Wahrscheinlichkeit einer normalverteilten Zufallsvariablen. Normales Wahrfür eine kontinuierliche Zufallsvariable. Beziehung zu anderen Distributionen
Ersetzen φ(x)=π /4 ,f(x)=1/(b-a)
D[π /4]=( /720) ).
№319 Würfelkante X ungefähr gemessen, und A . Betrachten Sie die Kante eines Würfels als Zufallsvariable X, die gleichmäßig im Intervall (a, b) verteilt ist, und ermitteln Sie den mathematischen Erwartungswert und die Varianz des Volumens des Würfels.
1. Finden wir den mathematischen Erwartungswert für die Fläche eines Kreises – eine Zufallsvariable Y=φ(K)= - nach der Formel
M[φ(X)]= ![]()
Durch Platzieren φ(x)= ,f(x)=1/(b-a) und Integration durchführen, erhalten wir
M( )=
 .
.
2. Ermitteln Sie die Streuung der Fläche eines Kreises mithilfe der Formel
D [φ(X)]= ![]() -
-
![]() .
.
Ersetzen φ(x)= ,f(x)=1/(b-a) und Integration durchführen, erhalten wir
D =
 .
.
№320 Zufallsvariablen X und Y sind unabhängig und gleichmäßig verteilt: X im Intervall (a,b), Y im Intervall (c,d). Finden Sie den mathematischen Erwartungswert des Produkts XY.
Der mathematische Erwartungswert des Produkts unabhängiger Zufallsvariablen ist gleich dem Produkt ihrer mathematischen Erwartungen, d.h.
M(XY)= 
№321 Zufallsvariablen X und Y sind unabhängig und gleichmäßig verteilt: X im Intervall (a,b), Y im Intervall (c,d). Finden Sie die Varianz des Produkts XY.
Verwenden wir die Formel
D(XY)=M[
Die mathematische Erwartung des Produkts unabhängiger Zufallsvariablen ist daher gleich dem Produkt ihrer mathematischen Erwartungen
Finden wir M mithilfe der Formel
M[φ(X)]= ![]()
Ersetzen φ(x)= ,f(x)=1/(b-a) und Integration durchführen, erhalten wir
M (**)
Wir können ähnlich finden
M (***)
Ersetzen M(X)=(a+b)/2, M(Y)=(c+d)/2 sowie (***) und (**) in (*) erhalten wir schließlich
D(XY)= -[
![]() .
.
№322 Der mathematische Erwartungswert einer normalverteilten Zufallsvariablen X ist a=3 und die Standardabweichung σ=2. Schreiben Sie die Wahrscheinlichkeitsdichte von X.
Verwenden wir die Formel:
f(x)=  .
.
Wenn wir die verfügbaren Werte ersetzen, erhalten wir:
f(x)=  =f(x)=
=f(x)=  .
.
№323 Schreiben Sie die Wahrscheinlichkeitsdichte einer normalverteilten Zufallsvariablen X, wobei Sie wissen, dass M(X)=3, D(X)=16.
Verwenden wir die Formel:
f(x)= .
Um den Wert von σ zu ermitteln, verwenden wir die Eigenschaft der Standardabweichung einer Zufallsvariablen X gleich der Quadratwurzel seiner Varianz. Daher ist σ=4, M(X)=a=3. Durch Einsetzen in die Formel erhalten wir
f(x)=  =
=
 .
.
№324 Eine normalverteilte Zufallsvariable X ist durch die Dichte gegeben
f(x)= ![]() .
Finden Sie den mathematischen Erwartungswert und die Varianz von X.
.
Finden Sie den mathematischen Erwartungswert und die Varianz von X.
Verwenden wir die Formel
f(x)= ,
Wo A-erwarteter Wert, σ - Standardabweichung X. Aus dieser Formel folgt das a=M(X)=1. Um die Varianz zu ermitteln, verwenden wir die Eigenschaft, dass es sich um die Standardabweichung einer Zufallsvariablen handelt X gleich der Quadratwurzel seiner Varianz. Somit D(X)= =
Antwort: Der mathematische Erwartungswert ist 1; die Varianz beträgt 25.
Bondarchuk Rodion
Gegeben sei die Verteilungsfunktion des normalisierten Normalgesetzes ![]() . Finden Sie die Verteilungsdichte f(x).
. Finden Sie die Verteilungsdichte f(x).
Wissend, dass ![]() , finde f(x).
, finde f(x).

Antwort: ![]()
Beweisen Sie, dass die Laplace-Funktion gilt ![]() . seltsam:
. seltsam: ![]() .
.

