Vjerojatnost normalno raspodijeljene slučajne varijable. Zakon normalne distribucije vjerojatnosti za kontinuiranu slučajnu varijablu. Odnos s drugim distribucijama
Zamjena φ(x)=π /4 ,f(x)=1/(b-a)
D[π /4]=( /720) ).
№319 rub kocke x mjereno približno, i a . Promatrajući rub kocke kao slučajnu varijablu X, ravnomjerno raspoređenu u intervalu (a, b), pronađite matematičko očekivanje i varijancu volumena kocke.
1. Nađimo matematičko očekivanje površine kruga – slučajne varijable Y=φ(K)= - prema formuli
M[φ(X)]= ![]()
Postavljanjem φ(x)= ,f(x)=1/(b-a) i izvođenje integracije, dobivamo
M( )=
 .
.
2. Pronađite disperziju površine kruga pomoću formule
D [φ(X)]= ![]() -
-
![]() .
.
Zamjena φ(x)= ,f(x)=1/(b-a) i izvođenje integracije, dobivamo
D =
 .
.
№320 Slučajne varijable X i Y su neovisne i ravnomjerno raspoređene: X u intervalu (a, b), Y u intervalu (c, d) Nađite matematičko očekivanje umnoška XY.
Matematičko očekivanje umnoška nezavisnih slučajnih varijabli jednako je umnošku njihovih matematičkih očekivanja, tj.
M(XY)= 
№321 Slučajne varijable X i Y su neovisne i ravnomjerno raspoređene: X u intervalu (a,b), Y u intervalu (c,d). Pronađite varijancu umnoška XY.
Upotrijebimo formulu
D(XY)=M[
Matematičko očekivanje umnoška nezavisnih slučajnih varijabli jednako je umnošku njihovih matematičkih očekivanja, dakle
Nađimo M pomoću formule
M[φ(X)]= ![]()
Zamjena φ(x)= ,f(x)=1/(b-a) i izvođenje integracije, dobivamo
M (**)
Slično možemo pronaći
M (***)
Zamjena M(X)=(a+b)/2, M(Y)=(c+d)/2, kao i (***) i (**) u (*), konačno dobivamo
D(XY)= -[
![]() .
.
№322 Matematičko očekivanje normalno distribuirane slučajne varijable X je a=3, a standardna devijacija σ=2. Napišite gustoću vjerojatnosti X.
Upotrijebimo formulu:
f(x)=  .
.
Zamjenom dostupnih vrijednosti dobivamo:
f(x)=  =f(x)=
=f(x)=  .
.
№323 Napišite gustoću vjerojatnosti normalno distribuirane slučajne varijable X, znajući da je M(X)=3, D(X)=16.
Upotrijebimo formulu:
f(x)= .
Kako bismo pronašli vrijednost σ, koristimo svojstvo da standardna devijacija slučajne varijable x jednak kvadratnom korijenu njegove varijance. Stoga je σ=4, M(X)=a=3. Zamjenom u formulu dobivamo
f(x)=  =
=
 .
.
№324 Normalno distribuirana slučajna varijabla X dana je gustoćom
f(x)= ![]() .
Pronađite matematičko očekivanje i varijancu X.
.
Pronađite matematičko očekivanje i varijancu X.
Upotrijebimo formulu
f(x)= ,
Gdje a-očekivana vrijednost, σ - standardna devijacija X. Iz ove formule slijedi da a=M(X)=1. Da bismo pronašli varijancu, koristimo svojstvo standardne devijacije slučajne varijable x jednak kvadratnom korijenu njegove varijance. Stoga D(X)= =
Odgovor: matematičko očekivanje je 1; varijanca je 25.
Bondarčuk Rodion
S obzirom na funkciju distribucije normaliziranog normalnog zakona ![]() . Nađite gustoću distribucije f(x).
. Nađite gustoću distribucije f(x).
Znajući da ![]() , pronađite f(x).
, pronađite f(x).

Odgovor: ![]()
Dokažite da Laplaceova funkcija ![]() . neparan:
. neparan: ![]() .
.

