Uniformna slučajna distribucija. Zakoni raspodjele kontinuiranih slučajnih varijabli. Primjeri rješavanja problema jednolike distribucije vjerojatnosti
Funkcija distribucije u ovom slučaju, prema (5.7), će imati oblik:
gdje je: m – matematičko očekivanje, s – standardna devijacija.
Normalna distribucija se također naziva Gaussovom po njemačkom matematičaru Gaussu. Činjenica da slučajna varijabla ima normalnu distribuciju s parametrima: m, označava se na sljedeći način: N (m,s), gdje je: m =a =M ;
Često se u formulama matematičko očekivanje označava sa A . Ako je slučajna varijabla raspodijeljena prema zakonu N(0,1), tada se naziva normalizirana ili standardizirana normalna varijabla. Funkcija distribucije za njega ima oblik:
|
|
 .
.Grafikon gustoće normalne distribucije, koji se naziva normalna krivulja ili Gaussova krivulja, prikazan je na slici 5.4.

Riža. 5.4. Normalna gustoća distribucije
Na primjeru se razmatra određivanje numeričkih karakteristika slučajne varijable njezinom gustoćom.
Primjer 6.
Kontinuirana slučajna varijabla određena je gustoćom distribucije: ![]() .
.
Odrediti tip distribucije, pronaći matematičko očekivanje M(X) i varijancu D(X).
Uspoređujući zadanu gustoću raspodjele s (5.16), možemo zaključiti da je dan normalni zakon raspodjele s m = 4. Dakle, matematičko očekivanje M(X)=4, varijanca D(X)=9.
Standardna devijacija s=3.
Laplaceova funkcija koja ima oblik:
|
|
 ,
,povezana je s normalnom funkcijom distribucije (5.17), relacija:
F 0 (x) = F(x) + 0,5.
Laplaceova funkcija je neparna.
F(-x)=-F(x).
Vrijednosti Laplaceove funkcije F(h) prikazane su u tabeli i preuzete iz tablice prema vrijednosti x (vidi Dodatak 1).
Normalna distribucija kontinuirane slučajne varijable igra važnu ulogu u teoriji vjerojatnosti i u opisivanju stvarnosti; vrlo je raširena u slučajnim prirodnim pojavama. U praksi se vrlo često susrećemo sa slučajnim varijablama koje nastaju upravo kao rezultat zbrajanja mnogih slučajnih članova. Konkretno, analiza pogrešaka mjerenja pokazuje da su one zbroj raznih vrsta pogrešaka. Praksa pokazuje da je distribucija vjerojatnosti pogrešaka mjerenja bliska normalnom zakonu.
Pomoću Laplaceove funkcije možete riješiti problem izračuna vjerojatnosti upadanja u zadani interval i zadano odstupanje normalne slučajne varijable.
Uniformna distribucija je takva distribucija slučajne varijable kada ona može poprimiti bilo koju vrijednost unutar zadanih granica s jednakom vjerojatnošću.
Jednolika raspodjela slučajne varijable prikazana je na sl. 5.9.
Riža. 5.9.
Gustoća vjerojatnosti uniformne distribucije ima oblik:

gdje su a i b parametri zakona koji određuju granice promjene slučajne varijable X.
Zakonu jednolike raspodjele posebno podliježu pogreške zbog trenja u nosačima uređaja, neisključeni ostaci sustavnih pogrešaka, pogreške diskretnosti u digitalnim uređajima, dimenzionalne pogreške unutar jedne skupine sortiranja tijekom selektivne montaže, pogreške u parametrima proizvodi odabrani unutar užih granica u odnosu na tehnološke tolerancije, ukupna greška obrade uzrokovana
Sastavni

naziva se normalizirana Laplaceova funkcija, a njezine vrijednosti za x - X različite / = prikazane su u tabeli. Vrijednost normalizirane Laplaceove funkcije F(/) s pogreškom manjom od 10"5 može se odrediti formulom

Ako je / >0, F(/) = 7", i ako je /< 0, то Ф(/) = 1-7". Функция Лапласа нечетная, т. е.
![]()
Za negativne vrijednosti / tablični podaci uzimaju se s znakom minus.
Vjerojatnost da će slučajna varijabla koja se pridržava zakona normalne distribucije tijekom mjerenja poprimiti vrijednost unutar granica (x, x) može se napisati kroz F(/) na sljedeći način:
Za teoretsku krivulju normalne distribucije, njezine grane asimptotski se približavaju apscisnoj osi, tj. zona disperzije slučajne varijable x nalazi se unutar ±oo. U praksi je zona raspršenja slučajne varijable x ograničena na konačne granice.
Na primjer, vjerojatnost da će slučajna varijabla biti unutar

linearna promjena u vremenu dominantnog čimbenika (istrošenost reznog alata, temperaturna deformacija itd.), pogreške nastale zbog zaokruživanja vrijednosti dobivenih mjerenjima na instrumentima itd.
Funkcija distribucije F(x) uniformne distribucije (kumulativna funkcija distribucije) izražena je sljedećom jednadžbom za (a< х < Ь):

Funkcija raspodjele prikazana je na sl. 5.10.
Matematičko očekivanje A/(x), varijanca 0(x) i standardna devijacija (a) slučajne varijable podložne jednolikoj distribuciji jednaki su redom:

U praksi je granično polje raspršenja c s ravnomjernom raspodjelom jednako b - a ili uzimajući u obzir (5.48), t.j.
co = b - a = 2m/Z.

Riža. 5.10.

Riža. 5.11.
Simpsonov zakon
Oblik trokutaste krivulje distribucije prikazan je na sl. 5.11. Gustoća vjerojatnosti ima oblik:

Po tom zakonu raspoređuju se pogreške zbroja (razlike) dviju jednoliko raspoređenih veličina npr. Ako su, na primjer, odstupanja u dimenzijama provrta i osovine ravnomjerno raspoređena unutar tolerancijskih polja, a tolerancije osovine i rupe su približno iste, tada će razmaci unutar tolerancije razmaka biti raspoređeni prema zakonu trokut. Gustoća vjerojatnosti praznina imat će sljedeći oblik:

gdje je 5t(p, 5^ - minimalna i maksimalna vrijednost razmaka u spoju; .$t = ^"^^"la _ prosječna vrijednost razmaka u spoju; /G5 = 5t1p - tolerancija razmaka l - trenutna vrijednost razmaka.
Distribucijska funkcija Simpsonovog zakona ima oblik:

Grafički prikaz funkcije kumulativne distribucije prikazan je na sl. 5.12.
Matematičko očekivanje, varijanca i standardna devijacija slučajne varijable koja poštuje Simpsonov zakon jednaki su:

U praksi je granično polje raspršenja pri distribuciji slučajne varijable prema Simpsonovom zakonu jednako 2/, tj.
![]()

