slučajnu varijablu X koja je ravnomjerno raspoređena u intervalu (a,b), pronađite matematičko očekivanje i varijansu volumena kocke.
1. Nađimo matematičko očekivanje površine kruga - slučajnu varijablu Y=φ(K)= - prema formuli
M[φ(X)]= ![]()
Stavljanje φ(x)= ,f(x)=1/(b-a) i nakon integracije dobijamo
M( )=
 .
.
2. Pomoću formule pronađite disperziju površine kruga
D[φ(X)]= ![]() -
-
![]() .
.
Zamena φ(x)= ,f(x)=1/(b-a) i nakon integracije dobijamo
D =
 .
.
№320 Slučajne varijable X i Y su nezavisne i ravnomerno raspoređene: X-u intervalu (a,b), Y-u intervalu (c,d) Naći matematičko očekivanje proizvoda XY.
Matematičko očekivanje proizvoda nezavisnih slučajnih varijabli jednako je proizvodu njihovih matematičkih očekivanja, tj.
M(XY)= 
№321 Slučajne varijable X i Y su nezavisne i ravnomerno raspoređene: X - u intervalu (a,b), Y - u intervalu (c,d). Pronađite varijansu XY proizvoda.
Koristimo formulu
D(XY)=M[
Matematičko očekivanje proizvoda nezavisnih slučajnih varijabli jednako je proizvodu njihovih matematičkih očekivanja, dakle
Nađimo M po formuli
M[φ(X)]= ![]()
Zamena φ(x)= ,f(x)=1/(b-a) i integracijom, dobijamo
M (**)
Slično, nalazimo
M (***)
Zamena M(X)=(a+b)/2, M(Y)=(c+d)/2, kao i (***) i (**) u (*), konačno dobijamo
D(XY)= -[
![]() .
.
№322 Matematičko očekivanje normalno raspoređene slučajne varijable X je a=3 i standardna devijacija σ=2. Napišite gustinu vjerovatnoće X.
Koristimo formulu:
f(x)=  .
.
Zamjenom dostupnih vrijednosti dobijamo:
f(x)=  = f(x)=
= f(x)=  .
.
№323 Napišite gustinu vjerovatnoće normalno raspoređene slučajne varijable X, znajući da je M(X)=3, D(X)=16.
Koristimo formulu:
f(x)= .
Da bismo pronašli vrijednost σ, koristimo svojstvo da je standardna devijacija slučajne varijable X jednak je kvadratnom korijenu njegove varijanse. Dakle, σ=4, M(X)=a=3. Zamjenom u formulu dobijemo
f(x)=  =
=
 .
.
№324 Normalno raspoređena slučajna varijabla X je data gustoćom
f(x)= ![]() .
Pronađite matematičko očekivanje i varijansu X.
.
Pronađite matematičko očekivanje i varijansu X.
Koristimo formulu
f(x)= ,
gdje a-očekivana vrijednost, σ -standardna devijacija X. Iz ove formule slijedi da a=M(X)=1. Da bismo pronašli varijansu, koristimo svojstvo da je standardna devijacija slučajne varijable X jednak je kvadratnom korijenu njegove varijanse. Shodno tome D(X)= =
Odgovor: matematičko očekivanje je 1; varijansa je 25.
Bondarchuk Rodion
S obzirom na funkciju distribucije normaliziranog normalnog zakona ![]() . Naći gustinu distribucije f(x).
. Naći gustinu distribucije f(x).
Znajući to ![]() , nalazimo f(x).
, nalazimo f(x).

odgovor: ![]()
Dokazati da je Laplaceova funkcija ![]() . čudno:
. čudno: ![]() .
.

Napravićemo zamjenu


Napravimo obrnutu zamjenu i dobijemo:
![]() =
= ![]() =
=


Tu će biti i zadaci za samostalno rješenje na koje možete vidjeti odgovore.
Normalna distribucija: teorijske osnove
Primjeri slučajnih varijabli raspoređenih prema normalnom zakonu su visina osobe, masa ulovljene ribe iste vrste. Normalna distribucija znači sljedeće : postoje vrijednosti ljudske visine, mase riba iste vrste, koje se intuitivno percipiraju kao "normalne" (a zapravo - prosječne), i mnogo su češće u dovoljno velikom uzorku od onih koji se razlikuju gore ili dolje.
Normalna raspodjela vjerovatnoće kontinuirane slučajne varijable (ponekad Gaussova raspodjela) može se nazvati zvonastom zbog činjenice da je funkcija gustoće ove raspodjele, koja je simetrična u odnosu na srednju vrijednost, vrlo slična rezu zvona ( crvena kriva na gornjoj slici).
Vjerovatnoća ispunjavanja određenih vrijednosti u uzorku jednaka je površini figure ispod krive, a u slučaju normalne raspodjele vidimo da je ispod vrha "zvona" , što odgovara vrijednostima koje teže prosjeku, površina, a samim tim i vjerovatnoća, je veća nego ispod rubova. Dakle, dobijamo isto što je već rečeno: vjerovatnoća susreta s osobom "normalne" visine, ulov ribe "normalne" težine veća je nego za vrijednosti koje se razlikuju gore ili dolje. U mnogim slučajevima u praksi, greške mjerenja se distribuiraju prema zakonu koji je blizak normalnom.
Zaustavimo se ponovo na slici na početku lekcije koja prikazuje funkciju gustoće normalne distribucije. Grafikon ove funkcije dobijen je izračunavanjem nekog uzorka podataka u softverskom paketu STATISTIKA. Na njemu kolone histograma predstavljaju intervale vrijednosti uzorka čija je distribucija bliska (ili, kako kažu u statistici, ne razlikuje se značajno od) samom grafu funkcije gustoće normalne distribucije, koji je crvena kriva. Grafikon pokazuje da je ova kriva zaista zvonastog oblika.
Normalna distribucija je vrijedna na mnogo načina jer znajući samo srednju vrijednost kontinuirane slučajne varijable i standardnu devijaciju, možete izračunati bilo koju vjerovatnoću povezanu s tom varijablom.
Normalna distribucija ima dodatnu prednost jer je jedna od najlakših za korištenje statistički kriterijumi koji se koriste za testiranje statističkih hipoteza - Studentov t-test- može se koristiti samo u slučaju kada podaci uzorka poštuju zakon normalne distribucije.
Funkcija gustoće normalne distribucije kontinuirane slučajne varijable može se pronaći pomoću formule:
 ,
,
gdje x- vrijednost varijable, - srednja vrijednost, - standardna devijacija, e\u003d 2,71828 ... - osnova prirodnog logaritma, \u003d 3,1416 ...
Svojstva funkcije gustoće normalne distribucije
Promjene srednje vrijednosti pomiču zvonastu krivu u smjeru ose Ox. Ako se povećava, kriva se pomiče udesno, ako se smanjuje, onda ulijevo.
Ako se standardna devijacija promijeni, tada se mijenja visina vrha krive. Kada se standardna devijacija povećava, vrh krivulje je viši, kada se smanjuje, niži.
Vjerovatnoća da će vrijednost normalno raspoređene slučajne varijable pasti unutar datog intervala
Već u ovom paragrafu počet ćemo rješavati praktične probleme čije je značenje naznačeno u naslovu. Hajde da analiziramo koje mogućnosti teorija pruža za rešavanje problema. Početni koncept za izračunavanje vjerovatnoće da normalno raspoređena slučajna varijabla padne u dati interval je integralna funkcija normalne distribucije.
Integralna funkcija normalne distribucije:
 .
.
Međutim, problematično je dobiti tabele za svaku moguću kombinaciju srednje vrijednosti i standardne devijacije. Stoga je jedan od jednostavnih načina da se izračuna vjerovatnoća da će normalno raspoređena slučajna varijabla pasti u dati interval korištenje tablica vjerovatnoće za standardiziranu normalnu distribuciju.
Normalna distribucija se naziva standardizovana ili normalizovana distribucija., čija je srednja vrijednost , a standardna devijacija je .
Funkcija gustoće standardizirane normalne distribucije:
![]() .
.
Kumulativna funkcija standardizirane normalne distribucije:
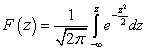 .
.
Na slici ispod prikazana je integralna funkcija standardizovane normalne distribucije, čiji je graf dobijen izračunavanjem nekog uzorka podataka u softverskom paketu STATISTIKA. Sam graf je crvena kriva, a vrijednosti uzorka joj se približavaju.