Wir sorgen für Ersatz


Wir führen die umgekehrte Substitution durch und erhalten:
![]() =
= ![]() =
=


Es wird auch Probleme geben, die Sie selbst lösen müssen und auf die Sie die Antworten sehen können.
Normalverteilung: theoretische Grundlagen
Beispiele für nach einem Normalgesetz verteilte Zufallsvariablen sind die Körpergröße eines Menschen und die Masse gefangener Fische derselben Art. Normalverteilung bedeutet Folgendes : Es gibt Werte der menschlichen Körpergröße, der Masse von Fischen derselben Art, die intuitiv als „normal“ (und tatsächlich gemittelt) wahrgenommen werden und in einer ausreichend großen Stichprobe viel häufiger vorkommen als solche nach oben oder unten unterscheiden.
Die normale Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen (manchmal eine Gaußsche Verteilung) kann als glockenförmig bezeichnet werden, da die Dichtefunktion dieser Verteilung, symmetrisch zum Mittelwert, dem Schnitt einer Glocke (rote Kurve) sehr ähnlich ist in der Abbildung oben).
Die Wahrscheinlichkeit, in einer Stichprobe auf bestimmte Werte zu stoßen, ist gleich der Fläche der Figur unter der Kurve, und im Fall einer Normalverteilung sehen wir die unter der Spitze der „Glocke“, die den Werten entspricht Im Durchschnitt ist die Fläche und damit die Wahrscheinlichkeit größer als unter den Kanten. Somit erhalten wir das Gleiche, was bereits gesagt wurde: Die Wahrscheinlichkeit, einer Person mit „normaler“ Größe zu begegnen und einen Fisch mit „normalem“ Gewicht zu fangen, ist höher als bei Werten, die nach oben oder unten abweichen. In vielen praktischen Fällen verteilen sich Messfehler nach einem Gesetz, das dem Normalen nahekommt.
Schauen wir uns noch einmal die Abbildung am Anfang der Lektion an, die die Dichtefunktion einer Normalverteilung zeigt. Der Graph dieser Funktion wurde durch Berechnung einer bestimmten Datenprobe im Softwarepaket erhalten STATISTIK. Darauf stellen die Histogrammspalten Intervalle von Stichprobenwerten dar, deren Verteilung dem tatsächlichen Diagramm der Normalverteilungsdichtefunktion, einer roten Kurve, nahe kommt (oder sich, wie in der Statistik allgemein gesagt wird, nicht wesentlich davon unterscheidet). . Die Grafik zeigt, dass diese Kurve tatsächlich glockenförmig ist.
Die Normalverteilung ist in vielerlei Hinsicht wertvoll, denn wenn Sie nur den erwarteten Wert einer kontinuierlichen Zufallsvariablen und ihre Standardabweichung kennen, können Sie jede mit dieser Variablen verbundene Wahrscheinlichkeit berechnen.
Die Normalverteilung hat außerdem den Vorteil, dass sie eine der am einfachsten zu verwendenden ist. Statistische Tests zum Testen statistischer Hypothesen – Student-T-Test- kann nur verwendet werden, wenn die Stichprobendaten dem Normalverteilungsgesetz entsprechen.
Dichtefunktion der Normalverteilung einer kontinuierlichen Zufallsvariablen kann mit der Formel ermittelt werden:
 ,
,
Wo X- Wert der sich ändernden Größe, - Durchschnittswert, - Standardabweichung, e=2,71828... - die Basis des natürlichen Logarithmus, =3,1416...
Eigenschaften der Normalverteilungsdichtefunktion
Änderungen im Mittelwert verschieben die normale Dichtefunktionskurve in Richtung der Achse Ochse. Wenn sie zunimmt, bewegt sich die Kurve nach rechts, wenn sie abnimmt, dann nach links.
Wenn sich die Standardabweichung ändert, ändert sich auch die Höhe des oberen Endes der Kurve. Wenn die Standardabweichung zunimmt, ist die Spitze der Kurve höher, und wenn sie abnimmt, ist sie niedriger.
Wahrscheinlichkeit dafür, dass eine normalverteilte Zufallsvariable in ein bestimmtes Intervall fällt
Bereits in diesem Absatz beginnen wir mit der Lösung praktischer Probleme, deren Bedeutung im Titel angegeben ist. Schauen wir uns an, welche Möglichkeiten die Theorie zur Lösung von Problemen bietet. Das Ausgangskonzept zur Berechnung der Wahrscheinlichkeit, dass eine normalverteilte Zufallsvariable in ein bestimmtes Intervall fällt, ist die kumulative Funktion der Normalverteilung.
Kumulative Normalverteilungsfunktion:
 .
.
Allerdings ist es problematisch, Tabellen für jede mögliche Kombination aus Mittelwert und Standardabweichung zu erhalten. Daher besteht eine der einfachen Möglichkeiten zur Berechnung der Wahrscheinlichkeit, dass eine normalverteilte Zufallsvariable in ein bestimmtes Intervall fällt, darin, Wahrscheinlichkeitstabellen für die standardisierte Normalverteilung zu verwenden.
Eine Normalverteilung wird als standardisiert oder normalisiert bezeichnet., dessen Mittelwert ist, und die Standardabweichung ist.
Standardisierte Normalverteilungsdichtefunktion:
![]() .
.
Kumulative Funktion der standardisierten Normalverteilung:
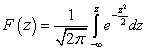 .
.
Die folgende Abbildung zeigt die Integralfunktion der standardisierten Normalverteilung, deren Diagramm durch Berechnung einer bestimmten Datenstichprobe im Softwarepaket erhalten wurde STATISTIK. Das Diagramm selbst ist eine rote Kurve, und die Beispielwerte nähern sich dieser an.

Um das Bild zu vergrößern, können Sie mit der linken Maustaste darauf klicken.
Die Standardisierung einer Zufallsvariablen bedeutet, von den ursprünglich in der Aufgabe verwendeten Einheiten zu standardisierten Einheiten überzugehen. Die Standardisierung erfolgt nach der Formel
In der Praxis sind häufig alle möglichen Werte einer Zufallsvariablen unbekannt, sodass die Werte des Mittelwerts und der Standardabweichung nicht genau bestimmt werden können. Sie werden durch das arithmetische Mittel der Beobachtungen und die Standardabweichung ersetzt S. Größe z drückt die Abweichungen der Werte einer Zufallsvariablen vom arithmetischen Mittel bei der Messung von Standardabweichungen aus.
Offenes Intervall
Die Wahrscheinlichkeitstabelle für die standardisierte Normalverteilung, die in fast jedem Statistikbuch zu finden ist, enthält die Wahrscheinlichkeiten, dass eine Zufallsvariable eine Standardnormalverteilung hat Z nimmt einen Wert an, der kleiner als eine bestimmte Zahl ist z. Das heißt, es wird in das offene Intervall von minus unendlich bis fallen z. Zum Beispiel die Wahrscheinlichkeit, dass die Menge Z kleiner als 1,5, gleich 0,93319.
Beispiel 1. Das Unternehmen produziert Teile, deren Lebensdauer normalverteilt mit einem Mittelwert von 1000 Stunden und einer Standardabweichung von 200 Stunden ist.
Berechnen Sie für ein zufällig ausgewähltes Teil die Wahrscheinlichkeit, dass seine Lebensdauer mindestens 900 Stunden beträgt.
Lösung. Lassen Sie uns die erste Notation einführen:
Die gewünschte Wahrscheinlichkeit.
Die Zufallsvariablenwerte liegen in einem offenen Intervall. Aber wir wissen, wie man die Wahrscheinlichkeit berechnet, dass eine Zufallsvariable einen Wert annimmt, der kleiner als ein gegebener Wert ist, und entsprechend den Bedingungen des Problems müssen wir einen Wert finden, der gleich oder größer als ein gegebener Wert ist. Dies ist der andere Teil des Raums unter der normalen Dichtekurve (Glocke). Um die gewünschte Wahrscheinlichkeit zu ermitteln, müssen Sie daher die erwähnte Wahrscheinlichkeit, dass die Zufallsvariable einen Wert kleiner als die angegebenen 900 annimmt, von Eins subtrahieren:
Nun muss die Zufallsvariable standardisiert werden.
Wir führen weiterhin die Notation ein:
z = (X ≤ 900) ;
X= 900 - angegebener Wert der Zufallsvariablen;
μ = 1000 - Durchschnittswert;
σ = 200 - Standardabweichung.
Anhand dieser Daten erhalten wir die Bedingungen des Problems:
![]() .
.
Nach Tabellen standardisierter Zufallsvariablen (Intervallgrenze) z= −0,5 entspricht einer Wahrscheinlichkeit von 0,30854. Subtrahieren Sie es von der Einheit und erhalten Sie, was in der Problemstellung erforderlich ist:
Die Wahrscheinlichkeit, dass das Teil eine Lebensdauer von mindestens 900 Stunden hat, liegt also bei 69 %.
Diese Wahrscheinlichkeit kann mit der MS Excel-Funktion NORM.VERT (Integralwert - 1) ermittelt werden:
P(X≥900) = 1 - P(X≤900) = 1 - NORM.VERT(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
Über Berechnungen in MS Excel – in einem der folgenden Absätze dieser Lektion.
Beispiel 2. In einer bestimmten Stadt ist das durchschnittliche jährliche Familieneinkommen eine normalverteilte Zufallsvariable mit einem Mittelwert von 300.000 und einer Standardabweichung von 50.000. Es ist bekannt, dass das Einkommen von 40 % der Familien geringer ist A. Finden Sie den Wert A.
Lösung. In diesem Problem ist 40 % nichts anderes als die Wahrscheinlichkeit, dass die Zufallsvariable einen Wert aus einem offenen Intervall annimmt, der kleiner als ein bestimmter Wert ist, der durch den Buchstaben angegeben wird A.
Um den Wert zu finden A, bilden wir zunächst die Integralfunktion:
![]()
Je nach den Bedingungen des Problems
μ = 300000 - Durchschnittswert;
σ = 50000 - Standardabweichung;
X = A- die zu findende Menge.
Eine Gleichberechtigung herstellen
![]() .
.
Aus den statistischen Tabellen finden wir, dass die Wahrscheinlichkeit von 0,40 dem Wert der Intervallgrenze entspricht z = −0,25 .
Deshalb schaffen wir die Gleichberechtigung
![]()
und finde seine Lösung:
A = 287300 .
Antwort: 40 % der Familien haben ein Einkommen von weniger als 287.300.
Geschlossenes Intervall
Bei vielen Problemen muss die Wahrscheinlichkeit ermittelt werden, mit der eine normalverteilte Zufallsvariable einen Wert im Intervall von annimmt z 1 zu z 2. Das heißt, es wird in ein geschlossenes Intervall fallen. Um solche Probleme zu lösen, ist es notwendig, in der Tabelle die Wahrscheinlichkeiten zu finden, die den Grenzen des Intervalls entsprechen, und dann die Differenz zwischen diesen Wahrscheinlichkeiten zu ermitteln. Dazu muss der kleinere Wert vom größeren subtrahiert werden. Beispiele für Lösungen für diese häufigen Probleme sind die folgenden. Sie werden gebeten, sie selbst zu lösen, und dann können Sie die richtigen Lösungen und Antworten sehen.
Beispiel 3. Der Gewinn eines Unternehmens für einen bestimmten Zeitraum ist eine Zufallsgröße, die dem Normalverteilungsgesetz unterliegt und einen Durchschnittswert von 0,5 Millionen hat. und Standardabweichung 0,354. Bestimmen Sie mit einer Genauigkeit von zwei Dezimalstellen die Wahrscheinlichkeit, dass der Gewinn des Unternehmens zwischen 0,4 und 0,6 c.u. liegen wird.
Beispiel 4. Die Länge des gefertigten Teils ist eine nach dem Normalgesetz mit Parametern verteilte Zufallsvariable μ =10 und σ =0,071. Ermitteln Sie die Fehlerwahrscheinlichkeit mit einer Genauigkeit von zwei Dezimalstellen, wenn die zulässigen Abmessungen des Teils 10 ± 0,05 betragen müssen.
Hinweis: Bei diesem Problem müssen Sie zusätzlich zur Ermittlung der Wahrscheinlichkeit, dass eine Zufallsvariable in ein geschlossenes Intervall fällt (die Wahrscheinlichkeit, ein fehlerfreies Teil zu erhalten), eine weitere Aktion ausführen.