Jednolika raspodjela Kontinuirana slučajna varijabla je distribucija u kojoj su vrijednosti slučajne varijable ograničene s obje strane i imaju istu vjerojatnost unutar intervala. To znači da je u određenom intervalu gustoća vjerojatnosti konstantna.
Dakle, uz jednoliku distribuciju, gustoća vjerojatnosti ima oblik
Vrijednosti f(x) na krajnjim točkama a I b zaplet ( a, b) nisu naznačene, budući da je vjerojatnost pogađanja bilo koje od ovih točaka za kontinuiranu slučajnu varijablu nula.
Krivulja ravnomjerne raspodjele ima oblik pravokutnika koji se oslanja na presjek ( a, b) (slika ispod), zbog čega se uniformna distribucija ponekad naziva "pravokutna".
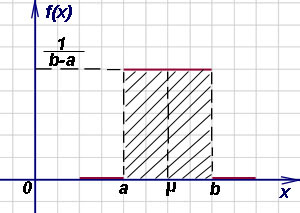
Kako pronaći vjerojatnost pogađanja slučajne varijable x, ravnomjerno raspoređen po površini ( a, b) na bilo koji dio ( α , β ) zaplet ( a, b) ?
Ta se vjerojatnost nalazi formulom
![]()
i geometrijski predstavlja područje dvostruko zasjenjeno na donjoj slici i naslonjeno na dio ( α , β ) zaplet ( a, b) :
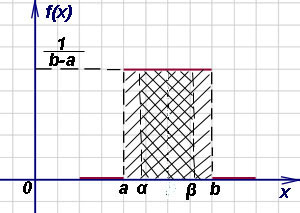
Funkcija distribucije F(x) kontinuirane slučajne varijable s ravnomjernom raspodjelom ima oblik

Karakteristike jednolike distribucije
Karakteristike ravnomjerne distribucije:
Rješavanje primjera za jednoliku raspodjelu
Primjer 1. Promatranja su pokazala da je težina kutije namijenjene prijevozu povrća jednoliko raspoređena slučajna varijabla u rasponu od 985 g do 1025 g. Slučajno je odabrana jedna kutija. Pronađite karakteristike jednoliko raspoređene slučajne varijable pod uvjetima koji će biti navedeni u rješenju.
Riješenje. Nađimo vjerojatnost da će težina određene kutije biti u rasponu od 995 g do 1005 g:
Nađimo prosječnu vrijednost kontinuirane slučajne varijable:
![]() .
.
Nađimo standardnu devijaciju:
![]() .
.
Odredimo koliko posto kutija ima težinu jednu standardnu devijaciju od srednje vrijednosti (tj. u intervalu):
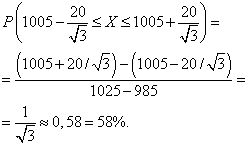 .
.
Primjer 2. Vlakovi podzemne voze redovito u intervalima od 2 (min.). Putnik ulazi na peron u slučajnom trenutku, koji nema nikakve veze s voznim redom. Slučajna vrijednost T- vrijeme u kojem će morati čekati vlak ima jednoliku raspodjelu. Pronađite gustoću distribucije f(x) nasumična varijabla T, njegovo matematičko očekivanje, varijancu i standardnu devijaciju. Pronađite vjerojatnost da nećete morati čekati više od pola minute.
Riješenje. Nađimo gustoću distribucije f(x) :
f(x) = 1/2 (0 < x < 2) .
Nađimo matematičko očekivanje slučajne varijable:
μ = (2 + 0)/2 = 1 .
Nađimo varijancu:
σ ² = 2²/12 = 1/3.
Standardna devijacija:
σ = (√3)/3 .
Nađimo vjerojatnost da putnik neće morati čekati vlak više od pola minute:
P{T < 1/2} = 1/4 .
Primjer 3. Slučajna vrijednost x ravnomjerno raspoređen po površini ( a, b) . Odredite vjerojatnost da će kao rezultat eksperimenta odstupiti od svog matematičkog očekivanja za više od 3 σ .
Primjeri zakona distribucije za kontinuirane slučajne varijable.
Kontinuirana slučajna varijabla X ima uniformni zakon raspodjele na segmentu , ako je njegova gustoća vjerojatnosti konstantna na ovom segmentu i jednaka nuli izvan njega.
Funkcija gustoće vjerojatnosti jednoliko raspodijeljene slučajne varijable ima oblik:
Riža. 1. Dijagram gustoće jednolike distribucije
Funkcija raspodjele jednoliko raspodijeljene slučajne varijable ima oblik:
O uniformnom zakonu raspodjele govori se kada se prema uvjetima testa ili eksperimenta proučava slučajna varijabla X koja poprima vrijednosti u konačnom intervalu i sve vrijednosti iz tog intervala su jednako moguće, tj. nijedno od značenja nema prednost nad ostalima.
Na primjer:
Vrijeme čekanja na autobusnom stajalištu je slučajna varijabla X – ravnomjerno raspoređena na segmentu gdje T- interval između autobusa;
Zaokruživanje brojeva, kod zaokruživanja na cijele brojeve greška zaokruživanja je razlika između početne i zaokružene vrijednosti, a ta vrijednost je ravnomjerno raspoređena na poluinterval.
Numeričke karakteristike jednoliko raspodijeljene slučajne varijable:
2) Varijanca
Primjer 1: Interval autobusa je 20 minuta. Kolika je vjerojatnost da putnik na autobusnom stajalištu neće čekati autobus više od 6 minuta?
Riješenje: Neka je slučajna varijabla X vrijeme čekanja autobusa; jednoliko je raspoređeno na segmentu.
Prema uvjetima problema, parametri jednolike raspodjele vrijednosti X:
Po definiciji jednolike raspodjele prema formuli (2), funkcija raspodjele vrijednosti X imat će oblik:
Traženu vjerojatnost izračunavamo pomoću formule
Odgovor: Vjerojatnost da putnik neće biti u autobusu duže od 6 minuta je 0,3.
Primjer 2: Slučajna varijabla X ima jednoliku raspodjelu na segmentu. Zapišite gustoću distribucije vrijednosti X.
Riješenje:
Prema definiciji jednolike raspodjele prema formuli (1), gustoća raspodjele vrijednosti X imat će oblik:
Odgovor:.
Primjer 3: Slučajna varijabla X ima jednoliku raspodjelu na segmentu. Zapišite funkciju raspodjele vrijednosti X.
Riješenje: Kako je slučajna varijabla X jednoliko raspoređena na intervalu, tada su prema uvjetima problema parametri raspodjele vrijednosti X:
Prema definiciji jednolike raspodjele prema formuli (2), gustoća raspodjele vrijednosti X imat će oblik:
Primjer 4: Slučajna varijabla X ima jednoliku raspodjelu na segmentu. Pronađite numeričke karakteristike vrijednosti X.
Riješenje: Kako je slučajna varijabla X jednoliko raspoređena na intervalu, tada su prema uvjetima problema parametri raspodjele vrijednosti X:
Definiranjem jednolike raspodjele u skladu s formulama (3), (4) i (5), numeričke karakteristike vrijednosti X bit će sljedeće:
1) Matematičko očekivanje
2) Varijanca
3) Standardna devijacija
Odgovor:, ,
Kontinuirana slučajna varijabla X ima jednoliku distribuciju na segmentu [a, b] ako je gustoća distribucije konstantna na tom segmentu i jednaka 0 izvan njega.
Krivulja uniformne distribucije prikazana je na sl. 3.13.