Napravit ćemo zamjenu


Radimo obrnutu zamjenu i dobivamo:
![]() =
= ![]() =
=


Bit će tu i problema koje ćete sami riješiti, a na koje možete vidjeti odgovore.
Normalna razdioba: teorijske osnove
Primjeri slučajnih varijabli raspoređenih prema normalnom zakonu su visina osobe i masa ulovljene ribe iste vrste. Normalna raspodjela znači sljedeće : postoje vrijednosti ljudske visine, mase ribe iste vrste, koje se intuitivno percipiraju kao "normalne" (a zapravo, prosječne), au dovoljno velikom uzorku nalaze se puno češće od onih koje razlikuju prema gore ili prema dolje.
Normalna distribucija vjerojatnosti kontinuirane slučajne varijable (ponekad Gaussova distribucija) može se nazvati zvonastom zbog činjenice da je funkcija gustoće ove distribucije, simetrična u odnosu na srednju vrijednost, vrlo slična rezu zvona (crvena krivulja na gornjoj slici).
Vjerojatnost da naiđemo na određene vrijednosti u uzorku jednaka je površini figure ispod krivulje, au slučaju normalne distribucije to vidimo ispod vrha "zvona", što odgovara vrijednostima težeći prosjeku, površina, a time i vjerojatnost, veća je nego ispod rubova. Dakle, dobivamo isto što je već rečeno: vjerojatnost da ćete sresti osobu "normalne" visine i uhvatiti ribu "normalne" težine je veća nego za vrijednosti koje se razlikuju prema gore ili dolje. U mnogim praktičnim slučajevima, pogreške mjerenja raspoređene su prema zakonu bliskom normalnom.
Pogledajmo ponovno sliku na početku lekcije koja prikazuje funkciju gustoće normalne distribucije. Graf ove funkcije dobiven je izračunom određenog uzorka podataka u programskom paketu STATISTICA. Na njemu stupci histograma predstavljaju intervale uzorkovanih vrijednosti čija je distribucija bliska (ili, kako se u statistici obično kaže, ne razlikuje se bitno od) stvarnog grafa funkcije gustoće normalne distribucije, a to je crvena krivulja . Grafikon pokazuje da je ova krivulja doista u obliku zvona.
Normalna distribucija je vrijedna na mnogo načina jer znajući samo očekivanu vrijednost kontinuirane slučajne varijable i njezinu standardnu devijaciju, možete izračunati bilo koju vjerojatnost povezanu s tom varijablom.
Normalna distribucija također ima prednost jer je jedna od najjednostavnijih za korištenje. statistički testovi koji se koriste za provjeru statističkih hipoteza – Studentov t test- može se koristiti samo ako se uzorci podataka pridržavaju normalnog zakona distribucije.
Funkcija gustoće normalne distribucije kontinuirane slučajne varijable može se pronaći pomoću formule:
 ,
,
Gdje x- vrijednost promjenjive količine, - prosječna vrijednost, - standardna devijacija, e=2,71828... - baza prirodnog logaritma, =3,1416...
Svojstva funkcije gustoće normalne distribucije
Promjene srednje vrijednosti pomiču normalnu krivulju funkcije gustoće prema osi Vol. Ako se povećava, krivulja se pomiče udesno, ako se smanjuje, onda ulijevo.
Ako se standardna devijacija mijenja, mijenja se visina vrha krivulje. Kada standardna devijacija raste, vrh krivulje je viši, a kada se smanjuje, niži je.
Vjerojatnost normalno raspodijeljene slučajne varijable koja pada unutar zadanog intervala
Već u ovom odlomku počet ćemo rješavati praktične probleme čije je značenje naznačeno u naslovu. Pogledajmo koje mogućnosti pruža teorija za rješavanje problema. Početni koncept za izračunavanje vjerojatnosti da normalno distribuirana slučajna varijabla padne u zadani interval je kumulativna funkcija normalne distribucije.
Funkcija kumulativne normalne distribucije:
 .
.
Međutim, problematično je dobiti tablice za svaku moguću kombinaciju srednje vrijednosti i standardne devijacije. Stoga je jedan od jednostavnih načina za izračunavanje vjerojatnosti da normalno distribuirana slučajna varijabla padne u zadani interval korištenje tablica vjerojatnosti za standardiziranu normalnu distribuciju.
Normalna distribucija naziva se standardizirana ili normalizirana., čija je sredina , a standardna devijacija je .
Standardizirana funkcija gustoće normalne distribucije:
![]() .
.
Kumulativna funkcija standardizirane normalne distribucije:
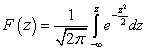 .
.
Na slici ispod prikazana je integralna funkcija standardizirane normalne distribucije čiji je graf dobiven izračunavanjem određenog uzorka podataka u programskom paketu STATISTICA. Sam grafikon je crvena krivulja, a vrijednosti uzorka joj se približavaju.