ermöglicht es Ihnen, die Wahrscheinlichkeit zu bestimmen, dass der standardisierte Wert Z nicht weniger -z und nicht mehr +z, Wo z- ein willkürlich ausgewählter Wert einer standardisierten Zufallsvariablen.
Eine ungefähre Methode zur Überprüfung der Normalität einer Verteilung
Eine ungefähre Methode zur Überprüfung der Normalität der Verteilung von Stichprobenwerten basiert auf dem Folgenden Eigenschaft der Normalverteilung: Schiefekoeffizient β 1 und Kurtosis-Koeffizient β 2 sind gleich Null.
Asymmetriekoeffizient β 1 charakterisiert numerisch die Symmetrie der empirischen Verteilung relativ zum Mittelwert. Wenn der Schiefekoeffizient Null ist, sind das arithmetrische Mittel, der Median und der Modus gleich: und die Verteilungsdichtekurve ist symmetrisch zum Mittelwert. Wenn der Asymmetriekoeffizient kleiner als Null ist (β 1 < 0 ), dann ist das arithmetische Mittel kleiner als der Median, und der Median wiederum ist kleiner als mode () und die Kurve ist nach rechts verschoben (im Vergleich zur Normalverteilung). Wenn der Asymmetriekoeffizient größer als Null ist (β 1 > 0 ), dann ist das arithmetische Mittel größer als der Median, und der Median wiederum ist größer als der Modus () und die Kurve ist nach links verschoben (im Vergleich zur Normalverteilung).
Kurtosis-Koeffizient β 2 charakterisiert die Konzentration der empirischen Verteilung um das arithmetische Mittel in Richtung der Achse Oy und der Grad der Spitze der Verteilungsdichtekurve. Wenn der Kurtosis-Koeffizient größer als Null ist, ist die Kurve länger (im Vergleich zur Normalverteilung). entlang der Achse Oy(Die Grafik ist spitzer). Wenn der Kurtosis-Koeffizient kleiner als Null ist, ist die Kurve flacher (im Vergleich zur Normalverteilung). entlang der Achse Oy(Der Graph ist stumpfer).
Der Asymmetriekoeffizient kann mit der MS Excel SKOS-Funktion berechnet werden. Wenn Sie ein Datenarray überprüfen, müssen Sie den Datenbereich in ein „Zahlen“-Feld eingeben.

Der Kurtosis-Koeffizient kann mit der MS Excel-KURTESS-Funktion berechnet werden. Bei der Prüfung eines Datenfeldes reicht es auch aus, den Datenbereich in ein Feld „Zahl“ einzugeben.

Wie wir bereits wissen, sind bei einer Normalverteilung die Schiefe- und Kurtosis-Koeffizienten gleich Null. Aber was wäre, wenn wir Schiefekoeffizienten von -0,14, 0,22, 0,43 und Kurtosis-Koeffizienten von 0,17, -0,31, 0,55 hätten? Die Frage ist durchaus berechtigt, da es sich in der Praxis nur um ungefähre Stichprobenwerte der Asymmetrie und Kurtosis handelt, die einer unvermeidlichen, unkontrollierten Streuung unterliegen. Daher kann man nicht verlangen, dass diese Koeffizienten strikt gleich Null sind; sie dürfen nur hinreichend nahe bei Null liegen. Aber was bedeutet genug?
Es ist erforderlich, die erhaltenen Erfahrungswerte mit akzeptablen Werten zu vergleichen. Dazu müssen Sie die folgenden Ungleichungen überprüfen (vergleichen Sie die Werte der Modulkoeffizienten mit den kritischen Werten – den Grenzen des Hypothesentestbereichs).
Für den Asymmetriekoeffizienten β 1 .
Das Normalverteilungsgesetz ist in der Praxis am häufigsten anzutreffen. Das Hauptmerkmal, das es von anderen Gesetzen unterscheidet, besteht darin, dass es ein begrenzendes Gesetz ist, an das sich andere Gesetze der Verteilung unter sehr häufigen typischen Bedingungen annähern.
Definition. Eine kontinuierliche Zufallsvariable X hat normales Gesetz Verteilung(Gaußsches Gesetz )mit Parametern a und σ 2 wenn seine Wahrscheinlichkeitsdichte f(X) sieht aus wie:
| . | (6.19) |
Die Normalverteilungskurve heißt normal oder Gaußsche Kurve. In Abb. 6.5 a), b) zeigt eine Normalkurve mit Parametern A Und σ 2 und Verteilungsfunktionsgraph.
 Achten wir darauf, dass die Normalkurve symmetrisch zur Geraden ist X = A, hat an diesem Punkt ein Maximum X = A, gleich , und zwei Wendepunkte X = A σ
mit Ordinaten.
Achten wir darauf, dass die Normalkurve symmetrisch zur Geraden ist X = A, hat an diesem Punkt ein Maximum X = A, gleich , und zwei Wendepunkte X = A σ
mit Ordinaten.
Es ist zu beachten, dass im Normalgesetz-Dichteausdruck die Verteilungsparameter durch Buchstaben angegeben werden A Und σ 2, mit dem wir den mathematischen Erwartungswert und die Streuung bezeichneten. Dieser Zufall ist kein Zufall. Betrachten wir einen Satz, der die probabilistische theoretische Bedeutung der Parameter des Normalgesetzes festlegt.
Satz. Der mathematische Erwartungswert einer nach einem Normalgesetz verteilten Zufallsvariablen X ist gleich dem Parameter a dieser Verteilung, d.h.
| M(X) = A, | (6.20) |
und seine Dispersion – zum Parameter σ 2, d.h.
| D(X) = σ 2. | (6.21) |
Lassen Sie uns herausfinden, wie sich die Normalkurve ändert, wenn sich die Parameter ändern A Und σ .
Wenn σ = const, und der Parameter ändert sich A (A 1 < A 2 < A 3), d.h. das Symmetriezentrum der Verteilung, dann verschiebt sich die Normalkurve entlang der Abszissenachse, ohne ihre Form zu ändern (Abb. 6.6).