Riža. 3.13.
Vrijednosti/ (X) na ekstremnim točkama A I b zaplet (a, b) nisu naznačene, budući da je vjerojatnost pogađanja bilo koje od ovih točaka za kontinuiranu slučajnu varijablu x jednako 0.
Očekivanje slučajne varijable X, ima jednoliku raspodjelu po površini [a, d], /« = (a + b)/2. Varijanca se izračunava pomoću formule D =(b- a)2/12, dakle st = (b - a)/3.464.
Modeliranje slučajnih varijabli. Da biste modelirali slučajnu varijablu, morate znati njezin zakon distribucije. Najopćenitiji način dobivanja niza slučajnih brojeva raspoređenih prema proizvoljnom zakonu je metoda koja se temelji na njihovom formiranju iz početnog niza slučajnih brojeva raspoređenih u intervalu (0; 1) prema jedinstvenom zakonu.
Ravnomjerno raspoređeno u intervalu (0; 1), nizovi slučajnih brojeva mogu se dobiti na tri načina:
- korištenje posebno pripremljenih tablica slučajnih brojeva;
- korištenje fizičkih generatora slučajnih brojeva (na primjer, bacanje novčića);
- algoritamska metoda.
Za takve brojeve matematičko očekivanje mora biti jednako 0,5, a varijanca 1/12. Ako trebate nasumični broj x bio je u intervalu ( A; b), različito od (0; 1), trebate upotrijebiti formulu X=a + (b- a)r, Gdje G- slučajni broj iz intervala (0; 1).
S obzirom na to da su gotovo svi modeli implementirani na računalu, za dobivanje slučajnih brojeva gotovo uvijek se koristi algoritamski generator (RNG) ugrađen u računalo, iako nije problem koristiti tablice koje su prethodno pretvorene u elektronički oblik. . Treba uzeti u obzir da algoritamskom metodom uvijek dobivamo pseudoslučajne brojeve, jer svaki sljedeći generirani broj ovisi o prethodnom.
U praksi je uvijek potrebno nabaviti slučajni brojevi raspoređeni prema zadanom zakonu raspodjele. Za to se koristi širok izbor metoda. Ako je poznat analitički izraz za zakon distribucije F, onda možete koristiti metoda inverzne funkcije.
Dovoljno je igrati slučajni broj jednoliko raspoređen u rasponu od 0 do 1. Budući da je funkcija F također mijenja u zadanom intervalu, zatim slučajni broj x može se odrediti uzimanjem inverzne funkcije iz grafikona ili analitički: x = F"(g). Ovdje G- broj koji generira RNG u rasponu od 0 do 1; xt- rezultirajuća slučajna varijabla. Grafički je suština metode prikazana na sl. 3.14.

Riža. 3.14. Ilustracija metode inverzne funkcije za generiranje slučajnih događaja x, čije su vrijednosti distribuirane kontinuirano. Na slici su prikazani grafovi gustoće vjerojatnosti i integralne gustoće vjerojatnosti iz x
Razmotrimo zakon eksponencijalne distribucije kao primjer. Funkcija distribucije ovog zakona ima oblik F(x) = 1 -exp(-bg). Jer G I F u ovoj metodi pretpostavlja se da su slični i da se nalaze u istom intervalu, a zatim zamjenjuju F za slučajni broj r, imamo G= 1 - exp(-bg). Iskazivanje potrebne količine x iz ovog izraza (tj. okretanjem funkcije exp()), dobivamo x = -/X? 1p(1 -G). Budući da je u statističkom smislu (1 - r) i G - to je onda ista stvar x = -UH 1p(g).
Algoritmi za modeliranje nekih uobičajenih zakona distribucije kontinuiranih slučajnih varijabli dani su u tablici. 3.10.
Na primjer, potrebno je modelirati vrijeme učitavanja, koje je raspoređeno prema normalnom zakonu. Poznato je da je prosječno trajanje učitavanja 35 minuta, a standardna devijacija realnog vremena od prosječne vrijednosti je 10 minuta. Odnosno, prema uvjetima problema t x = 35, c x= 10. Tada će se vrijednost slučajne varijable izračunati prema formuli R= ?g, gdje G. - slučajni brojevi iz RNG-a u rasponu, n = 12. Broj 12 je odabran kao dovoljno velik na temelju središnjeg graničnog teorema teorije vjerojatnosti (Lyapunovljev teorem): “Za veliki broj N slučajne varijable x s bilo kojim zakonom distribucije, njihov zbroj je slučajan broj s normalnim zakonom distribucije.” Zatim slučajna vrijednost x= o (7? - l/2) + t x = 10(7? -3) + 35.
Tablica 3.10
Algoritmi za modeliranje slučajnih varijabli
Simulacija slučajnog događaja. Slučajni događaj podrazumijeva da događaj ima nekoliko ishoda, a koji će se ishod ponovno dogoditi određuje samo njegova vjerojatnost. Odnosno, ishod se bira nasumično, uzimajući u obzir njegovu vjerojatnost. Na primjer, recimo da znamo kolika je vjerojatnost proizvodnje neispravnih proizvoda R= 0,1. Možete simulirati pojavu ovog događaja igrajući ravnomjerno raspodijeljeni slučajni broj iz raspona od 0 do 1 i određujući u koji od dva intervala (od 0 do 0,1 ili od 0,1 do 1) je pao (slika 3.15). Ako je broj unutar raspona (0; 0,1), tada je pušten neispravan proizvod, tj. dogodio se događaj, u suprotnom se događaj nije dogodio (pušten je standardni proizvod). Uz značajan broj eksperimenata, učestalost brojeva koji padaju u interval od 0 do 0,1 približit će se vjerojatnosti P= 0,1, a učestalost brojeva koji padaju u interval od 0,1 do 1 približit će se P = 0,9.