Da biste povećali sliku, kliknite na nju lijevom tipkom miša.
Standardiziranje slučajne varijable znači prelazak s izvornih jedinica korištenih u zadatku na standardizirane jedinice. Normiranje se provodi prema formuli
U praksi su sve moguće vrijednosti slučajne varijable često nepoznate, pa se vrijednosti srednje i standardne devijacije ne mogu točno odrediti. Zamijenjeni su aritmetičkom sredinom opažanja i standardnom devijacijom s. Veličina z izražava odstupanja vrijednosti slučajne varijable od aritmetičke sredine pri mjerenju standardnih odstupanja.
Otvoreni interval
Tablica vjerojatnosti za standardiziranu normalnu distribuciju, koja se može naći u gotovo svakoj knjizi o statistici, sadrži vjerojatnosti da slučajna varijabla ima standardnu normalnu distribuciju Zće imati vrijednost manju od određenog broja z. To jest, pasti će u otvoreni interval od minus beskonačnosti do z. Na primjer, vjerojatnost da količina Z manje od 1,5, jednako 0,93319.
Primjer 1. Tvrtka proizvodi dijelove čiji je životni vijek normalno raspoređen s prosjekom od 1000 sati i standardnom devijacijom od 200 sati.
Za nasumično odabrani dio izračunajte vjerojatnost da će njegov radni vijek biti najmanje 900 sati.
Riješenje. Uvedimo prvu oznaku:
Željena vjerojatnost.
Vrijednosti slučajne varijable su u otvorenom intervalu. Ali znamo kako izračunati vjerojatnost da će slučajna varijabla poprimiti vrijednost manju od zadane, a prema uvjetima problema trebamo pronaći onu koja je jednaka ili veća od zadane. Ovo je drugi dio prostora ispod normalne krivulje gustoće (zvono). Dakle, da biste pronašli željenu vjerojatnost, potrebno je od jedinice oduzeti spomenutu vjerojatnost da će slučajna varijabla poprimiti vrijednost manju od navedenih 900:
Sada slučajnu varijablu treba standardizirati.
Nastavljamo s uvođenjem oznake:
z = (x ≤ 900) ;
x= 900 - navedena vrijednost slučajne varijable;
μ = 1000 - prosječna vrijednost;
σ = 200 - standardna devijacija.
Pomoću ovih podataka dobivamo uvjete problema:
![]() .
.
Prema tablicama standardizirane slučajne varijable (granica intervala) z= −0,5 odgovara vjerojatnosti od 0,30854. Oduzmite ga od jedinice i dobijete ono što se traži u izjavi problema:
Dakle, vjerojatnost da će dio imati životni vijek od najmanje 900 sati je 69%.
Ova vjerojatnost se može dobiti pomoću MS Excel funkcije NORM.DIST (integralna vrijednost - 1):
P(x≥900) = 1 - P(x≤900) = 1 - NORM.DIST(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
O izračunima u MS Excelu - u jednom od sljedećih odlomaka ove lekcije.
Primjer 2. U određenom gradu prosječni godišnji obiteljski dohodak je normalno raspodijeljena slučajna varijabla sa sredinom od 300 000 i standardnom devijacijom od 50 000. Poznato je da je prihod 40% obitelji manji od A. Pronađite vrijednost A.
Riješenje. U ovom problemu, 40% nije ništa drugo nego vjerojatnost da će slučajna varijabla uzeti vrijednost iz otvorenog intervala koja je manja od određene vrijednosti, označene slovom A.
Da biste pronašli vrijednost A, prvo sastavljamo integralnu funkciju:
![]()
Prema uvjetima problema
μ = 300000 - prosječna vrijednost;
σ = 50000 - standardna devijacija;
x = A- količina koju treba pronaći.
Izmišljanje jednakosti
![]() .
.
Iz statističkih tablica nalazimo da vjerojatnost od 0,40 odgovara vrijednosti granice intervala z = −0,25 .
Dakle, mi stvaramo jednakost
![]()
i pronaći njegovo rješenje:
A = 287300 .
Odgovor: 40% obitelji ima prihode manje od 287.300.
Zatvoreni interval
U mnogim problemima potrebno je pronaći vjerojatnost da će normalno distribuirana slučajna varijabla uzeti vrijednost u intervalu od z 1 do z 2. Odnosno, pasti će u zatvoreni interval. Za rješavanje takvih problema potrebno je u tablici pronaći vjerojatnosti koje odgovaraju granicama intervala, a zatim pronaći razliku između tih vjerojatnosti. To zahtijeva oduzimanje manje vrijednosti od veće. Primjeri rješenja ovih uobičajenih problema su sljedeći, a od vas se traži da ih sami riješite, a zatim možete vidjeti točna rješenja i odgovore.
Primjer 3. Dobit poduzeća za određeno razdoblje je slučajna varijabla podložna normalnom zakonu raspodjele s prosječnom vrijednošću od 0,5 milijuna. a standardna devijacija 0,354. Odredite, s točnošću od dva decimalna mjesta, vjerojatnost da će dobit poduzeća biti od 0,4 do 0,6 c.u.
Primjer 4. Duljina proizvedenog dijela je slučajna varijabla raspoređena prema normalnom zakonu s parametrima μ =10 i σ =0,071. Odredite vjerojatnost nedostataka, točno na dvije decimale, ako dopuštene dimenzije dijela moraju biti 10±0,05.
Savjet: u ovom problemu, osim pronalaženja vjerojatnosti da slučajna varijabla padne u zatvoreni interval (vjerojatnost primanja nedefektnog dijela), trebate izvršiti još jednu radnju.

omogućuje određivanje vjerojatnosti da standardizirana vrijednost Z ne manje -z i nema više +z, Gdje z- proizvoljno odabrana vrijednost standardizirane slučajne varijable.
Približna metoda za provjeru normalnosti distribucije
Približna metoda za provjeru normalnosti distribucije vrijednosti uzorka temelji se na sljedećem svojstvo normalne distribucije: koeficijent asimetrije β 1 i koeficijent kurtoze β 2 jednaki su nuli.
Koeficijent asimetrije β 1 numerički karakterizira simetriju empirijske distribucije u odnosu na srednju vrijednost. Ako je koeficijent asimetrije nula, tada su aritmetrijska sredina, medijan i mod jednaki: a krivulja gustoće distribucije je simetrična u odnosu na srednju vrijednost. Ako je koeficijent asimetrije manji od nule (β 1 < 0 ), tada je aritmetička sredina manja od medijana, a medijan je zauzvrat manji od mode () i krivulja je pomaknuta udesno (u usporedbi s normalnom distribucijom). Ako je koeficijent asimetrije veći od nule (β 1 > 0 ), tada je aritmetička sredina veća od medijana, a medijan je zauzvrat veći od modusa () i krivulja je pomaknuta ulijevo (u usporedbi s normalnom distribucijom).
Kurtosis koeficijent β 2 karakterizira koncentraciju empirijske distribucije oko aritmetičke sredine u smjeru osi Joj i stupanj vrha krivulje gustoće distribucije. Ako je koeficijent kurtoze veći od nule, tada je krivulja više izdužena (u usporedbi s normalnom distribucijom) duž osi Joj(graf je šiljatiji). Ako je koeficijent kurtoze manji od nule, tada je krivulja spljoštenija (u usporedbi s normalnom distribucijom) duž osi Joj(graf je tuplji).
Koeficijent asimetrije može se izračunati pomoću funkcije MS Excel SKOS. Ako provjeravate jedan niz podataka, morate unijeti raspon podataka u jedan okvir "Broj".

Koeficijent kurtoze može se izračunati pomoću funkcije MS Excel KURTESS. Kod provjere jednog niza podataka također je dovoljno unijeti raspon podataka u jedno polje “Broj”.