Da biste uvećali sliku, možete kliknuti na nju levim tasterom miša.
Standardizacija slučajne varijable znači prelazak sa originalnih jedinica korištenih u zadatku na standardizirane jedinice. Standardizacija se vrši prema formuli
U praksi, sve moguće vrijednosti slučajne varijable često nisu poznate, pa se vrijednosti srednje vrijednosti i standardne devijacije ne mogu precizno odrediti. Oni su zamijenjeni aritmetičkom sredinom opažanja i standardnom devijacijom s. Vrijednost z izražava odstupanja vrijednosti slučajne varijable od aritmetičke sredine pri mjerenju standardnih devijacija.
Otvoreni interval
Tabela vjerovatnoća za standardiziranu normalnu distribuciju, koja je dostupna u gotovo svakoj knjizi o statistici, sadrži vjerovatnoće da slučajna varijabla ima standardnu normalnu distribuciju Z poprima vrijednost manju od određenog broja z. Odnosno, pasti će u otvoreni interval od minus beskonačnosti do z. Na primjer, vjerojatnost da vrijednost Z manje od 1,5 je jednako 0,93319.
Primjer 1 Kompanija proizvodi dijelove koji imaju normalno raspoređeni vijek trajanja sa srednjom vrijednosti od 1000 i standardnom devijacijom od 200 sati.
Za nasumično odabrani dio izračunajte vjerovatnoću da će njegov vijek trajanja biti najmanje 900 sati.
Rješenje. Hajde da uvedemo prvu notaciju:
Željena vjerovatnoća.
Vrijednosti slučajne varijable su u otvorenom intervalu. Ali možemo izračunati vjerovatnoću da će slučajna varijabla zauzeti vrijednost manju od date vrijednosti, a prema uvjetu zadatka potrebno je pronaći jednaku ili veću vrijednost od date. Ovo je drugi dio prostora ispod zvonaste krivine. Stoga, da bismo pronašli željenu vjerovatnoću, potrebno je od jedne oduzeti spomenutu vjerovatnoću da će slučajna varijabla poprimiti vrijednost manju od navedenih 900:
Sada slučajnu varijablu treba standardizirati.
Nastavljamo da uvodimo notaciju:
z = (X ≤ 900) ;
x= 900 - data vrijednost slučajne varijable;
μ = 1000 - prosječna vrijednost;
σ = 200 - standardna devijacija.
Na osnovu ovih podataka dobijamo uslove zadatka:
![]() .
.
Prema tabelama standardizovane slučajne varijable (granica intervala) z= −0,5 odgovara vjerovatnoći 0,30854. Oduzmite ga od jedinice i dobijete ono što je potrebno u uslovu problema:
Dakle, vjerovatnoća da će vijek trajanja dijela biti najmanje 900 sati je 69%.
Ova vjerovatnoća se može dobiti pomoću MS Excel funkcije NORM.DIST (vrijednost integralne vrijednosti je 1):
P(X≥900) = 1 - P(X≤900) = 1 - NORM.DIST(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
O proračunima u MS Excelu - u jednom od narednih paragrafa ove lekcije.
Primjer 2 U određenom gradu prosječni godišnji prihod porodice je normalno raspoređena slučajna varijabla sa srednjom vrijednošću od 300 000 i standardnom devijacijom od 50 000. Poznato je da je prihod 40% porodica manji od vrijednosti A. Pronađite vrijednost A.
Rješenje. U ovom problemu, 40% nije ništa drugo do vjerovatnoća da će slučajna varijabla uzeti vrijednost iz otvorenog intervala koja je manja od određene vrijednosti, označene slovom A.
Da biste pronašli vrijednost A, prvo sastavljamo integralnu funkciju:
![]()
Prema zadatku
μ = 300000 - prosječna vrijednost;
σ = 50000 - standardna devijacija;
x = A je vrijednost koju treba pronaći.
Stvaranje jednakosti
![]() .
.
Prema statističkim tabelama, nalazimo da vjerovatnoća od 0,40 odgovara vrijednosti granice intervala z = −0,25 .
Dakle, pravimo jednakost
![]()
i pronađite njegovo rješenje:
A = 287300 .
Odgovor: prihodi 40% porodica su manji od 287300.
Zatvoreni interval
U mnogim problemima potrebno je pronaći vjerovatnoću da normalno raspoređena slučajna varijabla uzme vrijednost u intervalu od z 1 to z 2. Odnosno, pasti će u zatvoreni interval. Za rješavanje ovakvih problema potrebno je u tabeli pronaći vjerovatnoće koje odgovaraju granicama intervala, a zatim pronaći razliku između ovih vjerovatnoća. Ovo zahtijeva oduzimanje manje vrijednosti od veće. Primjeri za rješavanje ovih uobičajenih problema su sljedeći, a predlaže se da ih sami riješite i tada možete vidjeti tačna rješenja i odgovore.
Primjer 3 Dobit preduzeća za određeni period je slučajna varijabla koja podliježe normalnom zakonu raspodjele sa prosječnom vrijednošću od 0,5 miliona c.u. i standardnu devijaciju od 0,354. Odrediti, sa tačnošću od dvije decimale, vjerovatnoću da će dobit preduzeća biti od 0,4 do 0,6 c.u.
Primjer 4 Dužina proizvedenog dijela je slučajna varijabla raspoređena prema normalnom zakonu s parametrima μ =10 i σ =0,071 . Odrediti, sa tačnošću od dvije decimale, vjerovatnoću braka ako dozvoljene dimenzije dijela budu 10 ± 0,05.
Nagoveštaj: u ovom zadatku, pored pronalaženja verovatnoće da slučajna varijabla padne u zatvoreni interval (verovatnoća dobijanja neispravnog dela), potrebna je još jedna radnja.