Riža. 3.15.
Događaji se zovu nekompatibilan, ako je vjerojatnost da se ti događaji dogode istovremeno jednaka 0. Slijedi da je ukupna vjerojatnost grupe nekompatibilnih događaja jednaka 1. Označimo s a r ja, a n događaja, i kroz P ]9 P 2 , ..., R str- vjerojatnost nastanka pojedinih događaja. Budući da su događaji nekompatibilni, zbroj vjerojatnosti njihovog pojavljivanja jednak je 1: P x + P 2 + ... +Pn= 1. Da bismo simulirali pojavu jednog od događaja, ponovno koristimo generator slučajnih brojeva, čija je vrijednost također uvijek u rasponu od 0 do 1. Nacrtajmo segmente na jediničnom intervalu P r P v ..., R str. Jasno je da će zbroj segmenata tvoriti točno jedinični interval. Točka koja odgovara ispuštenom broju iz generatora slučajnih brojeva na ovom intervalu će pokazivati na jedan od segmenata. Sukladno tome, slučajni brojevi će se češće pojavljivati u većim segmentima (vjerojatnost da se ti događaji dogode je veća!), au manjim segmentima - rjeđe (slika 3.16).
Po potrebi i modeliranje zajednički događaji moraju se učiniti nekompatibilnima. Na primjer, za simulaciju pojavljivanja događaja za koje su dane vjerojatnosti R(a) = 0,7; P(a 2)= 0,5 i P(a ]9 a 2)= 0,4, utvrđujemo sve moguće nekompatibilne ishode nastanka događaja a g a 2 i njihovo istovremeno pojavljivanje:
- 1. Istovremena pojava dvaju događaja P(b () = P(a L , a 2) = 0,4.
- 2. Pojava događaja a] P(b 2) = P(a y) - P(a ( , a 2) = 0,7 - 0,4 = 0,3.
- 3. Pojava događaja a 2 P(b 3) = P(a 2) - P(a g a 2) = 0,5 - 0,4 = 0,1.
- 4. Nema događaja P(b 4) = 1 - (P(b) + P(b 2) + + P(b 3)) =0,2.
Sada vjerojatnosti pojavljivanja nekompatibilnih događaja b moraju biti prikazani na brojčanoj osi u obliku segmenata. Dobivanjem brojeva pomoću RNG-a utvrđujemo njihovu pripadnost pojedinom intervalu i postižemo provedbu zajedničkih događaja A.

Riža. 3.16.
Često se susreće u praksi sustavi slučajnih varijabli, tj. takve dvije (ili više) različite slučajne varijable x, U(i drugi) koji ovise jedni o drugima. Na primjer, ako se dogodi neki događaj x i uzeo neku slučajnu vrijednost, zatim događaj U događa, iako slučajno, ali uzimajući u obzir činjenicu da x već poprimilo neko značenje.
Na primjer, ako kao x Ako se pojavi veliki broj, onda as U trebao bi se pojaviti i dovoljno veliki broj (ako je korelacija pozitivna, i obrnuto, ako je negativna). U prometu se takve ovisnosti javljaju prilično često. Dulja kašnjenja vjerojatnija su na rutama veće duljine itd.
Ako su slučajne varijable ovisne, tada
f(x)=f(x l)f(x 2 x l)f(x 3 x 2 ,x l)- ... -/(xjx, r X„ , ...,x 2 ,x t), Gdje x. | x._v x (- slučajne ovisne varijable: ispadanje X. pod uvjetom da su ispali x._ (9 x._ ( ,...,*,) - uvjetna gustoća
vjerojatnost pojave x.> ako ste ispali x._(9 ..., x (; f(x) - vjerojatnost pojavljivanja vektora x slučajnih zavisnih varijabli.
Koeficijent korelacije q pokazuje koliko su događaji blisko povezani Hee W. Ako je koeficijent korelacije jednak jedan, tada je ovisnost događaja Hee Woo jedan-na-jedan: ista vrijednost x odgovara jednoj vrijednosti U(Sl. 3.17, A) . Na q, blizu jedinici, slika prikazana na sl. 3.17, b, tj. jedna vrijednost x Nekoliko vrijednosti Y možda već odgovara (točnije, jedna od nekoliko vrijednosti Y, određena nasumično); tj. u ovom događaju x I Y manje korelirani, manje ovisni jedni o drugima.

Riža. 3.17. Vrsta ovisnosti dviju slučajnih varijabli s pozitivnim koeficijentom korelacije: a- kod q = 1; b - na 0 q na q, blizu O
I konačno, kada koeficijent korelacije teži nuli, dolazi do situacije u kojoj svaka vrijednost x može odgovarati bilo kojoj vrijednosti Y, tj. događajima x I Y neovisni ili gotovo neovisni jedni o drugima, ne koreliraju jedni s drugima (Sl. 3.17, V).
Na primjer, uzmimo normalnu distribuciju kao najčešću. Matematičko očekivanje označava najvjerojatnije događaje, ovdje je broj događaja veći i graf događaja je gušći. Pozitivna korelacija ukazuje da velike slučajne varijable x izazvati stvaranje velikih Y. Nulta i blizu nule korelacija pokazuje da je vrijednost slučajne varijable x nije ni na koji način povezan s određenom vrijednošću slučajne varijable Y. Lako je razumjeti što je rečeno ako prvo zamislimo raspodjele f(X) i/(U) odvojeno, a zatim ih povezati u sustav, kao što je prikazano na sl. 3.18.
U primjeru koji se razmatra hej Y se distribuiraju prema normalnom zakonu s pripadajućim vrijednostima t x, a i da, A,. Zadan je koeficijent korelacije dvaju slučajnih događaja q, tj. slučajne varijable x i U ovise jedno o drugom, U nije sasvim slučajno.
Tada će mogući algoritam za implementaciju modela biti sljedeći:
1. Izvučeno je šest slučajnih brojeva jednoliko raspoređenih u intervalu: b r b:, b i, b 4 , b 5, b 6 ; nalazi se njihov zbroj S:
S = b. Normalno distribuirani slučajni broj n nalazi se pomoću sljedeće formule: x = a (5 - 6) + t x.
- 2. Prema formuli t!x = da + qoJo x (x -t x) je matematičko očekivanje t y1x(znak u/x znači da će y uzeti slučajne vrijednosti, uzimajući u obzir uvjet da je * već uzeo neke specifične vrijednosti).
- 3. Prema formuli = d/l -C 2 nalazi se standardna devijacija a.
4. Izvučeno je 12 slučajnih brojeva r ravnomjerno raspoređenih u intervalu; nalazi se njihov zbroj k: k = Zr. Pronađite normalno raspodijeljeni slučajni broj na prema sljedećoj formuli: y = °Jk-6) + m r/x .