Dakle, kao što već znamo, s normalnom distribucijom koeficijenti asimetrije i kurtoze jednaki su nuli. Ali što ako imamo koeficijente asimetrije od -0,14, 0,22, 0,43 i koeficijente kurtoze od 0,17, -0,31, 0,55? Pitanje je sasvim pošteno, jer u praksi imamo posla samo s približnim, oglednim vrijednostima asimetrije i kurtoze, koje su podložne nekom neizbježnom, nekontroliranom rasipanju. Stoga se ne može zahtijevati da ti koeficijenti budu striktno jednaki nuli, oni moraju biti samo dovoljno blizu nule. Ali što znači dovoljno?
Potrebno je usporediti dobivene empirijske vrijednosti s prihvatljivim vrijednostima. Da biste to učinili, morate provjeriti sljedeće nejednakosti (usporedite vrijednosti koeficijenata modula s kritičnim vrijednostima - granicama područja testiranja hipoteze).
Za koeficijent asimetrije β 1 .
U praksi se najčešće susreće normalni zakon raspodjele. Glavna značajka koja ga razlikuje od drugih zakona je da je to ograničavajući zakon, kojem se drugi zakoni raspodjele približavaju pod vrlo uobičajenim tipičnim uvjetima.
Definicija. Kontinuirana slučajna varijabla X ima normalno pravo distribucija(Gaussov zakon )s parametrima a i σ 2 ako je njegova gustoća vjerojatnosti f(x) izgleda kao:
| . | (6.19) |
Krivulja normalne distribucije naziva se normalan ili Gaussova krivulja. Na sl. 6.5 a), b) prikazuje normalnu krivulju s parametrima A I σ 2 i graf funkcije distribucije.
 Obratimo pozornost na činjenicu da je normalna krivulja simetrična u odnosu na ravnu liniju x = A, ima maksimum u točki x = A, jednako , i dvije točke infleksije x = A σ
s ordinatama.
Obratimo pozornost na činjenicu da je normalna krivulja simetrična u odnosu na ravnu liniju x = A, ima maksimum u točki x = A, jednako , i dvije točke infleksije x = A σ
s ordinatama.
Može se primijetiti da su u normalnom zakonskom izrazu gustoće parametri raspodjele označeni slovima A I σ 2, koji smo koristili za označavanje matematičkog očekivanja i disperzije. Ova podudarnost nije slučajna. Razmotrimo teorem koji utvrđuje vjerojatnosno teoretsko značenje parametara normalnog zakona.
Teorema. Matematičko očekivanje slučajne varijable X, distribuirane prema normalnom zakonu, jednako je parametru a te distribucije, tj.
| M(x) = A, | (6.20) |
a njegova disperzija – na parametar σ 2, tj.
| D(x) = σ 2. | (6.21) |
Saznajmo kako će se normalna krivulja promijeniti kada se parametri promijene A I σ .
Ako σ = const, a parametar se mijenja a (A 1 < A 2 < A 3), tj. središte simetrije distribucije, tada će se normalna krivulja pomaknuti duž osi apscise bez promjene oblika (sl. 6.6).