omogućava vam da odredite vjerovatnoću da je standardizirana vrijednost Z ne manje -z i ne više +z, gdje z- proizvoljno odabrana vrijednost standardizirane slučajne varijable.
Približna metoda za provjeru normalnosti distribucije
Približna metoda za provjeru normalnosti distribucije vrijednosti uzorka zasniva se na sljedećem svojstvo normalne distribucije: nakrivljenost β 1 i koeficijent ekscesa β 2 nula.
Koeficijent asimetrije β 1 numerički karakteriše simetriju empirijske distribucije u odnosu na srednju vrednost. Ako je asimetrija nula, tada su aritmetrijska sredina, medijan i mod jednaki: a krivulja gustine raspodjele je simetrična u odnosu na srednju vrijednost. Ako je koeficijent asimetrije manji od nule (β 1 < 0 ), tada je aritmetička sredina manja od medijane, a medijana je, zauzvrat, manja od moda () i kriva je pomaknuta udesno (u poređenju sa normalnom distribucijom). Ako je koeficijent asimetrije veći od nule (β 1 > 0 ), tada je aritmetička sredina veća od medijane, a medijana je, zauzvrat, veća od moda () i kriva je pomaknuta ulijevo (u poređenju sa normalnom distribucijom).
Kurtosis koeficijent β 2 karakterizira koncentraciju empirijske distribucije oko aritmetičke sredine u smjeru ose Oy i stepen vrhunca krivulje gustine distribucije. Ako je koeficijent kurtosis veći od nule, tada je kriva više izdužena (u poređenju s normalnom distribucijom) duž ose Oy(grafikon je šiljatiji). Ako je koeficijent kurtosis manji od nule, tada je kriva spljoštenija (u poređenju sa normalnom distribucijom) duž ose Oy(grafikon je tupiviji).
Koeficijent zakrivljenosti se može izračunati korištenjem MS Excel funkcije SKRS. Ako provjeravate jedan niz podataka, tada morate unijeti raspon podataka u jedno polje "Broj".

Koeficijent ekscesa može se izračunati korištenjem MS Excel funkcije kurtosis. Prilikom provjere jednog niza podataka dovoljno je upisati i raspon podataka u jedno polje "Broj".

Dakle, kao što već znamo, sa normalnom distribucijom, koeficijenti asimetrije i kurtozisa jednaki su nuli. Ali šta ako imamo koeficijente asimetrije jednake -0,14, 0,22, 0,43 i koeficijente kurtosis jednake 0,17, -0,31, 0,55? Pitanje je sasvim pošteno, jer u praksi imamo posla samo s približnim, selektivnim vrijednostima asimetrije i ekscesa, koji su podložni nekom neizbježnom, nekontroliranom raspršenju. Stoga je nemoguće zahtijevati striktnu jednakost ovih koeficijenata na nulu, oni bi trebali biti samo dovoljno blizu nuli. Ali šta znači dovoljno?
Potrebno je uporediti primljene empirijske vrijednosti sa dozvoljenim vrijednostima. Da biste to učinili, trebate provjeriti sljedeće nejednakosti (uporedite vrijednosti koeficijenata po modulu sa kritičnim vrijednostima - granicama područja testiranja hipoteze).
Za koeficijent asimetrije β 1 .
Zakon normalne distribucije je najčešći u praksi. Glavna karakteristika koja ga razlikuje od drugih zakona je da je to ograničavajući zakon, kojem se drugi zakoni distribucije približavaju pod vrlo često tipičnim uslovima.
Definicija. Kontinuirana slučajna varijabla X ima normalan zakon distribucija(Gaussov zakon )sa parametrima a i σ 2 ako je njegova gustina vjerovatnoće f(x) ima oblik:
| . | (6.19) |
Kriva normalne distribucije se naziva normalno ili gausova kriva. Na sl. 6.5 a), b) prikazuje normalnu krivu s parametrima ali I σ2 i graf funkcije distribucije.
 Imajte na umu da je normalna kriva simetrična u odnosu na pravu liniju. X = ali, ima maksimum u tački X = ali, jednako , i dvije točke pregiba X = ali σ
sa ordinatama.
Imajte na umu da je normalna kriva simetrična u odnosu na pravu liniju. X = ali, ima maksimum u tački X = ali, jednako , i dvije točke pregiba X = ali σ
sa ordinatama.
Može se vidjeti da su u izrazu za gustinu normalnog zakona parametri raspodjele označeni slovima ali I σ2, što smo označili kao matematičko očekivanje i varijansu. Takva koincidencija nije slučajna. Razmotrimo teoremu koja utvrđuje vjerovatnoća značenja parametara normalnog zakona.
Teorema. Matematičko očekivanje slučajne varijable X distribuirane prema normalnom zakonu jednako je parametru a ove distribucije, tj.
| M(X) = ali, | (6.20) |
i njegovu varijansu prema parametru σ 2, tj.
| D(X) = σ2. | (6.21) |
Saznajte kako će se normalna kriva promijeniti prilikom promjene parametara ali I σ .
Ako σ = const, a parametar se mijenja a (ali 1 < ali 2 < ali 3), tj. centar simetrije distribucije, tada će se normalna kriva pomjeriti duž x-ose bez promjene oblika (slika 6.6).