Riža. 3.18.
Modeliranje toka događaja. Kada ima mnogo događaja i oni slijede jedan za drugim, oni nastaju teći. Imajte na umu da događaji moraju biti homogeni, tj. donekle slični jedni drugima. Na primjer, pojava vozača na benzinskim postajama koji žele natočiti gorivo u svoj automobil. Odnosno, homogeni događaji čine određeni niz. Vjeruje se da su statističke karakteristike ovog 146
fenomena (intenzitet toka događaja) dat je. Intenzitet toka događaja pokazuje koliko se takvih događaja u prosjeku dogodi u jedinici vremena. No točno kada će se svaki pojedini događaj dogoditi mora se odrediti metodama modeliranja. Važno je da kada generiramo npr. 1000 događaja u 200 sati, njihov broj će biti približno jednak prosječnom intenzitetu događanja događaja 1000/200 = 5 događaja na sat. Ovo je statistička vrijednost koja karakterizira ovaj tok u cjelini.
Intenzitet toka je u određenom smislu matematičko očekivanje broja događaja u jedinici vremena. Ali u stvarnosti se može pokazati da se 4 događaja pojave u jednom satu, 6 u drugom, iako u prosjeku ima 5 događaja po satu, tako da jedna vrijednost nije dovoljna za karakterizaciju toka. Druga veličina koja karakterizira koliko je veliko širenje događaja u odnosu na matematičko očekivanje je, kao i prije, disperzija. Upravo ta vrijednost određuje slučajnost pojave događaja, slabu predvidljivost trenutka njegovog događanja.
Postoje nasumični tokovi:
- obični - vjerojatnost istodobne pojave dvaju ili više događaja jednaka je nuli;
- stacionarni - učestalost pojavljivanja događaja x trajno;
- bez naknadnog učinka - vjerojatnost nastanka slučajnog događaja ne ovisi o trenutku nastanka prethodnih događaja.
Pri modeliranju QS-a, u velikoj većini slučajeva, uzima se u obzir Poissonov (najjednostavniji) tok - običan protok bez naknadnog djelovanja, u kojem je vjerojatnost dolaska u vremenskom intervalu t glatko, nesmetano T zahtjevi su dati Poissonovom formulom:
Poissonov tok može biti stacionaran ako je A.(/) = const(/), ili nestacionaran u suprotnom slučaju.
U Poissonovom toku, vjerojatnost da se nijedan događaj ne dogodi je
Na sl. 3.19 prikazuje ovisnost R s vremena. Očito, što je duže vrijeme promatranja, to je manja vjerojatnost da se događaj neće dogoditi. Štoviše, što je vrijednost veća X,što graf ide strmije, tj. vjerojatnost se brže smanjuje. To odgovara činjenici da ako je stopa pojavljivanja događaja visoka, tada se vjerojatnost da se događaj neće dogoditi brzo smanjuje s vremenom promatranja.

Riža. 3.19.
Vjerojatnost da se dogodi barem jedan događaj P = 1 - skhr(-Ad), budući da P + P = . Očito je da vjerojatnost pojave barem jednog događaja teži jedinici u vremenu, odnosno uz odgovarajuće dugotrajno promatranje događaj će se sigurno dogoditi prije ili kasnije. U smislu R je jednako r, dakle, izražavajući / iz definicijske formule R, Konačno, da odredimo intervale između dva slučajna događaja imamo
![]()
Gdje G- slučajni broj ravnomjerno raspoređen od 0 do 1, koji se dobiva pomoću RNG-a; t- interval između slučajnih događaja (slučajna varijabla).
Kao primjer, razmotrite protok automobila koji dolaze na terminal. Automobili dolaze nasumično - u prosjeku 8 dnevno (protok x= 8/24 automobila/h). Potrebno je smo- 148
podijelite ovaj proces T= 100 sati Prosječni vremenski interval između automobila / = 1/L. = 24/8 = 3 sata.
Na sl. Slika 3.20 prikazuje rezultat simulacije - trenutke u vremenu kada su automobili stigli na terminal. Kao što se vidi, u samom razdoblju T = Obrađeno 100 terminala N=33 automobil. Onda, ako ponovno pokrenemo simulaciju N može ispasti jednako, na primjer, 34, 35 ili 32. Ali u prosjeku za DO algoritam radi N bit će jednako 33,333.
Riža. 3.20.
Ako se zna da protok nije obična tada je potrebno modelirati, osim trenutka nastanka događaja, i broj događaja koji bi se mogli dogoditi u ovom trenutku. Na primjer, automobili stižu na terminal u nasumično vrijeme (običan tok automobila). Ali u isto vrijeme, automobili mogu imati različite (nasumične) količine tereta. U ovom slučaju se o protoku tereta govori kao tok izvanrednih događaja.
Razmotrimo problem. Potrebno je utvrditi vrijeme zastoja opreme za utovar na terminalu ako se kontejneri AUK-1.25 do terminala dopremaju vozilima. Protok automobila poštuje Poissonov zakon, prosječni interval između automobila je 0,5 chD = 1/0,5 = 2 automobila/sat. Broj kontejnera u automobilu varira prema normalnom zakonu s prosječnom vrijednošću T= 6 i a = 2. U ovom slučaju minimalno može biti 2, a maksimalno 10 spremnika. Vrijeme istovara jednog kontejnera je 4 minute, a za tehnološke operacije potrebno je 6 minuta. Algoritam za rješavanje ovog problema, izgrađen na principu sekvencijalnog objavljivanja svake prijave, prikazan je na slici. 3.21.
Nakon unosa početnih podataka, ciklus simulacije počinje dok se ne postigne određeno vrijeme simulacije. Korištenjem RNG-a dobivamo slučajni broj, zatim određujemo vremenski interval prije dolaska automobila. Rezultirajući interval označavamo na vremenskoj osi i simuliramo broj kontejnera u stražnjem dijelu vozila koje dolazi.
Provjeravamo dobiveni broj za prihvatljivi interval. Zatim se računa vrijeme istovara i zbraja u brojaču ukupnog vremena rada opreme za utovar. Provjerava se uvjet: ako je interval dolaska vozila veći od vremena istovara, tada se razlika između njih zbraja u brojaču zastoja opreme.

Riža. 3.21.
Tipičan primjer za QS sustav bio bi rad utovarne točke s nekoliko stupova, kao što je prikazano na sl. 3.22.

Riža. 3.22.
Radi jasnoće procesa modeliranja, konstruirat ćemo vremenski dijagram rada QS-a, odražavajući na svakoj liniji (vremenska os /) stanje pojedinog elementa sustava (slika 3.23). Postoji onoliko vremenskih linija koliko ima različitih objekata u QS (tokovima). U našem primjeru ima ih 7: tok aplikacija, tok čekanja na prvom mjestu u redu, tok čekanja na drugom mjestu u redu, tok usluge u prvom kanalu, tok usluge u drugi kanal, tok aplikacija koje opslužuje sustav, tok odbijenih aplikacija. Kako bismo demonstrirali proces odbijanja usluge, složit ćemo se da samo dva automobila mogu biti u redu za utovar. Ako ih ima više, šalju se na drugu utovarnu točku.
Simulirani nasumični trenuci zaprimanja zahtjeva za servis automobila prikazani su u prvom retku. Prvi zahtjev se preuzima i, budući da su kanali u ovom trenutku slobodni, postavlja se na servisiranje prvog kanala. Primjena 1 prenosi se na liniju prvog kanala. Vrijeme usluge u kanalu također je slučajno. Na dijagramu nalazimo trenutak završetka usluge, odgađajući generirano vrijeme usluge od trenutka početka usluge.
niya, i spustite aplikaciju na redak "Served". Prijava je išla sve do CMO-a. Sada, po principu sekvencijalnog knjiženja naloga, možete modelirati i putanju drugog naloga.