Riža. 6.6

Riža. 6.7
Ako A= const i parametar se mijenja σ , tada se mijenja ordinata maksimuma krivulje f max(a) = . Prilikom povećanja σ ordinata maksimuma se smanjuje, ali budući da površina ispod bilo koje distribucijske krivulje mora ostati jednaka jedinici, krivulja postaje ravnija, rastežući se duž x-osi. Prilikom smanjenja σ Naprotiv, normalna krivulja se proteže prema gore dok se istovremeno sabija sa strane (slika 6.7).
Dakle, parametar a karakterizira položaj i parametar σ – oblik normalne krivulje.
Zakon normalne distribucije slučajne varijable s parametrima a= 0 i σ = 1 se zove standard ili normalizirao, a odgovarajuća normalna krivulja je standard ili normalizirao.
Teškoća izravnog pronalaženja funkcije distribucije slučajne varijable raspodijeljene prema normalnom zakonu je posljedica činjenice da se integral funkcije normalne distribucije ne izražava kroz elementarne funkcije. Međutim, može se izračunati pomoću posebne funkcije koja izražava određeni integral izraza ili. Ova funkcija se zove Laplaceova funkcija, za njega su sastavljene tablice. Postoji mnogo varijanti ove funkcije, na primjer:
![]() ,
, ![]() .
.
Koristit ćemo funkciju
Razmotrimo svojstva slučajne varijable raspodijeljene prema normalnom zakonu.
1. Vjerojatnost da slučajna varijabla X, distribuirana prema normalnom zakonu, padne u interval [α , β ] jednak
Pomoću ove formule izračunavamo vjerojatnosti za različite vrijednosti δ (koristeći tablicu vrijednosti Laplaceove funkcije):
na δ = σ = 2F(1) = 0,6827;
na δ = 2σ = 2F(2) = 0,9545;
na δ = 3σ = 2F(3) = 0,9973.
To dovodi do tzv. pravilo tri sigme»:
Ako slučajna varijabla X ima normalan zakon raspodjele s parametrima a i σ, tada je gotovo sigurno da njezine vrijednosti leže u intervalu(a – 3σ ; a + 3σ ).
Primjer 6.3. Uz pretpostavku da je visina muškaraca određene dobne skupine normalno raspodijeljena slučajna varijabla x s parametrima A= 173 i σ 2 = 36, pronađite:
1. Izraz gustoće vjerojatnosti i funkcije distribucije slučajne varijable x;
2. Udio odijela 4. visine (176 - 183 cm) i udio odijela 3. visine (170 - 176 cm), koji moraju biti uključeni u ukupni obujam proizvodnje za ovu dobnu skupinu;
3. Formulirajte "pravilo tri sigme" za slučajnu varijablu x.
1. Određivanje gustoće vjerojatnosti
![]()
i funkcija distribucije slučajne varijable X
![]() = .
= .
2. Pronalazimo udio odijela visine 4 (176 – 182 cm) kao vjerojatnost
R(176 ≤ x ≤ 182) = ![]() = F(1,5) – F(0,5).
= F(1,5) – F(0,5).
Prema tablici vrijednosti Laplaceove funkcije ( Dodatak 2) pronašli smo:
F(1,5) = 0,4332, F(0,5) = 0,1915.
Napokon dobivamo
R(176 ≤ x ≤ 182) = 0,4332 – 0,1915 = 0,2417.
Na sličan način može se utvrditi i udio odijela 3. visine (170 – 176 cm). No, to je lakše učiniti ako uzmemo u obzir da je taj interval simetričan u odnosu na matematičko očekivanje A= 173, tj. nejednakost 170 ≤ x≤ 176 je ekvivalent nejednakosti │ x– 173│≤ 3. Zatim
R(170 ≤x ≤176) = R(│x– 173│≤ 3) = 2F(3/6) = 2F(0,5) = 2·0,1915 = 0,3830.
3. Formulirajmo "pravilo tri sigme" za slučajnu varijablu X:
Gotovo je sigurno da se visina muškaraca u ovoj dobnoj skupini kreće od A – 3σ = 173 – 3 6 = 155 do A + 3σ = 173 + 3·6 = 191, tj. 155 ≤ x ≤ 191. ◄
7. GRANIČNI TEOREMI TEORIJE VJEROJATNOSTI
Kao što je već spomenuto pri proučavanju slučajnih varijabli, nemoguće je unaprijed predvidjeti koju će vrijednost slučajna varijabla poprimiti kao rezultat jednog testa - to ovisi o mnogim razlozima koji se ne mogu uzeti u obzir.
Međutim, kada se testovi ponavljaju mnogo puta, ponašanje zbroja slučajnih varijabli gotovo gubi svoj slučajni karakter i postaje prirodno. Prisutnost obrazaca povezana je upravo s masovnom prirodom pojava koje u svojoj ukupnosti generiraju slučajnu varijablu koja podliježe dobro definiranom zakonu. Suština stabilnosti masovnih pojava svodi se na sljedeće: specifičnosti svake pojedine slučajne pojave nemaju gotovo nikakvog utjecaja na prosječni rezultat mase takvih pojava; slučajna odstupanja od prosjeka, neizbježna u svakoj pojedinoj pojavi, međusobno se poništavaju, izravnavaju, izravnavaju u masi.
Upravo ta stabilnost prosjeka predstavlja fizički sadržaj "zakona velikih brojeva", shvaćenog u širem smislu riječi: s vrlo velikim brojem slučajnih pojava, njihov rezultat praktički prestaje biti slučajan i može se predvidjeti s visok stupanj sigurnosti.
U užem smislu riječi, "zakon velikih brojeva" u teoriji vjerojatnosti shvaća se kao niz matematičkih teorema, od kojih svaki, za određene uvjete, utvrđuje činjenicu da se prosječne karakteristike velikog broja eksperimenata približavaju određenim određene konstante.
Zakon velikih brojeva igra važnu ulogu u praktičnim primjenama teorije vjerojatnosti. Svojstvo slučajnih varijabli da se pod određenim uvjetima ponašaju praktički kao neslučajne omogućuje pouzdano rukovanje ovim veličinama i predviđanje rezultata masovnih slučajnih pojava s gotovo potpunom sigurnošću.
Mogućnosti takvih predviđanja u području masovnih slučajnih pojava dodatno su proširene prisutnošću druge skupine graničnih teorema, koji se ne tiču graničnih vrijednosti slučajnih varijabli, već ograničavajućih zakona distribucije. Govorimo o skupini teorema poznatih kao "teorem središnje granice". Različiti oblici središnjeg graničnog teorema razlikuju se jedni od drugih u uvjetima za koje se uspostavlja ovo ograničavajuće svojstvo zbroja slučajnih varijabli.
Razni oblici zakona velikih brojeva s raznim oblicima središnjeg graničnog teorema čine skup tzv. granični teoremi teorija vjerojatnosti. Granični teoremi omogućuju ne samo izradu znanstvenih prognoza u području slučajnih pojava, već i procjenu točnosti tih prognoza.
Slučajna varijabla se zove raspodijeljena prema normalnom (Gaussovom) zakonu s parametrima A i () , ako gustoća distribucije vjerojatnosti ima oblik
Normalno raspodijeljena veličina uvijek ima beskonačan broj mogućih vrijednosti, pa ju je zgodno grafički prikazati pomoću grafa gustoće raspodjele. Prema formuli
vjerojatnost da će slučajna varijabla uzeti vrijednost iz nekog intervala jednaka je površini ispod grafa funkcije na tom intervalu (geometrijsko značenje određenog integrala). Funkcija koja se razmatra je nenegativna i kontinuirana. Graf funkcije ima oblik zvona i naziva se Gaussova krivulja ili normalna krivulja.
Slika prikazuje nekoliko krivulja gustoće distribucije slučajne varijable specificirane prema normalnom zakonu.
Sve krivulje imaju jednu maksimalnu točku, a kako se od nje udaljavate udesno i ulijevo, krivulje se smanjuju. Maksimum se postiže na i jednak je .
Krivulje su simetrične oko okomite linije povučene kroz najvišu točku. Površina podgrafa svake krivulje je 1.
Razlika između pojedinih krivulja distribucije je samo u tome što je ukupna površina podgrafa, ista za sve krivulje, različito raspoređena između različitih sekcija. Glavni dio područja podgrafa bilo koje krivulje koncentriran je u neposrednoj blizini najvjerojatnije vrijednosti, a ta je vrijednost različita za sve tri krivulje. Za različite vrijednosti i A dobivaju se različiti normalni zakoni i različiti grafici funkcije distribucije gustoće.
Teorijske studije su pokazale da većina slučajnih varijabli koje se susreću u praksi imaju normalan zakon distribucije. Prema ovom zakonu raspodjeljuju se brzina molekula plina, težina novorođenčadi, veličina odjeće i obuće stanovništva zemlje i mnogi drugi slučajni događaji fizičke i biološke prirode. Taj je obrazac prvi uočio i teorijski potkrijepio A. Moivre.
Za , funkcija se podudara s funkcijom o kojoj je već bilo riječi u Moivre–Laplaceovom teoremu o lokalnoj granici. Gustoća vjerojatnosti normalne distribucije je jednostavna izraženo kroz:
Za takve vrijednosti parametara naziva se normalni zakon glavni .
Funkcija distribucije za normaliziranu gustoću naziva se Laplaceova funkcija i naznačen je Φ(x). Također smo se već susreli s ovom funkcijom.
Laplaceova funkcija ne ovisi o određenim parametrima A i σ. Za Laplaceovu funkciju, koristeći metode približne integracije, sastavljene su tablice vrijednosti na intervalu s različitim stupnjevima točnosti. Očito je Laplaceova funkcija neparna, stoga nema potrebe stavljati njezine vrijednosti u tablicu za negativne .
Za slučajnu varijablu raspodijeljenu prema normalnom zakonu s parametrima A i , matematičko očekivanje i disperzija izračunavaju se pomoću formula: , .Standardno odstupanje je jednako .
Vjerojatnost da normalno raspodijeljena veličina poprimi vrijednost iz intervala jednaka je
gdje je Laplaceova funkcija uvedena u integralnom graničnom teoremu.
Često je u problemima potrebno izračunati vjerojatnost da odstupanje normalno distribuirane slučajne varijable x od svog matematičkog očekivanja u apsolutnoj vrijednosti ne prelazi određenu vrijednost, tj. izračunati vjerojatnost. Primjenom formule (19.2) imamo:
U zaključku donosimo jedan važan korolar iz formule (19.3). Stavimo ovu formulu. Zatim, tj. vjerojatnost da apsolutna vrijednost odstupanja x njegovog matematičkog očekivanja neće prijeći , jednako 99,73%. U praksi se takav događaj može smatrati pouzdanim. Ovo je bit pravila tri sigme.
Pravilo tri sigme. Ako je slučajna varijabla normalno raspodijeljena, tada apsolutna vrijednost njezina odstupanja od matematičkog očekivanja praktički ne prelazi trostruku standardnu devijaciju.
U članku se detaljno prikazuje što je zakon normalne distribucije slučajne varijable i kako ga koristiti pri rješavanju praktičnih problema.
Normalna distribucija u statistici
Povijest prava seže 300 godina unatrag. Prvi pronalazač bio je Abraham de Moivre, koji je do aproksimacije došao još 1733. godine. Mnogo godina kasnije, Carl Friedrich Gauss (1809.) i Pierre-Simon Laplace (1812.) izveli su matematičke funkcije.
Laplace je također otkrio izvanredan obrazac i formulirao središnji granični teorem (CPT), prema kojem zbroj velikog broja malih i neovisnih veličina ima normalnu raspodjelu.
Normalni zakon nije fiksna jednadžba ovisnosti jedne varijable o drugoj. Bilježi se samo priroda ove ovisnosti. Specifični oblik raspodjele zadaje se posebnim parametrima. Na primjer, y = sjekira + b je jednadžba ravne linije. Međutim, gdje točno prolazi i pod kojim kutom određuju parametri A I b. Isto je i s normalnom distribucijom. Jasno je da se radi o funkciji koja opisuje tendenciju visoke koncentracije vrijednosti oko središta, no njezin točan oblik određuju posebni parametri.
Gaussova krivulja normalne distribucije izgleda ovako.
Grafikon normalne distribucije nalikuje zvonu, zbog čega biste mogli vidjeti naziv zvonasta krivulja. Graf ima "grbu" u sredini i oštro smanjenje gustoće na rubovima. Ovo je bit normalne distribucije. Vjerojatnost da će slučajna varijabla biti blizu središta puno je veća nego da će jako odstupiti od središta.