Rice. 6.6

Rice. 6.7
Ako ali= const i parametar se mijenja σ , tada se mijenja ordinata maksimuma krive fmax(a) = . Sa povećanjem σ ordinata maksimuma se smanjuje, ali pošto površina ispod bilo koje krivulje raspodjele mora ostati jednaka jedinici, kriva postaje ravnija, protežući se duž x-ose. Kada se smanjuje σ , naprotiv, normalna kriva se proteže prema gore, istovremeno se skupljajući sa strane (slika 6.7).
Dakle, parametar a karakterizira poziciju i parametar σ je oblik normalne krive.
Normalna distribucija slučajne varijable sa parametrima a= 0 i σ = 1 se poziva standard ili normalizovano, a odgovarajuća normalna kriva je standard ili normalizovano.
Teškoća direktnog pronalaženja funkcije distribucije slučajne varijable distribuirane prema normalnom zakonu je zbog činjenice da se integral normalne funkcije distribucije ne može izraziti u terminima elementarnih funkcija. Međutim, može se izračunati pomoću posebne funkcije koja izražava određeni integral izraza ili . Takva funkcija se zove Laplaceova funkcija, za to su sastavljene tabele. Postoje mnoge varijacije ove funkcije, na primjer:
![]() ,
, ![]() .
.
Koristićemo funkciju
Razmotrite svojstva slučajne varijable distribuirane prema normalnom zakonu.
1. Vjerovatnoća da slučajna varijabla X, raspoređena prema normalnom zakonu, padne u interval [α , β ] je jednako sa
Koristeći ovu formulu, izračunavamo vjerovatnoće za različite vrijednosti δ (pomoću tablice vrijednosti Laplaceove funkcije):
at δ = σ = 2F(1) = 0,6827;
at δ = 2σ = 2F(2) = 0,9545;
at δ = 3σ = 2F(3) = 0,9973.
Ovdje se pojavljuje tzv. tri sigma pravilo»:
Ako slučajna varijabla X ima zakon normalne distribucije sa parametrima a i σ, onda je praktički sigurno da su njene vrijednosti u intervalu(a – 3σ ; a + 3σ ).
Primjer 6.3. Pod pretpostavkom da je visina muškaraca određene starosne grupe normalno raspoređena slučajna varijabla X sa parametrima ali= 173 i σ 2 = 36, nađi:
1. Izraz gustoće vjerovatnoće i funkcije raspodjele slučajne varijable X;
2. Udio odijela 4. visine (176 - 183 cm) i udio odijela 3. visine (170 - 176 cm), koji se moraju predvidjeti u ukupnoj proizvodnji za ovu starosnu grupu;
3. Formulirajte "pravilo tri sigme" za slučajnu varijablu X.
1. Pronalaženje gustine vjerovatnoće
![]()
i funkcija distribucije slučajne varijable X
![]() = .
= .
2. Proporcija odijela 4. visine (176 - 182 cm) nalazi se kao vjerovatnoća
R(176 ≤ X ≤ 182) = ![]() = F(1,5) – F(0,5).
= F(1,5) – F(0,5).
Prema tablici vrijednosti Laplaceove funkcije ( Aneks 2) mi nalazimo:
F(1,5) = 0,4332, F(0,5) = 0,1915.
Konačno dobijamo
R(176 ≤ X ≤ 182) = 0,4332 – 0,1915 = 0,2417.
Na sličan način se može naći i udio odijela 3. visine (170 - 176 cm). Međutim, to je lakše učiniti ako uzmemo u obzir da je ovaj interval simetričan u odnosu na matematičko očekivanje ali= 173, tj. nejednakost 170 ≤ X≤ 176 je ekvivalentno nejednakosti │ X– 173│≤ 3. Zatim
R(170 ≤X ≤176) = R(│X– 173│≤ 3) = 2F(3/6) = 2F(0,5) = 2 0,1915 = 0,3830.
3. Formulirajmo "pravilo tri sigme" za slučajnu varijablu X:
Gotovo je sigurno da se rast muškaraca ove starosne grupe nalazi u granicama ali – 3σ = 173 - 3 6 = 155 do ali + 3σ = 173 + 3 6 = 191, tj. 155 ≤ X ≤ 191. ◄
7. GRANIČNE TEOREME TEORIJE VEROVATNOĆA
Kao što je već spomenuto u proučavanju slučajnih varijabli, nemoguće je unaprijed predvidjeti koju će vrijednost slučajna varijabla uzeti kao rezultat jednog testa - to ovisi o mnogim razlozima koji se ne mogu uzeti u obzir.
Međutim, s ponovljenim ponavljanjem testova, ponašanje zbira slučajnih varijabli gotovo gubi svoj slučajni karakter i postaje redovno. Prisustvo obrazaca povezano je upravo sa masovnom prirodom fenomena koji u svojoj ukupnosti generišu slučajnu varijablu podložnu dobro definisanom zakonu. Suština stabilnosti masovnih pojava je sljedeća: specifičnosti svake pojedinačne slučajne pojave nemaju gotovo nikakav utjecaj na prosječan rezultat mase takvih pojava; slučajna odstupanja od proseka, neizbežna u svakoj pojedinačnoj pojavi, u masi se međusobno poništavaju, izravnavaju, izravnavaju.
Upravo ta stabilnost prosjeka je fizički sadržaj "zakona velikih brojeva", shvaćenog u širem smislu riječi: s vrlo velikim brojem slučajnih pojava, njihov rezultat praktično prestaje biti slučajan i može se predvidjeti s visok stepen sigurnosti.
U užem smislu riječi, "zakon velikih brojeva" u teoriji vjerovatnoće podrazumijeva se kao niz matematičkih teorema, u svakoj od kojih je, za određene uvjete, činjenica aproksimacije prosječnih karakteristika velikog broja eksperimenata. na neke specifične konstante se uspostavlja.
Zakon velikih brojeva igra važnu ulogu u praktičnoj primjeni teorije vjerovatnoće. Svojstvo slučajnih varijabli pod određenim uslovima da se ponašaju praktično kao neslučajne omogućava nam da pouzdano operišemo sa ovim veličinama, da predvidimo rezultate masovnih slučajnih pojava sa skoro potpunom sigurnošću.
Mogućnosti ovakvih predviđanja u oblasti slučajnih pojava mase dodatno su proširene prisustvom još jedne grupe graničnih teorema, koje se više ne odnose na granične vrednosti slučajnih varijabli, već na zakone granične distribucije. Ovo je grupa teorema poznatih kao "teorema središnje granice". Različiti oblici centralne granične teoreme razlikuju se jedni od drugih po uslovima za koje se uspostavlja ovo granično svojstvo zbira slučajnih varijabli.