Riža. 3.23.
Ako se u nekom trenutku ispostavi da su oba kanala zauzeta, tada zahtjev treba staviti u red čekanja. Na sl. 3.23 ovo je aplikacija 3. Imajte na umu da prema uvjetima zadatka, za razliku od kanala, zahtjevi nisu u redu čekanja nasumično vrijeme, već čekaju da se jedan od kanala oslobodi. Nakon oslobađanja kanala, zahtjev se podiže na liniju odgovarajućeg kanala i tamo se organizira njegovo servisiranje.
Ako je težina mjesta u redu čekanja u trenutku pristizanja sljedeće prijave zauzeta, tada prijavu treba poslati u redak “Odbijeno”. Na sl. 3.23 ovo je aplikacija 6.
Procedura simulacije servisiranja aplikacije traje još neko vrijeme. T. Što je ovo vrijeme dulje, to će rezultati simulacije biti precizniji u budućnosti. U stvarnosti, za jednostavne sustave oni biraju T, jednako 50-100 sati ili više, iako je ponekad bolje izmjeriti ovu vrijednost prema broju pregledanih aplikacija.
Analizirat ćemo QS pomoću primjera o kojem smo već raspravljali.
Prvo morate pričekati stabilno stanje. Prva četiri zahtjeva odbacujemo kao nekarakteristična, koja se javljaju tijekom procesa uspostave rada sustava (“vrijeme zagrijavanja modela”). Mjerimo vrijeme promatranja, pretpostavimo da je u našem primjeru G = 5 sati. Broj servisiranih aplikacija izračunavamo iz dijagrama N o6c, vrijeme mirovanja i druge vrijednosti. Kao rezultat toga, možemo izračunati pokazatelje koji karakteriziraju kvalitetu rada QS-a:
- 1. Vjerojatnost usluge R = N,/N= 5/7 = 0,714. Da bi se izračunala vjerojatnost servisiranja aplikacije u sustavu, dovoljno je podijeliti broj aplikacija koje su uspjele biti opslužene kroz vrijeme T(pogledajte redak “Served”), L/o6s za broj aplikacija N, koji je stigao u isto vrijeme.
- 2. Propusnost sustava A = NJT h = 7/5 = 1,4 automobila/sat. Za izračun kapaciteta sustava dovoljno je podijeliti broj opsluženih zahtjeva N o6c neko vrijeme T, za koje se ova usluga dogodila.
- 3. Vjerojatnost neuspjeha P = N /N = 3/7 = 0,43. Da bi se izračunala vjerojatnost da zahtjev bude odbijen, dovoljno je podijeliti broj zahtjeva N koji su odbijeni tijekom T(pogledajte redak „Odbijeno”), po broju prijava N, koji su htjeli biti usluženi za isto vrijeme, tj. ušli u sustav. Imajte na umu da iznos R op + R p(k u teoriji bi trebao biti jednak 1. Zapravo, eksperimentalno se pokazalo da R + R.= 0,714 + 0,43 = 1,144. Ta se netočnost objašnjava činjenicom da je tijekom razdoblja promatranja T Nije prikupljeno dovoljno statistike da bi se dobio točan odgovor. Pogreška ovog pokazatelja sada iznosi 14%.
- 4. Vjerojatnost popunjenosti jednog kanala R = T r JT H= 0,05/5 = 0,01, gdje je T- zauzetost samo jednog kanala (prvog ili drugog). Vremenski intervali u kojima se događaju određeni događaji podliježu mjerenju. Na primjer, dijagram traži segmente kada su prvi ili drugi kanal zauzeti. U ovom primjeru postoji jedan takav segment na kraju dijagrama, dug 0,05 sati.
- 5. Vjerojatnost zauzetosti dvaju kanala P = T / T = 4,95/5 = 0,99. Dijagram traži segmente tijekom kojih su i prvi i drugi kanal zauzeti u isto vrijeme. U ovom primjeru postoje četiri takva segmenta, njihov zbroj je 4,95 sati.
- 6. Prosječan broj zauzetih kanala: /V do - 0 P 0 + P X + 2 P, = = 0,01 +2? 0,99= 1,99. Za izračunavanje koliko je kanala u prosjeku zauzeto u sustavu dovoljno je znati udio (vjerojatnost zauzetosti jednog kanala) i pomnožiti s težinom tog udjela (jedan kanal), znati udio (vjerojatnost zauzetosti dva kanala) i pomnožite s težinom tog udjela (dva kanala) itd. Dobivena brojka od 1,99 označava da je od dva moguća kanala u prosjeku učitano 1,99 kanala. Ovo je visoka stopa opterećenja, 99,5%, sustav dobro koristi resurse.
- 7. Vjerojatnost zastoja barem jednog kanala P*, = G jednostavan,/G = = 0,05/5 = 0,01.
- 8. Vjerojatnost zastoja dva kanala istovremeno: P = = T JT = 0.
- 9. Vjerojatnost zastoja cijelog sustava P* =T /T = 0.
- 10. Prosječan broj prijava u redu čekanja /V z = 0 P(h + 1 R i + 2Rʺ= = 0,34 + 2 0,64 = 1,62 auto. Za određivanje prosječnog broja prijava u redu potrebno je posebno odrediti vjerojatnost da će u redu biti jedna aplikacija P, vjerojatnost da će u redu biti dvije aplikacije P 23 itd., te ih zbrojiti. opet s odgovarajućim utezima.
- 11. Vjerojatnost da će u redu biti jedna aplikacija je P i = = TJTn= 1,7/5 = 0,34 (u dijagramu postoje četiri takva segmenta, što ukupno daje 1,7 sati).
- 12. Vjerojatnost da će dvije aplikacije biti u redu čekanja u isto vrijeme je R ʺ= G 2z /G = 3,2/5 = 0,64 (u dijagramu postoje tri takva segmenta, što ukupno daje 3,25 sati).
- 13. Prosječno vrijeme čekanja aplikacije u redu čekanja je G roz = 1,7/4 = 0,425 sati.Potrebno je zbrojiti sve vremenske intervale u kojima je neka prijava bila u redu čekanja i podijeliti s brojem prijava. Na vremenskom dijagramu postoje 4 takva zahtjeva.
- 14. Prosječno vrijeme servisiranja aplikacije 7’ srobsl = 8/5 = 1,6 sati Zbrojite sve vremenske intervale tijekom kojih je bilo koja aplikacija bila opslužena u bilo kojem kanalu i podijelite s brojem aplikacija.
- 15. Prosječno vrijeme koje aplikacija ostaje u sustavu: T = T +
g g prosj. pjevana sri cool
Ako točnost nije zadovoljavajuća, potrebno je produžiti vrijeme eksperimenta i time poboljšati statistiku. Možete to učiniti drugačije ako nekoliko puta pokrenete eksperiment 154
neko vrijeme T a potom prosječne vrijednosti ovih eksperimenata, a zatim ponovno provjerite rezultate prema kriteriju točnosti. Ovaj postupak treba ponavljati dok se ne postigne potrebna točnost.
Analiza rezultata simulacije
Tablica 3.11
|
Indeks |
Značenje indikator |
Interesi vlasnika CMO-a |
Interesi klijenata |
|
Vjerojatnost servis |
Vjerojatnost usluge je niska, mnogi klijenti napuštaju sustav bez usluge Preporuka: povećajte vjerojatnost usluge |
Vjerojatnost usluge je mala, svaki treći klijent želi biti uslužen, ali ne može Preporuka: povećati vjerojatnost usluge |
|
|
Prosječan broj prijava u redu |
Gotovo uvijek prije servisa auto čeka u redu. Preporuka: povećati broj mjesta u redu, povećati propusnost |
||
|
Povećajte propusnost Povećajte broj mjesta u redu kako ne biste izgubili potencijalne kupce |
Korisnici su zainteresirani za značajno povećanje propusnosti kako bi se smanjilo kašnjenje i ispadanje |
Za odluku o provedbi konkretnih aktivnosti potrebno je provesti analizu osjetljivosti modela. Cilj analiza osjetljivosti modela je utvrditi moguća odstupanja u izlaznim karakteristikama zbog promjena ulaznih parametara.
Metode za procjenu osjetljivosti simulacijskog modela slične su metodama za određivanje osjetljivosti bilo kojeg sustava. Ako izlazna karakteristika modela R ovisi o parametrima povezanim s promjenjivim veličinama R =/(r g r 2, r), zatim promjene u ovim
parametri D r.(/ = 1, ..G) izazvati promjenu AR.