Gornja slika prikazuje dva područja ispod Gaussove krivulje: plavo i zeleno. Razlozi, tj. Intervali su jednaki za obje dionice. Ali visine su primjetno drugačije. Plavo područje udaljenije je od središta i znatno je niže visine od zelenog područja koje se nalazi u samom središtu distribucije. Posljedično se razlikuju i površine, odnosno vjerojatnosti upadanja u zadane intervale.
Formula za normalnu distribuciju (gustoću) je sljedeća.
![]()
Formula se sastoji od dvije matematičke konstante:
π – pi broj 3,142;
e– baza prirodnog logaritma 2,718;
dva promjenjiva parametra koji definiraju oblik određene krivulje:
m– matematičko očekivanje (u različitim izvorima mogu se koristiti i druge oznake, npr. µ ili a);
σ 2– disperzija;
i sama varijabla x, za koji se izračunava gustoća vjerojatnosti.
Specifični oblik normalne distribucije ovisi o 2 parametra: ( m) i ( σ 2). Ukratko naznačeno N(m, σ 2) ili N(m, σ). Parametar m(očekivanje) određuje središte distribucije, koje odgovara maksimalnoj visini grafa. Disperzija σ 2 karakterizira opseg varijacije, odnosno "razmazanost" podataka.
Parametar matematičkog očekivanja pomiče središte distribucije udesno ili ulijevo bez utjecaja na oblik same krivulje gustoće.

Ali disperzija određuje oštrinu krivulje. Kada podaci imaju malu raspršenost, tada je sva njihova masa koncentrirana u središtu. Ako podaci imaju veliku raspršenost, tada su "rasprostranjeni" u širokom rasponu.