Reis. 6.6

Reis. 6.7
Wenn A= const und der Parameter ändert sich σ , dann ändert sich die Ordinate des Kurvenmaximums f max(A) = . Beim Erhöhen σ die Ordinate des Maximums nimmt ab, aber da die Fläche unter jeder Verteilungskurve gleich Eins bleiben muss, wird die Kurve flacher und erstreckt sich entlang der x-Achse. Beim Abnehmen σ Im Gegenteil: Die Normalkurve dehnt sich nach oben aus und wird gleichzeitig von den Seiten her komprimiert (Abb. 6.7).
Also der Parameter A charakterisiert die Position und den Parameter σ – die Form einer normalen Kurve.
Normalverteilungsgesetz einer Zufallsvariablen mit Parametern A= 0 und σ = 1 wird aufgerufen Standard oder normalisiert, und die entsprechende Normalkurve ist Standard oder normalisiert.
Die Schwierigkeit, die Verteilungsfunktion einer nach dem Normalgesetz verteilten Zufallsvariablen direkt zu finden, liegt darin begründet, dass das Integral der Normalverteilungsfunktion nicht durch Elementarfunktionen ausgedrückt wird. Es kann jedoch durch eine spezielle Funktion berechnet werden, die ein bestimmtes Integral des Ausdrucks oder ausdrückt. Diese Funktion wird aufgerufen Laplace-Funktion, dazu wurden Tabellen zusammengestellt. Es gibt viele Varianten dieser Funktion, zum Beispiel:
![]() ,
, ![]() .
.
Wir werden die Funktion verwenden
Betrachten wir die Eigenschaften einer nach einem Normalgesetz verteilten Zufallsvariablen.
1. Die Wahrscheinlichkeit, dass eine nach einem Normalgesetz verteilte Zufallsvariable X in das Intervall fällt [α , β ] gleich
Mit dieser Formel berechnen wir die Wahrscheinlichkeiten für verschiedene Werte δ (unter Verwendung der Tabelle der Laplace-Funktionswerte):
bei δ = σ = 2Ф(1) = 0,6827;
bei δ = 2σ = 2Ф(2) = 0,9545;
bei δ = 3σ = 2Ф(3) = 0,9973.
Dies führt zum sogenannten „ Drei-Sigma-Regel»:
Wenn eine Zufallsvariable X ein Normalverteilungsgesetz mit den Parametern a und σ hat, dann ist es fast sicher, dass ihre Werte im Intervall liegen(A – 3σ ; A + 3σ ).
Beispiel 6.3. Unter der Annahme, dass die Körpergröße von Männern einer bestimmten Altersgruppe eine normalverteilte Zufallsvariable ist X mit Parametern A= 173 und σ 2 = 36, finde:
1. Ausdruck der Wahrscheinlichkeitsdichte und Verteilungsfunktion einer Zufallsvariablen X;
2. Der Anteil der Anzüge der 4. Körpergröße (176 – 183 cm) und der Anteil der Anzüge der 3. Körpergröße (170 – 176 cm), der in die Gesamtproduktionsmenge dieser Altersgruppe einzurechnen ist;
3. Formulieren Sie die „Drei-Sigma-Regel“ für eine Zufallsvariable X.
1. Ermittlung der Wahrscheinlichkeitsdichte
![]()
und die Verteilungsfunktion der Zufallsvariablen X
![]() = .
= .
2. Als Wahrscheinlichkeit ermitteln wir den Anteil der Anzüge der Höhe 4 (176 – 182 cm).
R(176 ≤ X ≤ 182) = ![]() = Ф(1,5) – Ф(0,5).
= Ф(1,5) – Ф(0,5).
Laut Wertetabelle der Laplace-Funktion ( Anlage 2) wir finden:
F(1,5) = 0,4332, F(0,5) = 0,1915.
Endlich bekommen wir
R(176 ≤ X ≤ 182) = 0,4332 – 0,1915 = 0,2417.
Der Anteil der Anzüge der 3. Körpergröße (170 – 176 cm) lässt sich in ähnlicher Weise ermitteln. Dies ist jedoch einfacher, wenn wir berücksichtigen, dass dieses Intervall in Bezug auf die mathematische Erwartung symmetrisch ist A= 173, d.h. Ungleichung 170 ≤ X≤ 176 entspricht der Ungleichung │ X– 173│≤ 3. Dann
R(170 ≤X ≤176) = R(│X– 173│≤ 3) = 2Ф(3/6) = 2Ф(0,5) = 2·0,1915 = 0,3830.
3. Formulieren wir die „Drei-Sigma-Regel“ für die Zufallsvariable X:
Es ist fast sicher, dass die Körpergröße der Männer in dieser Altersgruppe zwischen A – 3σ = 173 – 3 6 = 155 to A + 3σ = 173 + 3·6 = 191, d.h. 155 ≤ X ≤ 191. ◄
7. GRENZTHÄOREME DER WAHRSCHEINLICHKEITSTHEORIE
Wie bereits erwähnt, lässt sich bei der Untersuchung von Zufallsvariablen nicht im Voraus vorhersagen, welchen Wert eine Zufallsvariable als Ergebnis eines einzelnen Tests annehmen wird – dies hängt von vielen Gründen ab, die nicht berücksichtigt werden können.
Wenn Tests jedoch viele Male wiederholt werden, verliert das Verhalten der Summe der Zufallsvariablen fast seinen Zufallscharakter und wird natürlich. Das Vorhandensein von Mustern hängt gerade mit der Massennatur von Phänomenen zusammen, die in ihrer Gesamtheit eine Zufallsvariable erzeugen, die einem genau definierten Gesetz unterliegt. Das Wesen der Stabilität von Massenphänomenen besteht darin, dass die spezifischen Merkmale jedes einzelnen Zufallsphänomens fast keinen Einfluss auf das durchschnittliche Ergebnis der Masse solcher Phänomene haben; Zufällige Abweichungen vom Durchschnitt, die bei jedem einzelnen Phänomen unvermeidlich sind, werden gegenseitig aufgehoben, nivelliert, in der Masse nivelliert.
Es ist diese Stabilität der Durchschnittswerte, die den physikalischen Inhalt des „Gesetzes der großen Zahlen“ im weitesten Sinne des Wortes darstellt: Bei einer sehr großen Anzahl zufälliger Phänomene ist deren Ergebnis praktisch nicht mehr zufällig und kann mit vorhergesagt werden ein hohes Maß an Sicherheit.
Im engeren Sinne des Wortes wird unter dem „Gesetz der großen Zahlen“ in der Wahrscheinlichkeitstheorie eine Reihe mathematischer Theoreme verstanden, die jeweils unter bestimmten Bedingungen die Tatsache begründen, dass sich die durchschnittlichen Eigenschaften einer großen Anzahl von Experimenten bestimmten nähern bestimmte Konstanten.
Das Gesetz der großen Zahlen spielt in der praktischen Anwendung der Wahrscheinlichkeitstheorie eine wichtige Rolle. Die Eigenschaft von Zufallsvariablen, sich unter bestimmten Bedingungen praktisch wie nichtzufällige Variablen zu verhalten, ermöglicht es, mit diesen Größen sicher zu arbeiten und die Ergebnisse von Massenzufallsphänomenen mit nahezu vollständiger Sicherheit vorherzusagen.
Die Möglichkeiten solcher Vorhersagen im Bereich der Massenzufallsphänomene werden durch das Vorhandensein einer weiteren Gruppe von Grenzwertsätzen weiter erweitert, die sich nicht auf die Grenzwerte von Zufallsvariablen, sondern auf die Grenzgesetze der Verteilung beziehen. Wir sprechen von einer Gruppe von Theoremen, die als „zentraler Grenzwertsatz“ bekannt sind. Die verschiedenen Formen des zentralen Grenzwertsatzes unterscheiden sich voneinander in den Bedingungen, unter denen diese limitierende Eigenschaft der Summe von Zufallsvariablen festgestellt wird.