U ovom slučaju analiza osjetljivosti modela svodi se na proučavanje funkcije osjetljivosti dR/itd.
Kao primjer analize osjetljivosti simulacijskog modela, razmotrimo utjecaj promjene varijabilnih parametara pouzdanosti vozila na radnu učinkovitost. Kao funkciju cilja koristimo pokazatelj smanjenih troškova Zir. Za analizu osjetljivosti koristimo podatke o radu cestovnog vlaka KamAZ-5410 u gradskim uvjetima. Granice promjene parametara R. za određivanje osjetljivosti modela dovoljno ju je odrediti ekspertnim putem (tablica 3.12).
Za izračune pomoću modela odabrana je osnovna točka u kojoj različiti parametri imaju vrijednosti koje odgovaraju standardima. Parametar trajanja zastoja prilikom održavanja i popravaka u danima zamijenjen je specifičnim pokazateljem - zastoj u danima na tisuću kilometara N.
Rezultati proračuna prikazani su na sl. 3.24. Osnovna točka je na sjecištu svih krivulja. Prikazano na sl. 3.24 ovisnosti omogućuju nam da utvrdimo stupanj utjecaja svakog od parametara koji se razmatraju na veličinu promjene u 3. U isto vrijeme, korištenje prirodnih vrijednosti analiziranih veličina ne dopušta nam da uspostavimo usporedne stupanj utjecaja svakog parametra na 3, budući da ti parametri imaju različite mjerne jedinice. Da bismo to prevladali, odabrat ćemo oblik tumačenja rezultata izračuna u relativnim jedinicama. Da biste to učinili, baznu točku morate pomaknuti u ishodište koordinata, a vrijednosti promjenjivih parametara i relativne promjene izlaznih karakteristika modela moraju biti izražene u postocima. Rezultati provedenih transformacija prikazani su na sl. 3.25.
Tablica 3.12
Vrijednosti varijabilni parametri

Riža. 3.24.

Riža. 3.25. Utjecaj relativne promjene variranih parametara na stupanj promjene u
Promjena varijabilnih parametara u odnosu na baznu vrijednost prikazana je na jednoj osi. Kao što se može vidjeti sa Sl. 3.25, povećanje vrijednosti svakog parametra u blizini bazne točke za 50% dovodi do povećanja Zpr za 9% povećanja Ta, za više od 1,5% od C p, za manje od 0,5% od N a na smanjenje od 3 za gotovo 4% povećanja L. Smanji za 25 % b cr i D rg dovodi do povećanja Z pr, odnosno, za više od 6%. Smanjenje parametara za isti iznos N t0, P a g e dovodi do smanjenja Zpr za 0,2, 0,8 odnosno 4,5%.
Navedene ovisnosti daju predodžbu o utjecaju pojedinog parametra i mogu se koristiti pri planiranju rada transportnog sustava. Prema intenzitetu utjecaja na okoliš promatrani parametri mogu se poredati sljedećim redom: D, II, L, C 9 N .
’a 7 k.r 7 t.r 7 t.o
Tijekom rada promjena vrijednosti jednog pokazatelja povlači za sobom promjenu vrijednosti drugih pokazatelja, a relativna promjena svakog od variranih parametara za istu vrijednost u općem slučaju ima nejednaku fizičku osnovu. Relativnu promjenu vrijednosti variranih parametara u postocima duž apscisne osi potrebno je zamijeniti parametrom koji može poslužiti kao jedinstvena mjera za ocjenu stupnja promjene svakog parametra. Može se pretpostaviti da u svakom trenutku rada vozila vrijednost svakog parametra ima istu ekonomsku težinu u odnosu na vrijednosti ostalih varijabilnih parametara, odnosno, ekonomski gledano, pouzdanost vozila u svakom trenutku vremena ima ravnotežni učinak na sve parametre povezane s njim. Tada će traženi ekonomski ekvivalent biti vrijeme ili, zgodnije, godina rada.
Na sl. Slika 3.26 prikazuje ovisnosti izgrađene u skladu s gornjim zahtjevima. Kao bazna vrijednost Zpr uzima se vrijednost u prvoj godini rada vozila. Vrijednosti varijabilnih parametara za svaku godinu rada određene su na temelju rezultata promatranja.