Gustoća distribucije nema izravnu praktičnu primjenu. Da biste izračunali vjerojatnosti, morate integrirati funkciju gustoće.
Vjerojatnost da će slučajna varijabla biti manja od određene vrijednosti x, utvrđuje se funkcija normalne distribucije:
Koristeći matematička svojstva bilo koje kontinuirane distribucije, lako je izračunati sve druge vjerojatnosti, budući da
P(a ≤ X< b) = Ф(b) – Ф(a)
Standardna normalna distribucija
Normalna distribucija ovisi o parametrima sredine i varijance, zbog čega su njena svojstva slabo vidljiva. Bilo bi lijepo imati neki standard distribucije koji ne ovisi o mjerilu podataka. I postoji. Nazvana standardna normalna distribucija. Zapravo, radi se o običnoj normalnoj distribuciji, samo s parametrima matematičko očekivanje 0 i varijanca 1, ukratko napisano N(0, 1).
Svaka normalna distribucija može se lako pretvoriti u standardnu distribuciju normalizacijom:
Gdje z– nova varijabla koja se koristi umjesto x;
m- očekivana vrijednost;
σ
- standardna devijacija.
Za uzorke podataka uzimaju se procjene:
Aritmetička sredina i varijanca nove varijable z sada su također 0 odnosno 1. To se lako može provjeriti pomoću elementarnih algebarskih transformacija.
Ime se pojavljuje u literaturi z-rezultat. To je to – normalizirani podaci. Z-rezultat mogu se izravno usporediti s teorijskim vjerojatnostima, jer njegova se ljestvica poklapa sa standardnom.
Pogledajmo sada kako izgleda gustoća standardne normalne distribucije (npr z-rezultati). Podsjećam vas da Gaussova funkcija ima oblik:
![]()
Umjesto toga zamijenimo (x-m)/σ pismo z, a umjesto toga σ – jedan, dobivamo funkcija gustoće standardne normalne distribucije:
![]()
Grafikon gustoće:

Središte je, očekivano, u točki 0. U istoj točki Gaussova funkcija doseže svoj maksimum, što odgovara slučajnoj varijabli koja prihvaća svoju prosječnu vrijednost (tj. x-m=0). Gustoća u ovom trenutku je 0,3989, što se može izračunati čak iu vašoj glavi, jer e 0 =1 i sve što preostaje je izračunati omjer 1 prema korijenu 2 pi.
Dakle, grafikon jasno pokazuje da se vrijednosti koje imaju mala odstupanja od prosjeka pojavljuju češće od ostalih, a one koje su jako udaljene od središta pojavljuju se puno rjeđe. Ljestvica osi x mjeri se standardnim odstupanjima, što vam omogućuje da se riješite mjernih jedinica i dobijete univerzalnu strukturu normalne distribucije. Gaussova krivulja za normalizirane podatke savršeno pokazuje druga svojstva normalne distribucije. Na primjer, da je simetričan u odnosu na ordinatnu os. Većina svih vrijednosti koncentrirana je unutar ±1σ od aritmetičke sredine (za sada procjenjujemo na oko). Većina podataka je unutar ±2σ. Gotovo svi podaci su unutar ±3σ. Posljednje svojstvo nadaleko je poznato kao pravilo tri sigme za normalnu distribuciju.
Standardna funkcija normalne distribucije omogućuje vam izračunavanje vjerojatnosti.
![]()
Jasno je da nitko ne broji ručno. Sve je izračunato i smješteno u posebne tablice, koje se nalaze na kraju svakog udžbenika statistike.
Tablica normalne distribucije
Postoje dvije vrste tablica normalne distribucije:
- stol gustoća;
- stol funkcije(integral gustoće).
Stol gustoća rijetko korišten. Ipak, da vidimo kako to izgleda. Recimo da trebamo dobiti gustoću za z = 1, tj. gustoća vrijednosti odvojena od očekivanja za 1 sigmu. Ispod je dio tablice.

Ovisno o organizaciji podataka, traženu vrijednost tražimo po nazivu stupca i retka. U našem primjeru uzimamo liniju 1,0 i stupac 0 , jer nema stotinki. Vrijednost koju tražite je 0,2420 (0 prije 2420 je izostavljena).
Gaussova funkcija je simetrična u odnosu na ordinatu. Zato φ(z)= φ(-z), tj. gustoća za 1 identičan je gustoći za -1 , što je jasno vidljivo na slici.

Kako bi se izbjeglo rasipanje papira, tablice se ispisuju samo za pozitivne vrijednosti.
U praksi se češće koriste vrijednosti funkcije standardna normalna distribucija, odnosno vjerojatnost za različite z.
Takve tablice također sadrže samo pozitivne vrijednosti. Stoga, razumjeti i pronaći bilo koji trebali biste znati potrebne vjerojatnosti svojstva standardne normalne distribucije.
Funkcija F(z) simetričan oko svoje vrijednosti 0,5 (a ne ordinatne osi, kao gustoća). Dakle, jednakost je istinita:
Ova činjenica je prikazana na slici:

Vrijednosti funkcije F(-z) I F(z) podijeliti graf na 3 dijela. Štoviše, gornji i donji dio su jednaki (označeno kvačicama). Da dopuni vjerojatnost F(z) na 1, samo dodajte vrijednost koja nedostaje F(-z). Dobivate gore naznačenu jednakost.
Ako trebate pronaći vjerojatnost pada u interval (0; z), odnosno vjerojatnosti odstupanja od nule u pozitivnom smjeru do određenog broja standardnih odstupanja, dovoljno je od vrijednosti funkcije standardne normalne distribucije oduzeti 0,5:

Radi jasnoće, možete pogledati crtež.

Na Gaussovoj krivulji, ova ista situacija izgleda kao područje od središta desno do z.

Vrlo često analitičara zanima vjerojatnost odstupanja u oba smjera od nule. A budući da je funkcija simetrična oko središta, prethodna formula se mora pomnožiti s 2:

Slika ispod.

Ispod Gaussove krivulje ovo je središnji dio ograničen odabranom vrijednošću –z lijevo i z desno.