Verschiedene Formen des Gesetzes der großen Zahlen mit verschiedenen Formen des zentralen Grenzwertsatzes bilden eine Reihe sogenannter Grenzwertsätze Wahrscheinlichkeitstheorie. Grenzwertsätze ermöglichen es, nicht nur wissenschaftliche Vorhersagen im Bereich Zufallsphänomene zu treffen, sondern auch die Genauigkeit dieser Vorhersagen zu bewerten.
Die Zufallsvariable heißt nach dem Normalgesetz (Gaußsches Gesetz) mit Parametern verteilt A Und () , wenn die Wahrdie Form hat
Eine normalverteilte Größe hat immer unendlich viele mögliche Werte, daher ist es praktisch, sie grafisch mithilfe eines Verteilungsdichtediagramms darzustellen. Nach der Formel
Die Wahrscheinlichkeit, dass eine Zufallsvariable einen Wert aus einem Intervall annimmt, ist gleich der Fläche unter dem Graphen einer Funktion in diesem Intervall (die geometrische Bedeutung eines bestimmten Integrals). Die betrachtete Funktion ist nicht negativ und stetig. Der Graph der Funktion hat die Form einer Glocke und wird Gaußkurve oder Normalkurve genannt.
Die Abbildung zeigt mehrere Verteilungsdichtekurven einer nach dem Normalgesetz angegebenen Zufallsvariablen.
Alle Kurven haben einen Maximalpunkt, und je weiter man sich von diesem nach rechts und links entfernt, desto kleiner werden die Kurven. Das Maximum wird bei erreicht und ist gleich.
Die Kurven sind symmetrisch zu einer vertikalen Linie, die durch den höchsten Punkt gezogen wird. Die Fläche des Untergraphen jeder Kurve beträgt 1.
Der Unterschied zwischen einzelnen Verteilungskurven besteht lediglich darin, dass die Gesamtfläche des Teilgraphen, die für alle Kurven gleich ist, unterschiedlich auf verschiedene Abschnitte verteilt ist. Der Hauptteil der Untergraphenfläche jeder Kurve konzentriert sich in unmittelbarer Nähe des wahrscheinlichsten Werts, und dieser Wert ist für alle drei Kurven unterschiedlich. Für unterschiedliche Werte und A Es werden unterschiedliche Normalgesetze und unterschiedliche Derhalten.
Theoretische Studien haben gezeigt, dass die meisten in der Praxis vorkommenden Zufallsvariablen ein Normalverteilungsgesetz haben. Nach diesem Gesetz werden die Geschwindigkeit von Gasmolekülen, das Gewicht von Neugeborenen, die Größe von Kleidung und Schuhen der Bevölkerung des Landes und viele andere zufällige Ereignisse physikalischer und biologischer Natur verteilt. Dieses Muster wurde erstmals von A. Moivre bemerkt und theoretisch begründet.
Für stimmt die Funktion mit der Funktion überein, die bereits im lokalen Grenzwertsatz von Moivre-Laplace diskutiert wurde. Die Wahrscheinlichkeitsdichte einer Normalverteilung ist einfach ausgedrückt durch:
Für solche Parameterwerte heißt das Normalgesetz hauptsächlich .
Die Verteilungsfunktion für die normalisierte Dichte wird aufgerufen Laplace-Funktion und ist bezeichnet Φ(x). Auch diese Funktion ist uns bereits begegnet.
Die Laplace-Funktion hängt nicht von bestimmten Parametern ab A und σ. Für die Laplace-Funktion wurden unter Verwendung von Näherungsintegrationsmethoden Wertetabellen für das Intervall mit unterschiedlichem Genauigkeitsgrad erstellt. Offensichtlich ist die Laplace-Funktion ungerade, daher besteht keine Notwendigkeit, ihre Werte für negativ in die Tabelle einzutragen.
Für eine nach dem Normalgesetz verteilte Zufallsvariable mit Parametern A und , der mathematische Erwartungswert und die Streuung werden mithilfe der Formeln berechnet: , . Die Standardabweichung ist gleich .
Die Wahrscheinlichkeit, dass eine normalverteilte Größe einen Wert aus dem Intervall annimmt, ist gleich
Wo ist die im Integralgrenzwertsatz eingeführte Laplace-Funktion?
Bei Problemen ist es oft erforderlich, die Wahrscheinlichkeit der Abweichung einer normalverteilten Zufallsvariablen zu berechnen X aus seiner mathematischen Erwartung im absoluten Wert einen bestimmten Wert nicht überschreitet, d.h. Wahrscheinlichkeit berechnen. Unter Anwendung der Formel (19.2) erhalten wir:
Abschließend präsentieren wir eine wichtige Folgerung aus Formel (19.3). Geben wir diese Formel ein. Dann, d.h. die Wahrscheinlichkeit, dass der absolute Wert der Abweichung X seiner mathematischen Erwartung wird , gleich 99,73 % nicht überschreiten. In der Praxis kann ein solches Ereignis als zuverlässig angesehen werden. Dies ist die Essenz der Drei-Sigma-Regel.
Drei-Sigma-Regel. Wenn eine Zufallsvariable normalverteilt ist, überschreitet der Absolutwert ihrer Abweichung vom mathematischen Erwartungswert praktisch nicht das Dreifache der Standardabweichung.
Der Artikel zeigt im Detail, was das Normalverteilungsgesetz einer Zufallsvariablen ist und wie man es bei der Lösung praktischer Probleme verwendet.
Normalverteilung in der Statistik
Die Geschichte des Gesetzes reicht 300 Jahre zurück. Der erste Entdecker war Abraham de Moivre, der die Näherung bereits 1733 vorstellte. Viele Jahre später leiteten Carl Friedrich Gauß (1809) und Pierre-Simon Laplace (1812) mathematische Funktionen ab.
Auch Laplace entdeckte ein bemerkenswertes Muster und formulierte es Zentraler Grenzwertsatz (CPT), wonach die Summe einer großen Anzahl kleiner und unabhängiger Größen eine Normalverteilung aufweist.
Das Normalgesetz ist keine feste Gleichung der Abhängigkeit einer Variablen von einer anderen. Es wird lediglich die Art dieser Abhängigkeit erfasst. Die konkrete Verteilungsform wird durch spezielle Parameter spezifiziert. Zum Beispiel, y = Axt + B ist die Gleichung einer Geraden. Wo genau und in welchem Winkel es verläuft, wird jedoch durch die Parameter bestimmt A Und B. Das Gleiche gilt für die Normalverteilung. Es ist klar, dass es sich hierbei um eine Funktion handelt, die eine Tendenz zur starken Konzentration von Werten um das Zentrum herum beschreibt, ihre genaue Form wird jedoch durch spezielle Parameter bestimmt.
Die Gaußsche Normalverteilungskurve sieht folgendermaßen aus.
Ein Normalverteilungsdiagramm ähnelt einer Glocke, weshalb Sie möglicherweise den Namen sehen Glockenkurve. Das Diagramm weist in der Mitte einen „Buckel“ und an den Rändern einen starken Dichteabfall auf. Dies ist die Essenz der Normalverteilung. Die Wahrscheinlichkeit, dass eine Zufallsvariable in der Nähe des Zentrums liegt, ist viel höher als die Wahrscheinlichkeit, dass sie stark vom Zentrum abweicht.