Riža. 3.26.
Tijekom rada, povećanje Zpr tijekom prve tri godine prvenstveno je posljedica porasta vrijednosti H jo, a zatim, u razmatranim uvjetima rada, glavnu ulogu u smanjenju učinkovitosti korištenja vozila ima povećanje vrijednosti C pp. Kako bi se utvrdio utjecaj količine LKp, u izračunima je njegova vrijednost izjednačena s ukupnom kilometražom vozila od početka rada. Vrsta funkcije 3 =f(L) pokazuje da je intenzitet opadanja 3 s porastom
itd J v k.r" 7 n.p. J
1 do r značajno se smanjuje.
Kao rezultat analize osjetljivosti modela, moguće je razumjeti na koje čimbenike treba utjecati da bi se promijenila funkcija cilja. Za promjenu faktora potrebni su napori kontrole, što je povezano s odgovarajućim troškovima. Visina troškova ne može biti beskonačna, kao i svaki resurs, ti su troškovi u stvarnosti ograničeni. Stoga je potrebno razumjeti u kojoj će mjeri raspodjela sredstava biti učinkovita. Ako u većini slučajeva troškovi rastu linearno s povećanjem kontrolnog djelovanja, tada učinkovitost sustava brzo raste samo do određene granice, kada čak i značajni troškovi više ne daju isti povrat. Na primjer, nemoguće je neograničeno povećavati snagu servisnih uređaja zbog ograničenja prostora ili potencijalnog broja servisiranih vozila i sl.
Ako usporedimo povećanje troškova i pokazatelj učinkovitosti sustava u istim jedinicama, tada će, u pravilu, grafički izgledati kao što je prikazano na Sl. 3.27.

Riža. 3.27.
Od sl. 3.27 jasno je da kada se dodjeljuje cijena C, po jedinici troška Z i cijena C, po jedinici pokazatelja R ove krivulje se mogu dodati. Krivulje se dodaju ako ih je potrebno istovremeno minimizirati ili maksimizirati. Ako jednu krivulju treba maksimizirati, a drugu minimizirati, tada njihovu razliku treba pronaći, na primjer, po točkama. Tada će rezultirajuća krivulja (slika 3.28), koja uzima u obzir i učinak upravljanja i troškove toga, imati ekstremum. Vrijednost parametra /?, koja daje ekstrem funkcije, je rješenje problema sinteze.

Riža. 3.28.
do...
Osim upravljanja R i indikator R postoji poremećaj u sustavima. Smetnja D= (d v d r...) je ulazni utjecaj, koji za razliku od regulacijskog parametra ne ovisi o volji vlasnika sustava (slika 3.29). Primjerice, niske temperature vani i konkurencija, nažalost, smanjuju protok kupaca; Kvarovi opreme smanjuju performanse sustava. Vlasnik sustava ne može izravno kontrolirati te količine. Obično, ogorčenje djeluje "u inat" vlasniku, smanjujući učinak R od nastojanja kontrole R. To se događa jer je sustav općenito stvoren za postizanje ciljeva koji su u prirodi sami po sebi nedostižni. Osoba koja organizira sustav uvijek se nada da će kroz njega postići neki cilj R. Ulaže trud u ovo R. U tom kontekstu, možemo reći da je sustav organizacija prirodnih komponenti dostupnih čovjeku i koje on proučava radi postizanja nekog novog cilja, prethodno nedostižnog drugim sredstvima.

Riža. 3.29.
Ako uklonimo ovisnost indikatora R od uprave R opet, ali pod uvjetima pojavljivanja poremećaja D, tada će se možda priroda krivulje promijeniti. Najvjerojatnije će indikator biti niži za iste kontrolne vrijednosti, budući da je smetnja negativna, smanjujući performanse sustava. Sustav prepušten sam sebi, bez upravljačkih napora, prestaje ostvarivati cilj za koji je stvoren. Ako, kao i prije, konstruiramo ovisnost troškova i koreliramo je s ovisnošću indikatora o kontrolnom parametru, tada će se pronađena ekstremna točka pomaknuti (slika 3.30) u usporedbi sa slučajem "poremećaj = 0" (vidi sliku 3.28). Ako se poremećaj ponovno poveća, krivulje će se promijeniti i, kao posljedica toga, ponovno će se promijeniti položaj točke ekstrema.
Grafikon na sl. 3.30 povezuje indikator P, upravljanje (resurs) R i ogorčenje D u složenim sustavima, ukazujući na to kako najbolje djelovati za menadžera (organizaciju) koji donosi odluke u sustavu. Ako je kontrolno djelovanje manje od optimalnog, ukupni učinak će se smanjiti i doći će do situacije izgubljene dobiti. Ako je kontrolna radnja veća od optimalne, tada će se i učinak smanjiti, budući da je plaćanje reda 162
Daljnje povećanje napora u kontroli morat će biti veće od onoga što ćete dobiti kao rezultat korištenja sustava.

Riža. 3.30.
Simulacijski model sustava za stvarnu uporabu mora biti implementiran na računalu. To se može izraditi pomoću sljedećih alata:
- univerzalni korisnički program kao što je matematički (MATLAB) ili procesor za proračunske tablice (Excel) ili DBMS (Access, FoxPro), koji vam omogućuje stvaranje samo relativno jednostavnog modela i zahtijeva barem osnovne vještine programiranja;
- univerzalni programski jezik(C++, Java, Basic, itd.), koji vam omogućuje stvaranje modela bilo koje složenosti; ali ovo je vrlo radno intenzivan proces koji zahtijeva pisanje velike količine programskog koda i dugotrajno uklanjanje pogrešaka;
- specijalizirani simulacijski jezik, koji ima gotove predloške i alate za vizualno programiranje dizajnirane za brzo stvaranje osnove modela. Jedan od najpoznatijih je UML (Unified Modeling Language);
- simulacijski programi, koji su najpopularniji način stvaranja simulacijskih modela. Omogućuju vam vizualno stvaranje modela, samo u najsloženijim slučajevima pribjegavajući ručnom pisanju programskog koda za postupke i funkcije.
Programi za simulaciju dijele se u dvije vrste:
- Univerzalni simulacijski paketi dizajnirani su za stvaranje različitih modela i sadrže skup funkcija koje se mogu koristiti za simulaciju tipičnih procesa u sustavima za različite namjene. Popularni paketi ove vrste su Arena (razvio Rockwell Automation 1", SAD), Extendsim (razvio Imagine That Ink., SAD), AnyLogic (razvio XJ Technologies, Rusija) i mnogi drugi. Gotovo svi univerzalni paketi imaju specijalizirane verzije za modeliranje specifičnih objekata klasa.
- Simulacijski paketi specifični za domenu služe za modeliranje određenih vrsta objekata i za to imaju specijalizirane alate u obliku predložaka, čarobnjaka za vizualno oblikovanje modela iz gotovih modula itd.
- Naravno, dva slučajna broja ne mogu jedinstveno ovisiti jedan o drugome, sl. 3.17 dan je radi jasnoće koncepta korelacije. 144
- Tehničko-ekonomska analiza u proučavanju pouzdanosti vozila KamAZ-5410 /Yu. G. Kotikov, I. M. Blankinshtein, A. E. Gorev, A. N. Borisenko; LISI. L.:, 1983. 12 str.-Dep. u CBNTI Ministarstva autotransporta RSFSR-a, br. 135at-D83.
- http://www.rockwellautomation.com.
- http://www.cxtcndsiin.com.
- http://www.xjtek.com.