Različiti oblici zakona velikih brojeva sa različitim oblicima središnje granične teoreme čine skup tzv. granične teoreme teorija vjerovatnoće. Granične teoreme omogućavaju ne samo da se prave naučne prognoze u oblasti slučajnih pojava, već i da se proceni tačnost ovih prognoza.
Slučajna varijabla se poziva raspoređeni prema normalnom (Gaussovom) zakonu s parametrima ali i () , ako gustina distribucije vjerovatnoće ima oblik
Vrijednost distribuirana prema normalnom zakonu uvijek ima beskonačan broj mogućih vrijednosti, pa je zgodno prikazati je grafički, koristeći graf gustine distribucije. Prema formuli
vjerovatnoća da će slučajna varijabla uzeti vrijednost iz intervala jednaka je površini ispod grafika funkcije na ovom intervalu (geometrijsko značenje određenog integrala). Funkcija koja se razmatra je nenegativna i kontinuirana. Graf funkcije ima oblik zvona i naziva se Gausova kriva ili normalna kriva.
Na slici je prikazano nekoliko krivulja gustine distribucije slučajne varijable određene prema normalnom zakonu.
Sve krive imaju jednu maksimalnu tačku, od koje se krive smanjuju udesno i ulijevo. Maksimum je postignut na i jednak je .
Krive su simetrične u odnosu na vertikalnu pravu liniju povučenu kroz najvišu tačku. Površina podgrafa svake krive je 1.
Razlika između pojedinačnih krivulja distribucije je samo u činjenici da je ukupna površina podgrafa, koja je ista za sve krive, raspoređena na različite načine između različitih sekcija. Glavni dio područja podgrafa bilo koje krive koncentriran je u neposrednoj blizini najvjerovatnije vrijednosti, a ova vrijednost je različita za sve tri krive. Za različite vrijednosti i ali dobijaju se različiti normalni zakoni i različiti grafovi gustine funkcije raspodele.
Teorijske studije su pokazale da većina slučajnih varijabli koje se susreću u praksi ima normalan zakon raspodjele. Prema ovom zakonu distribuiraju se brzina molekula plina, težina novorođenčadi, veličina odjeće i obuće stanovništva zemlje i mnogi drugi slučajni događaji fizičke i biološke prirode. Po prvi put je ovaj obrazac uočio i teorijski potkrijepio A. De Moivre.
Za , funkcija se poklapa s funkcijom , o kojoj je već bilo riječi u lokalnoj graničnoj teoremi Moivre–Laplacea. Gustoća vjerovatnoće normalne distribucije je laka izraženo kroz:
Za takve vrijednosti parametara naziva se normalni zakon main .
Poziva se funkcija raspodjele za normaliziranu gustoću Laplaceova funkcija i označeno Φ(x). Takođe smo se već susreli sa ovom funkcijom.
Laplaceova funkcija ne ovisi o specifičnim parametrima ali i σ. Za Laplaceovu funkciju, koristeći približne metode integracije, sastavljene su tablice vrijednosti na intervalu s različitim stupnjevima točnosti. Očigledno je da je Laplaceova funkcija neparna, stoga nema potrebe stavljati njene vrijednosti u tablicu za negativne .
Za slučajnu varijablu distribuiranu prema normalnom zakonu s parametrima ali i , matematičko očekivanje i varijansa se izračunavaju po formulama: , , Standardna devijacija je jednaka .
Vjerovatnoća da normalno raspoređena veličina uzme vrijednost iz intervala je jednaka
gdje je Laplaceova funkcija uvedena u integralnu graničnu teoremu.
Često je u problemima potrebno izračunati vjerovatnoću da je devijacija normalno raspoređene slučajne varijable X od svog matematičkog očekivanja u apsolutnoj vrijednosti ne prelazi neku vrijednost , tj. izračunaj vjerovatnoću. Primjenom formule (19.2) imamo:
U zaključku predstavljamo jednu važnu posljedicu formule (19.3). Ubacimo ovu formulu. Tada, tj. vjerovatnoća da je apsolutna vrijednost odstupanja X od svog matematičkog očekivanja neće premašiti , jednako 99,73%. U praksi se takav događaj može smatrati pouzdanim. Ovo je suština pravila tri sigma.
Pravilo tri sigma. Ako je slučajna varijabla normalno raspoređena, tada apsolutna vrijednost njenog odstupanja od matematičkog očekivanja praktično ne prelazi tri puta standardnu devijaciju.
U članku je detaljno prikazano što je normalni zakon raspodjele slučajne varijable i kako ga koristiti u rješavanju praktičnih problema.
Normalna distribucija u statistici
Istorija zakona ima 300 godina. Prvi otkrivač bio je Abraham de Moivre, koji je došao do aproksimacije još 1733. godine. Mnogo godina kasnije, Carl Friedrich Gauss (1809) i Pierre-Simon Laplace (1812) izveli su matematičke funkcije.
Laplas je takođe otkrio izuzetnu pravilnost i formulisao centralna granična teorema (CPT), prema kojem zbir velikog broja malih i nezavisnih varijabli ima normalnu distribuciju.
Normalni zakon nije fiksna jednadžba o tome kako jedna varijabla ovisi o drugoj. Fiksna je samo priroda ove zavisnosti. Specifičan oblik distribucije određen je posebnim parametrima. Na primjer, y = ax + b je jednačina prave linije. Međutim, gdje tačno prolazi i pod kojim nagibom određuje se parametrima ali I b. Isto je i sa normalnom distribucijom. Jasno je da se radi o funkciji koja opisuje tendenciju visoke koncentracije vrijednosti u blizini centra, ali njen tačan oblik daju posebni parametri.
Gausova kriva normalne raspodjele ima sljedeći oblik.
Grafikon normalne distribucije podsjeća na zvono, tako da možete vidjeti ime zvonasta kriva. Grafikon ima "grbu" u sredini i naglo smanjenje gustine na rubovima. Ovo je suština normalne distribucije. Vjerovatnoća da će se slučajna varijabla nalaziti blizu centra je mnogo veća nego da će jako odstupiti od sredine.