Die obige Abbildung zeigt zwei Bereiche unter der Gaußschen Kurve: Blau und Grün. Gründe, d.h. Die Abstände sind für beide Abschnitte gleich. Aber die Höhen unterscheiden sich deutlich. Der blaue Bereich liegt weiter vom Zentrum entfernt und hat eine deutlich geringere Höhe als der grüne Bereich, der sich genau in der Mitte der Verteilung befindet. Folglich unterscheiden sich auch die Flächen, also die Wahrscheinlichkeiten, in die vorgesehenen Intervalle zu fallen.
Die Formel für die Normalverteilung (Dichte) lautet wie folgt.
![]()
Die Formel besteht aus zwei mathematischen Konstanten:
π – Pi-Zahl 3,142;
e– natürlicher Logarithmus zur Basis 2,718;
zwei veränderbare Parameter, die die Form einer bestimmten Kurve definieren:
M– mathematische Erwartung (andere Notationen können in verschiedenen Quellen verwendet werden, z. B. µ oder A);
σ 2– Streuung;
und die Variable selbst X, für die die Wahrscheinlichkeitsdichte berechnet wird.
Die konkrete Form der Normalverteilung hängt von 2 Parametern ab: ( M) Und ( σ 2). Kurz angedeutet N(m, σ 2) oder N(m, σ). Parameter M(Erwartung) bestimmt das Zentrum der Verteilung, das der maximalen Höhe des Diagramms entspricht. Streuung σ 2 charakterisiert den Variationsbereich, also die „Verschmierung“ der Daten.
Der mathematische Erwartungsparameter verschiebt das Verteilungszentrum nach rechts oder links, ohne die Form der Dichtekurve selbst zu beeinflussen.

Aber die Streuung bestimmt die Schärfe der Kurve. Wenn die Daten eine geringe Streuung aufweisen, ist ihre gesamte Masse im Zentrum konzentriert. Wenn die Daten eine große Streuung aufweisen, dann sind sie über einen weiten Bereich „verteilt“.

Die Verteilungsdichte hat keine direkte praktische Anwendung. Um die Wahrscheinlichkeiten zu berechnen, müssen Sie die Dichtefunktion integrieren.
Die Wahrscheinlichkeit, dass eine Zufallsvariable kleiner als ein bestimmter Wert ist X, festgestellt wird Normalverteilungsfunktion:
Unter Verwendung der mathematischen Eigenschaften einer kontinuierlichen Verteilung ist es seitdem einfach, alle anderen Wahrscheinlichkeiten zu berechnen
P(a ≤ X< b) = Ф(b) – Ф(a)
Standardnormalverteilung
Die Normalverteilung hängt von den Parametern Mittelwert und Varianz ab, weshalb ihre Eigenschaften schlecht sichtbar sind. Es wäre schön, eine Verteilungsreferenz zu haben, die nicht vom Umfang der Daten abhängt. Und es existiert. Angerufen Standardnormalverteilung. Tatsächlich handelt es sich um eine gewöhnliche Normalverteilung, nur mit den Parametern mathematischer Erwartungswert 0 und Varianz 1, kurz N(0, 1) geschrieben.
Jede Normalverteilung kann durch Normalisierung leicht in eine Standardverteilung umgewandelt werden:
Wo z– eine neue Variable, die stattdessen verwendet wird X;
M- erwarteter Wert;
σ
- Standardabweichung.
Für Beispieldaten werden Schätzungen vorgenommen:
Arithmetisches Mittel und Varianz der neuen Variablen z sind jetzt auch 0 bzw. 1. Dies kann mithilfe elementarer algebraischer Transformationen leicht überprüft werden.
Der Name erscheint in der Literatur Z-Score. Das sind sie – normalisierte Daten. Z-Score kann direkt mit theoretischen Wahrscheinlichkeiten verglichen werden, weil sein Maßstab stimmt mit dem Standard überein.
Sehen wir uns nun an, wie die Dichte der Standardnormalverteilung aussieht (für Z-Scores). Ich möchte Sie daran erinnern, dass die Gaußsche Funktion die Form hat:
![]()
Lassen Sie uns stattdessen ersetzen (x-m)/σ Brief z, und stattdessen σ – eins, wir bekommen Dichtefunktion der Standardnormalverteilung:
![]()
Dichtediagramm:

Das Zentrum liegt erwartungsgemäß am Punkt 0. Am gleichen Punkt erreicht die Gaußsche Funktion ihr Maximum, was der Annahme des Durchschnittswerts durch die Zufallsvariable entspricht (d. h. x-m=0). Die Dichte an diesem Punkt beträgt 0,3989, was sogar im Kopf berechnet werden kann, weil e 0 =1 und es bleibt nur noch das Verhältnis von 1 zur Wurzel von 2 pi zu berechnen.
Somit zeigt die Grafik deutlich, dass Werte, die geringe Abweichungen vom Durchschnitt aufweisen, häufiger vorkommen als andere, und solche, die sehr weit vom Zentrum entfernt sind, deutlich seltener vorkommen. Die x-Achsenskala wird in Standardabweichungen gemessen, wodurch Sie auf Maßeinheiten verzichten und eine universelle Struktur einer Normalverteilung erhalten können. Die Gaußsche Kurve für normalisierte Daten veranschaulicht perfekt andere Eigenschaften der Normalverteilung. Zum Beispiel, dass es symmetrisch zur Ordinatenachse ist. Die meisten Werte konzentrieren sich innerhalb von ±1σ vom arithmetischen Mittel (wir schätzen vorerst nach Augenmaß). Die meisten Daten liegen innerhalb von ±2σ. Fast alle Daten liegen innerhalb von ±3σ. Die letzte Eigenschaft ist weithin bekannt als Drei-Sigma-Regel für Normalverteilung.
Mit der Skönnen Sie Wahrscheinlichkeiten berechnen.
![]()
Es ist klar, dass niemand manuell zählt. Alles wird berechnet und in speziellen Tabellen abgelegt, die am Ende jedes Statistiklehrbuchs stehen.
Normalverteilungstabelle
Es gibt zwei Arten von Normalverteilungstabellen:
- Tisch Dichte;
- Tisch Funktionen(Dichteintegral).
Tisch Dichte kaum benutzt. Aber schauen wir mal, wie es aussieht. Nehmen wir an, wir müssen die Dichte ermitteln z = 1, d.h. Dichte eines Werts, der um 1 Sigma vom Erwartungswert getrennt ist. Unten ist ein Ausschnitt der Tabelle.