Slika iznad prikazuje dvije oblasti ispod Gaussove krive: plavo i zeleno. Osnovi, tj. intervali su jednaki u oba dijela. Ali visine su primjetno različite. Plava oblast je udaljena od centra i ima znatno nižu visinu od zelene koja se nalazi u samom centru distribucije. Shodno tome, razlikuju se i površine, odnosno vjerovatnoće pada u naznačene intervale.
Formula za normalnu distribuciju (gustinu) je sljedeća.
![]()
Formula se sastoji od dvije matematičke konstante:
π – broj pi 3.142;
e– osnova prirodnog logaritma 2,718;
dva promjenjiva parametra koji definiraju oblik određene krive:
m– matematičko očekivanje (druge oznake se mogu koristiti u različitim izvorima, na primjer, µ ili a);
σ2– disperzija;
pa, sama varijabla x, za koji se izračunava gustina vjerovatnoće.
Specifičan oblik normalne distribucije zavisi od 2 parametra: ( m) I ( σ2). Ukratko označeno N(m, σ 2) ili N(m, σ). Parametar m(Očekivanje) određuje distributivni centar, koji odgovara maksimalnoj visini grafa. Disperzija σ2 karakterizira raspon varijacija, odnosno "razmazanost" podataka.
Parametar matematičkog očekivanja pomiče centar distribucije udesno ili ulijevo bez utjecaja na sam oblik krivulje gustoće.

Ali disperzija određuje oštrinu krivulje. Kada podaci imaju malo širenje, tada je sva njegova masa koncentrisana u centru. Ako podaci imaju veliko širenje, onda su „razmazani“ u širokom rasponu.

Gustina distribucije nema direktnu praktičnu primjenu. Da biste izračunali vjerovatnoće, morate integrirati funkciju gustoće.
Vjerovatnoća da će slučajna varijabla biti manja od neke vrijednosti x, utvrđuje se normalna funkcija distribucije:
Koristeći matematička svojstva bilo koje kontinuirane distribucije, nije teško izračunati bilo koje druge vjerovatnoće, jer
P(a ≤ X< b) = Ф(b) – Ф(a)
standardna normalna distribucija
Normalna distribucija zavisi od parametara srednje vrednosti i varijanse, zbog čega su njena svojstva slabo vidljiva. Bilo bi dobro imati neki standard distribucije koji ne zavisi od obima podataka. I on postoji. pozvao standardna normalna distribucija. Zapravo, ovo je uobičajena normalna normalna distribucija, samo sa parametrima matematičkog očekivanja 0, a varijansa je 1, kratko napisano N(0, 1).
Svaka normalna distribucija može se lako pretvoriti u standardnu distribuciju normalizacijom:
gdje z je nova varijabla koja se koristi umjesto x;
m- očekivana vrijednost;
σ
- standardna devijacija.
Za uzorke podataka uzimaju se procjene:
Aritmetička sredina i varijansa nove varijable z su sada takođe jednake 0 i 1, respektivno. To je lako provjeriti uz pomoć elementarnih algebarskih transformacija.
Ime se pojavljuje u literaturi z-score. To je to - normalizovani podaci. Z-score može se direktno uporediti sa teorijskim vjerovatnoćama, jer njegova skala odgovara standardu.
Sada da vidimo kako izgleda gustina standardne normalne distribucije (za z-rezultati). Da vas podsjetim da Gaussova funkcija ima oblik:
![]()
Zamjena umjesto (x-m)/σ pismo z, ali umjesto toga σ - jedan, dobijamo funkcija gustine standardne normalne distribucije:
![]()
Grafikon gustine:

Centar je, kako se i očekivalo, u tački 0. U istoj tački Gaussova funkcija dostiže svoj maksimum, što odgovara slučajnoj varijabli koja uzima svoju prosječnu vrijednost (tj. x-m=0). Gustina u ovoj tački je 0,3989, što se može izračunati čak i u umu, jer. e 0 =1 i ostaje da se izračuna samo omjer od 1 prema korijenu od 2 pi.
Dakle, grafikon jasno pokazuje da vrijednosti koje imaju mala odstupanja od srednje vrijednosti ispadaju češće od drugih, a one koje su jako udaljene od centra su mnogo rjeđe. Skala apscisa se mjeri u standardnim devijacijama, što vam omogućava da se riješite mjernih jedinica i dobijete univerzalnu strukturu normalne distribucije. Gaussova kriva za normalizirane podatke savršeno demonstrira druga svojstva normalne distribucije. Na primjer, da je simetrična oko y-ose. Unutar ±1σ aritmetičke sredine koncentrisano je najviše svih vrijednosti (još uvijek procjenjujemo na oko). Većina podataka je unutar ±2σ. Gotovo svi podaci su unutar ±3σ. Posljednje svojstvo je opšte poznato kao tri sigma pravilo za normalnu distribuciju.
Standardna funkcija normalne distribucije omogućava vam da izračunate vjerovatnoće.
![]()
Naravno, niko ne broji rukom. Sve se izračunava i stavlja u posebne tabele, koje se nalaze na kraju svakog udžbenika statistike.
Tabela normalne distribucije
Tablice normalne distribucije su dvije vrste:
- sto gustina;
- sto funkcije(integral gustine).
sto gustina retko se koristi. Ipak, da vidimo kako to izgleda. Recimo da trebamo dobiti gustinu za z = 1, tj. gustina vrijednosti koja je 1 sigma udaljena od očekivane vrijednosti. Ispod je dio tabele.