Abhängig von der Organisation der Daten suchen wir anhand des Namens der Spalte und Zeile nach dem gewünschten Wert. In unserem Beispiel nehmen wir die Linie 1,0 und Spalte 0 , Weil es gibt keine Hundertstel. Der gesuchte Wert ist 0,2420 (die 0 vor 2420 wird weggelassen).
Die Gaußsche Funktion ist symmetrisch zur Ordinate. Deshalb φ(z)= φ(-z), d.h. Dichte für 1 ist identisch mit der Dichte für -1 , was in der Abbildung deutlich zu erkennen ist.

Um Papierverschwendung zu vermeiden, werden Tabellen nur für positive Werte gedruckt.
In der Praxis werden die Werte häufiger verwendet Funktionen Standardnormalverteilung, das heißt, die Wahrscheinlichkeit ist unterschiedlich z.
Auch solche Tabellen enthalten nur positive Werte. Deshalb verstehen und finden beliebig Sie sollten die erforderlichen Wahrscheinlichkeiten kennen Eigenschaften der Standardnormalverteilung.
Funktion Ф(z) symmetrisch um seinen Wert 0,5 (und nicht um die Ordinatenachse, wie die Dichte). Daher gilt die Gleichheit:
Dieser Sachverhalt ist im Bild dargestellt:

Funktionswerte Ф(-z) Und Ф(z) Teilen Sie die Grafik in 3 Teile. Darüber hinaus sind Ober- und Unterteil gleich (durch Häkchen gekennzeichnet). Zur Ergänzung der Wahrscheinlichkeit Ф(z) zu 1, fügen Sie einfach den fehlenden Wert hinzu Ф(-z). Sie erhalten die oben angegebene Gleichheit.
Wenn Sie die Wahrscheinlichkeit ermitteln müssen, in das Intervall zu fallen (0;z), also die Wahrscheinlichkeit einer Abweichung von Null in positiver Richtung um eine bestimmte Anzahl von Standardabweichungen, reicht es aus, 0,5 vom Wert der Sabzuziehen:

Zur Verdeutlichung können Sie sich die Zeichnung ansehen.

Auf einer Gaußschen Kurve sieht dieselbe Situation wie der Bereich von der Mitte nach rechts aus z.

Sehr oft interessiert sich ein Analyst für die Wahrscheinlichkeit einer Abweichung von Null in beide Richtungen. Und da die Funktion symmetrisch zum Mittelpunkt ist, muss die vorherige Formel mit 2 multipliziert werden:

Bild unten.

Unter der Gaußschen Kurve ist dies der zentrale Teil, der durch den ausgewählten Wert begrenzt wird –z links und z rechts.

Diese Eigenschaften sollten berücksichtigt werden, denn Tabellierte Werte entsprechen selten dem interessierenden Intervall.
Um die Aufgabe zu erleichtern, veröffentlichen Lehrbücher normalerweise Tabellen für Funktionen der Form:

Wenn Sie die Abweichungswahrscheinlichkeit in beide Richtungen von Null benötigen, dann multiplizieren Sie, wie wir gerade gesehen haben, den Tabellenwert für diese Funktion einfach mit 2.
Schauen wir uns nun konkrete Beispiele an. Nachfolgend finden Sie eine Tabelle der Standardnormalverteilung. Lassen Sie uns die Tabellenwerte für drei finden z: 1,64, 1,96 und 3.

Wie versteht man die Bedeutung dieser Zahlen? Lass uns beginnen mit z=1,64, für den der Tabellenwert ist 0,4495 . Die Bedeutung lässt sich am einfachsten anhand der Abbildung erklären.

Das heißt, die Wahrscheinlichkeit, dass eine standardisierte normalverteilte Zufallsvariable in das Intervall von fällt 0 Vor 1,64 , ist gleich 0,4495 . Bei der Lösung von Problemen müssen Sie normalerweise die Abweichungswahrscheinlichkeit in beide Richtungen berechnen, also multiplizieren wir den Wert 0,4495 um 2 und wir erhalten ungefähr 0,9. Die eingenommene Fläche unter der Gaußschen Kurve ist unten dargestellt.

Somit fallen 90 % aller normalverteilten Werte in das Intervall ±1,64σ aus dem arithmetischen Mittel. Es war kein Zufall, dass ich die Bedeutung gewählt habe z=1,64, Weil Die Umgebung um das arithmetische Mittel, die 90 % der gesamten Fläche einnimmt, wird manchmal zur Berechnung von Konfidenzintervallen verwendet. Liegt der geprüfte Wert nicht im vorgesehenen Bereich, ist sein Auftreten unwahrscheinlich (nur 10 %).
Um Hypothesen zu testen, wird jedoch häufiger ein Intervall verwendet, das 95 % aller Werte abdeckt. Die halbe Chance 0,95 - Das 0,4750 (siehe den zweiten hervorgehobenen Wert in der Tabelle).

Für diese Wahrscheinlichkeit z=1,96. Diese. innerhalb von fast ±2σ 95 % der Werte liegen im Durchschnitt. Nur 5 % liegen außerhalb dieser Grenzen.

Ein weiterer interessanter und häufig verwendeter Tabellenwert entspricht z=3, es ist laut unserer Tabelle gleich 0,4986 . Mit 2 multiplizieren und erhalten 0,997 . Also, innerhalb ±3σ Fast alle Werte werden aus dem arithmetischen Mittel abgeleitet.

So sieht die 3-Sigma-Regel für eine Normalverteilung in einem Diagramm aus.
Mithilfe statistischer Tabellen können Sie jede beliebige Wahrscheinlichkeit ermitteln. Allerdings ist diese Methode sehr langsam, unpraktisch und sehr veraltet. Heute wird alles am Computer erledigt. Als nächstes wenden wir uns der Praxis der Berechnungen in Excel zu.
Normalverteilung in Excel
Excel verfügt über mehrere Funktionen zum Berechnen der Wahrscheinlichkeiten oder Umkehrungen einer Normalverteilung.

NORMAL DIST-Funktion
Funktion NORM.ST.DIST. Entwickelt, um die Dichte zu berechnen ϕ(z) oder Wahrscheinlichkeiten Φ(z) nach normalisierten Daten ( z).
=NORM.ST.DIST(z;Integral)
z– Wert der normierten Variablen
Integral– wenn 0, dann wird die Dichte berechnetϕ(z) , wenn 1 der Wert der Funktion Ф(z) ist, d.h. Wahrscheinlichkeit P(Z
Berechnen wir die Dichte und den Funktionswert für verschiedene z: -3, -2, -1, 0, 1, 2, 3(wir werden sie in Zelle A2 angeben).
Um die Dichte zu berechnen, benötigen Sie die Formel =NORM.ST.DIST(A2;0). Im Diagramm unten ist dies der rote Punkt.
Um den Wert der Funktion =NORM.ST.DIST(A2;1) zu berechnen. Das Diagramm zeigt den schattierten Bereich unter der Normalkurve.

In der Realität ist es häufiger erforderlich, die Wahrscheinlichkeit zu berechnen, dass eine Zufallsvariable bestimmte Grenzen des Durchschnitts nicht überschreitet (in Standardabweichungen entsprechend der Variablen). z), d.h. P(|Z|

Bestimmen wir die Wahrscheinlichkeit, dass eine Zufallsvariable innerhalb der Grenzen liegt ±1z, ±2z und ±3z von Null. Brauche eine Formel 2Ф(z)-1, in Excel =2*NORM.ST.DIST(A2;1)-1.

Das Diagramm zeigt deutlich die wichtigsten Grundeigenschaften der Normalverteilung, einschließlich der Drei-Sigma-Regel. Funktion NORM.ST.DIST. ist eine automatische Tabelle mit Normalverteilungsfunktionswerten in Excel.
Es kann auch ein umgekehrtes Problem geben: entsprechend der verfügbaren Wahrscheinlichkeit P(Z
NORMAL REV-Funktion
NORM.ST.REV berechnet die Umkehrung der Standardnormalverteilungsfunktion. Die Syntax besteht aus einem Parameter:
=NORM.ST.REV(Wahrscheinlichkeit)
Wahrscheinlichkeit ist eine Wahrscheinlichkeit.
Diese Formel wird genauso oft verwendet wie die vorherige, da mit denselben Tabellen nicht nur nach Wahrscheinlichkeiten, sondern auch nach Quantilen gesucht werden muss.

Beispielsweise wird bei der Berechnung von Konfidenzintervallen eine Konfidenzwahrscheinlichkeit angegeben, nach der der Wert berechnet werden muss z.

Da das Konfidenzintervall aus einer Ober- und einer Untergrenze besteht und die Normalverteilung symmetrisch um Null ist, reicht es aus, die Obergrenze (positive Abweichung) zu ermitteln. Der untere Grenzwert wird mit negativem Vorzeichen angenommen. Bezeichnen wir die Konfidenzwahrscheinlichkeit als γ (Gamma), dann wird die Obergrenze des Konfidenzintervalls anhand der folgenden Formel berechnet.
![]()
Berechnen wir die Werte in Excel z(was der Abweichung vom Durchschnitt in Sigma entspricht) für mehrere Wahrscheinlichkeiten, darunter auch solche, die jeder Statistiker auswendig kennt: 90 %, 95 % und 99 %. In Zelle B2 geben wir die Formel an: =NORM.ST.REV((1+A2)/2). Durch Ändern des Wertes der Variablen (Wahrscheinlichkeit in Zelle A2) erhalten wir unterschiedliche Grenzen der Intervalle.

Das 95 %-Konfidenzintervall beträgt 1,96, also fast 2 Standardabweichungen. Von hier aus ist es sogar mental leicht, die mögliche Streuung einer normalen Zufallsvariablen abzuschätzen. Im Allgemeinen entsprechen die Konfidenzintervalle 90 %, 95 % und 99 % den Konfidenzintervallen ±1,64, ±1,96 und ±2,58σ.
Im Allgemeinen ermöglichen Ihnen die Funktionen NORM.ST.DIST und NORM.ST.REV die Durchführung beliebiger Berechnungen im Zusammenhang mit der Normalverteilung. Aber um die Sache einfacher und weniger kompliziert zu machen, verfügt Excel über mehrere andere Funktionen. Sie können beispielsweise CONFIDENCE NORM verwenden, um Konfidenzintervalle für den Mittelwert zu berechnen. Zur Überprüfung des arithmetischen Mittels gibt es die Formel Z.TEST.
Schauen wir uns ein paar weitere nützliche Formeln mit Beispielen an.
NORMAL DIST-Funktion
Funktion NORMALDIST. unterscheidet sich von NORM.ST.DIST. Nur weil es zur Verarbeitung von Daten jeglichen Maßstabs und nicht nur normalisierter Daten verwendet wird. In der Syntax werden Normalverteilungsparameter angegeben.
=NORM.VERT(x,Durchschnitt,Standardabweichung,Integral)
Durchschnitt– mathematische Erwartung, die als erster Parameter des Normalverteilungsmodells verwendet wird
standard_off– Standardabweichung – der zweite Parameter des Modells
Integral– wenn 0, dann wird die Dichte berechnet, wenn 1 – dann der Wert der Funktion, d.h. P(X
Beispielsweise wird die Dichte für den Wert 15, der aus einer normalen Probe mit einem Erwartungswert von 10 und einer Standardabweichung von 3 extrahiert wurde, wie folgt berechnet:

Wenn der letzte Parameter auf 1 gesetzt ist, erhalten wir die Wahrscheinlichkeit, dass die normale Zufallsvariable für die gegebenen Verteilungsparameter kleiner als 15 ist. Somit können Wahrscheinlichkeiten direkt aus den Originaldaten berechnet werden.
NORM.REV-Funktion
Dies ist ein Quantil der Normalverteilung, d.h. der Wert der Umkehrfunktion. Die Syntax ist wie folgt.
=NORM.REV(Wahrscheinlichkeit, Durchschnitt, Standardabweichung)
Wahrscheinlichkeit- Wahrscheinlichkeit
Durchschnitt– mathematische Erwartung
standard_off- Standardabweichung
Der Zweck ist der gleiche wie NORM.ST.REV, nur die Funktion funktioniert mit Daten jeglichen Maßstabs.
Ein Beispiel finden Sie im Video am Ende des Artikels.
Normalverteilungsmodellierung
Einige Probleme erfordern die Generierung normaler Zufallszahlen. Hierfür gibt es keine vorgefertigte Funktion. Allerdings verfügt Excel über zwei Funktionen, die Zufallszahlen zurückgeben: FALL ZWISCHEN Und RAND. Die erste erzeugt zufällige, gleichmäßig verteilte ganze Zahlen innerhalb bestimmter Grenzen. Die zweite Funktion generiert gleichmäßig verteilte Zufallszahlen zwischen 0 und 1. Um eine künstliche Stichprobe mit einer beliebigen Verteilung zu erstellen, benötigen Sie die Funktion RAND.
Nehmen wir an, dass es zur Durchführung eines Experiments notwendig ist, eine Stichprobe aus einer normalverteilten Grundgesamtheit mit einem Erwartungswert von 10 und einer Standardabweichung von 3 zu erhalten. Für einen Zufallswert schreiben wir eine Formel in Excel.
NORM.INV(RAND();10;3)
Erweitern wir es auf die erforderliche Anzahl von Zellen und die normale Probe ist fertig.
Um standardisierte Daten zu modellieren, sollten Sie NORM.ST.REV verwenden.
Der Prozess der Umwandlung einheitlicher Zahlen in normale Zahlen kann im folgenden Diagramm dargestellt werden. Aus den einheitlichen Wahrscheinlichkeiten, die durch die RAND-Formel generiert werden, werden horizontale Linien zum Diagramm der Normalverteilungsfunktion gezogen. Dann werden von den Schnittpunkten der Wahrscheinlichkeiten mit dem Diagramm Projektionen auf die horizontale Achse abgesenkt.