U zavisnosti od organizacije podataka, tražimo željenu vrijednost po imenu kolone i reda. U našem primjeru uzimamo liniju 1,0 i kolona 0 , jer nema stotinki. Željena vrijednost je 0,2420 (0 prije 2420 je izostavljeno).
Gaussova funkcija je simetrična oko y-ose. Zbog toga φ(z)= φ(-z), tj. gustina za 1 je identična gustoći za -1 , što se jasno vidi na slici.

Kako ne bi gubili papir, tabele se štampaju samo za pozitivne vrijednosti.
U praksi se često koriste vrijednosti funkcije standardne normalne distribucije, odnosno vjerovatnoće za različite z.
Takve tabele također sadrže samo pozitivne vrijednosti. Stoga, da bi se razumjelo i pronašlo bilo koji potrebne vjerovatnoće treba da budu poznate svojstva standardne normalne distribucije.
Funkcija F(z) je simetričan u odnosu na svoju vrijednost od 0,5 (a ne y-os, kao gustina). Dakle, jednakost je tačna:
Ova činjenica je prikazana na slici:

Vrijednosti funkcije F(-z) I F(z) podijelite grafikon na 3 dijela. Štoviše, gornji i donji dijelovi su jednaki (označeni kvačicama). Da bi se upotpunila vjerovatnoća F(z) na 1, samo dodajte vrijednost koja nedostaje F(-z). Dobićete istu jednačinu kao gore.
Ako trebate pronaći vjerovatnoću pada u interval (0;z), odnosno vjerovatnoću odstupanja od nule u pozitivnom smjeru do određenog broja standardnih devijacija, dovoljno je od vrijednosti standardne normalne funkcije raspodjele oduzeti 0,5:

Radi jasnoće, možete pogledati sliku.

Na Gaussovoj krivulji, ista situacija izgleda kao područje od centra na desno do z.

Vrlo često analitičara zanima vjerovatnoća odstupanja u oba smjera od nule. A budući da je funkcija simetrična u odnosu na centar, prethodna formula se mora pomnožiti sa 2:

Slika ispod.

Pod Gaussovom krivom, ovo je središnji dio, ograničen odabranom vrijednošću -z lijevo i z desno.

Ova svojstva treba uzeti u obzir, jer vrijednosti tablice rijetko odgovaraju intervalu od interesa.
Da bi se olakšao zadatak, udžbenici obično objavljuju tabele za funkciju oblika:

Ako vam je potrebna vjerovatnoća odstupanja u oba smjera od nule, tada se, kao što smo upravo vidjeli, tabelarna vrijednost za ovu funkciju jednostavno množi sa 2.
Pogledajmo sada konkretne primjere. Ispod je tabela standardne normalne distribucije. Nađimo tabelarne vrijednosti za tri z: 1,64, 1,96 i 3.

Kako razumjeti značenje ovih brojeva? Počnimo sa z=1,64, za koji je vrijednost tablice 0,4495 . Najlakši način da se objasni značenje je na slici.

Odnosno, vjerovatnoća da standardizirana normalno distribuirana slučajna varijabla spada u interval od 0 prije 1,64 , je jednako 0,4495 . Prilikom rješavanja zadataka obično je potrebno izračunati vjerovatnoću odstupanja u oba smjera, pa vrijednost pomnožimo 0,4495 za 2 i dobijete otprilike 0,9. Zauzeta površina ispod Gaussove krive je prikazana ispod.

Dakle, 90% svih normalno raspoređenih vrijednosti spada u interval ±1,64σ iz aritmetičke sredine. Nisam slučajno izabrao značenje z=1,64, jer susjedstvo oko aritmetičke sredine, koje zauzima 90% ukupne površine, ponekad se koristi za izračunavanje intervala povjerenja. Ako provjerena vrijednost ne padne u naznačeno područje, tada je malo vjerojatna (samo 10%).
Za testiranje hipoteza, međutim, češće se koristi interval koji pokriva 95% svih vrijednosti. Pola šanse za 0,95 - ovo 0,4750 (pogledajte drugu označenu vrijednost u tabeli).

Za ovu vjerovatnoću z=1,96. One. unutar skoro ±2σ od prosjeka iznosi 95% vrijednosti. Samo 5% je izvan ovih granica.

Još jedna zanimljiva i često korištena vrijednost tablice odgovara z=3, jednak je prema našoj tabeli 0,4986 . Pomnožite sa 2 i dobijete 0,997 . Dakle, u okvirima ±3σ gotovo sve vrijednosti su uključene iz aritmetičke sredine.

Ovako izgleda pravilo 3 sigma za normalnu distribuciju na grafikonu.
Uz pomoć statističkih tabela možete dobiti bilo koju vjerovatnoću. Međutim, ova metoda je vrlo spora, nezgodna i vrlo zastarjela. Danas se sve radi na kompjuteru. Zatim prelazimo na praksu izračunavanja u Excelu.
Normalna distribucija u Excel-u
Excel ima nekoliko funkcija za izračunavanje vjerovatnoća ili recipročnih vrijednosti normalne distribucije.

NORM.S.DIST funkcija
Funkcija NORM.ST.DIST dizajniran za izračunavanje gustine ϕ(z) ili vjerovatnoće Φ(z) prema normalizovanim podacima ( z).
= NORM.ST.DIST(z, kumulativno)
z je vrijednost standardizirane varijable
integralni– ako je 0, tada se izračunava gustinaϕ(z) , ako je 1 vrijednost funkcije F(z), tj. vjerovatnoća P(Z
Izračunajte gustoću i vrijednost funkcije za razne z: -3, -2, -1, 0, 1, 2, 3(naznačićemo ih u ćeliji A2).
Da biste izračunali gustinu, potrebna vam je formula =NORM.ST.DIST(A2;0). Na dijagramu ispod, ovo je crvena tačka.
Za izračunavanje vrijednosti funkcije =NORM.ST.DIST(A2;1). Dijagram prikazuje zasjenjeno područje ispod normalne krive.

U stvarnosti, češće je potrebno izračunati vjerovatnoću da slučajna varijabla neće prijeći neke granice od srednje vrijednosti (u standardnim devijacijama koje odgovaraju varijabli z), tj. P(|Z|

Odredimo kolika je vjerovatnoća da će slučajna varijabla pasti unutar granica ±1z, ±2z i ±3z od nule. Potrebna formula 2F(z)-1, u Excelu =2*NORM.ST.DIST(A2;1)-1.

Dijagram jasno pokazuje glavna osnovna svojstva normalne distribucije, uključujući pravilo tri sigma. Funkcija NORM.ST.DIST je automatska tabela vrijednosti normalne funkcije distribucije u Excelu.
Može postojati i inverzni problem: prema dostupnoj vjerovatnoći P(Z
NORM.ST.INV funkcija
NORM.ST.INV izračunava recipročnu vrijednost standardne normalne funkcije distribucije. Sintaksa se sastoji od jednog parametra:
=NORM.S.OBR(vjerovatnoća)
vjerovatnoća je vjerovatnoća.
Ova formula se koristi jednako često kao i prethodna, jer iste tabele moraju tražiti ne samo vjerovatnoće, već i kvantile.

Na primjer, prilikom izračunavanja intervala povjerenja navodi se vjerovatnoća povjerenja prema kojoj je potrebno izračunati vrijednost z.

S obzirom da se interval povjerenja sastoji od gornje i donje granice i da je normalna raspodjela simetrična oko nule, dovoljno je dobiti gornju granicu (pozitivno odstupanje). Donja granica se uzima sa negativnim predznakom. Označimo vjerovatnoću povjerenja kao γ (gama), tada se gornja granica intervala pouzdanosti izračunava pomoću sljedeće formule.
![]()
Izračunajte vrijednosti u Excelu z(što odgovara odstupanju od srednje vrijednosti u sigmama) za nekoliko vjerovatnoća, uključujući i one koje svaki statističar zna napamet: 90%, 95% i 99%. U ćeliju B2 unesite formulu: =NORM.ST.OBR((1+A2)/2). Promjenom vrijednosti varijable (vjerovatnosti u ćeliji A2) dobijamo različite granice intervala.

Interval pouzdanosti za 95% je 1,96, što je skoro 2 standardne devijacije. Odavde je čak i u mislima lako procijeniti moguće širenje normalne slučajne varijable. Općenito, intervali povjerenja od 90%, 95% i 99% odgovaraju ±1,64, ±1,96 i ±2,58 σ intervalima povjerenja.
Općenito, funkcije NORM.ST.DIST i NORM.ST.OBR vam omogućavaju da izvršite bilo koji proračun koji se odnosi na normalnu distribuciju. Ali da bi stvari bile lakše i manje radile, Excel ima još nekoliko funkcija. Na primjer, da biste izračunali intervale povjerenja za srednju vrijednost, možete koristiti CONFID.NORM. Za provjeru aritmetičke sredine postoji formula Z.TEST.
Razmotrite još nekoliko korisnih formula s primjerima.
NORM.DIST funkcija
Funkcija NORM.DIST razlikuje se od NORM.ST.DIST samo činjenicom da se koristi za obradu podataka bilo koje skale, a ne samo normalizovanih. Parametri normalne distribucije navedeni su u sintaksi.
=NORM.DIST(x, srednja vrijednost, standard_dev, kumulativno)
prosječna je matematičko očekivanje koje se koristi kao prvi parametar modela normalne distribucije
standard_off– standardna devijacija – drugi parametar modela
integralni- ako je 0, onda se izračunava gustina, ako je 1 - onda vrijednost funkcije, tj. P(X
Na primjer, gustina za vrijednost 15, koja je izvučena iz normalnog uzorka sa srednjom 10, standardnom devijacijom 3, izračunava se na sljedeći način:

Ako je zadnji parametar postavljen na 1, tada dobijamo vjerovatnoću da će normalna slučajna varijabla biti manja od 15 za date parametre distribucije. Stoga se vjerovatnoće mogu izračunati direktno iz originalnih podataka.
NORM.INV funkcija
Ovo je kvantil normalne distribucije, tj. vrijednost inverzne funkcije. Sintaksa je sljedeća.
=NORM.INV(vjerovatnoća, srednja vrijednost, standardna devijacija)
vjerovatnoća- vjerovatnoća
prosječna– očekivanje
standard_off- standardna devijacija
Svrha je ista kao NORM.ST.INV, samo funkcija radi s podacima bilo koje skale.
Primjer je prikazan u videu na kraju članka.
Modeliranje normalne distribucije
Neki zadaci zahtijevaju generiranje normalnih slučajnih brojeva. Ne postoji gotova funkcija za ovo. Međutim, Excel ima dvije funkcije koje vraćaju slučajne brojeve: RANDOMBETWEEN I RAND. Prvi proizvodi nasumične ravnomjerno raspoređene cijele brojeve unutar specificiranih granica. Druga funkcija generiše ravnomjerno raspoređene slučajne brojeve između 0 i 1. Da biste napravili umjetni uzorak s bilo kojom datom distribucijom, potrebna vam je funkcija RAND.
Pretpostavimo da je za eksperiment potrebno dobiti uzorak iz normalno raspoređene opće populacije sa srednjom vrijednosti 10 i standardnom devijacijom 3. Za jednu slučajnu vrijednost napisaćemo formulu u Excelu.
NORM.INV(RAND();10;3)
Proširimo ga na potreban broj ćelija i normalna selekcija je spremna.
Za modeliranje standardiziranih podataka trebate koristiti NORM.ST.OBR.
Proces pretvaranja uniformnih brojeva u normalne brojeve može se prikazati na sljedećem dijagramu. Iz uniformnih vjerovatnoća koje su generirane RAND formulom, horizontalne linije se povlače na graf normalne funkcije distribucije. Zatim se projekcije na horizontalnu osu spuštaju iz tačaka preseka verovatnoća sa grafikom.