Ova svojstva treba uzeti u obzir, jer tablične vrijednosti rijetko odgovaraju intervalu od interesa.
Da bi se zadatak olakšao, udžbenici obično objavljuju tablice za funkcije oblika:

Ako vam je potrebna vjerojatnost odstupanja u oba smjera od nule, tada se, kao što smo upravo vidjeli, tablična vrijednost za ovu funkciju jednostavno pomnoži s 2.
Sada pogledajmo konkretne primjere. Ispod je tablica standardne normalne distribucije. Pronađimo tablične vrijednosti za tri z: 1.64, 1.96 i 3.

Kako razumjeti značenje ovih brojeva? Počnimo s z=1,64, za koju je tablična vrijednost 0,4495 . Značenje je najlakše objasniti na slici.

To jest, vjerojatnost da standardizirana normalno distribuirana slučajna varijabla padne unutar intervala od 0 prije 1,64 , je jednako 0,4495 . Kada rješavate probleme, obično morate izračunati vjerojatnost odstupanja u oba smjera, pa pomnožimo vrijednost 0,4495 za 2 i dobijemo približno 0,9. Zauzeto područje ispod Gaussove krivulje prikazano je u nastavku.

Dakle, 90% svih normalno raspodijeljenih vrijednosti spada u interval ±1,64σ od aritmetičke sredine. Nisam slučajno odabrao značenje z=1,64, jer susjedstvo oko aritmetičke sredine, koje zauzima 90% cjelokupnog područja, ponekad se koristi za izračunavanje intervala pouzdanosti. Ako vrijednost koja se testira ne spada unutar označenog područja, tada je njezino pojavljivanje malo vjerojatno (samo 10%).
Za testiranje hipoteza, međutim, češće se koristi interval koji pokriva 95% svih vrijednosti. Pola šanse 0,95 - Ovo 0,4750 (pogledajte drugu istaknutu vrijednost u tablici).

Za ovu vjerojatnost z=1,96. Oni. unutar gotovo ±2σ 95% vrijednosti je iz prosjeka. Samo 5% je izvan ovih granica.

Još jedna zanimljiva i često korištena tablična vrijednost odgovara z=3, jednako je prema našoj tablici 0,4986 . Pomnožimo s 2 i dobijemo 0,997 . Dakle, unutar ±3σ Gotovo sve vrijednosti izvedene su iz aritmetičke sredine.

Ovako izgleda pravilo 3 sigme za normalnu distribuciju u dijagramu.
Pomoću statističkih tablica možete dobiti bilo koju vjerojatnost. Međutim, ova metoda je vrlo spora, nezgodna i vrlo zastarjela. Danas se sve radi na računalu. Zatim prelazimo na praksu izračuna u Excelu.
Normalna distribucija u Excelu
Excel ima nekoliko funkcija za izračunavanje vjerojatnosti ili inverza normalne distribucije.

Funkcija NORMAL DIST
Funkcija NORM.ST.DIST. dizajniran za izračunavanje gustoće ϕ(z) ili vjerojatnosti Φ(z) prema normaliziranim podacima ( z).
=NORM.ST.DIST(z;integral)
z– vrijednost standardizirane varijable
sastavni– ako je 0, izračunava se gustoćaϕ(z) , ako je 1 vrijednost funkcije F(z), tj. vjerojatnost P(Z
Izračunajmo gustoću i vrijednost funkcije za razne z: -3, -2, -1, 0, 1, 2, 3(naznačit ćemo ih u ćeliji A2).
Za izračun gustoće trebat će vam formula =NORM.ST.DIST(A2;0). Na donjem dijagramu ovo je crvena točka.
Za izračun vrijednosti funkcije =NORM.ST.DIST(A2;1). Dijagram prikazuje osjenčano područje ispod normalne krivulje.

U stvarnosti je češće potrebno izračunati vjerojatnost da slučajna varijabla neće prijeći određene granice prosjeka (u standardnim odstupanjima koja odgovaraju varijabli z), tj. P(|Z|

Odredimo vjerojatnost da slučajna varijabla padne unutar granica ±1z, ±2z i ±3z od nule. Treba formula 2F(z)-1, u Excelu =2*NORM.ST.DIST(A2;1)-1.

Dijagram jasno prikazuje glavna osnovna svojstva normalne distribucije, uključujući pravilo tri sigme. Funkcija NORM.ST.DIST. je automatska tablica normalnih vrijednosti funkcije distribucije u Excelu.
Može postojati i obrnuti problem: prema raspoloživoj vjerojatnosti P(Z
funkcija NORM.ST.REV
NORM.ST.REV izračunava inverznu funkciju standardne normalne distribucije. Sintaksa se sastoji od jednog parametra:
=NORM.ST.REV(vjerojatnost)
vjerojatnost je vjerojatnost.
Ova se formula koristi jednako često kao i prethodna, jer upotrebom istih tablica morate tražiti ne samo vjerojatnosti, već i kvantile.

Na primjer, prilikom izračunavanja intervala pouzdanosti navedena je vjerojatnost pouzdanosti prema kojoj je potrebno izračunati vrijednost z.

S obzirom da se interval pouzdanosti sastoji od gornje i donje granice te da je normalna distribucija simetrična oko nule, dovoljno je dobiti gornju granicu (pozitivno odstupanje). Donja granica uzima se s negativnim predznakom. Označimo vjerojatnost povjerenja kao γ (gama), tada se gornja granica intervala pouzdanosti izračunava pomoću sljedeće formule.
![]()
Izračunajmo vrijednosti u Excelu z(što odgovara odstupanju od prosjeka u sigmi) za nekoliko vjerojatnosti, uključujući i one koje svaki statističar zna napamet: 90%, 95% i 99%. U ćeliji B2 označavamo formulu: =NORM.ST.REV((1+A2)/2). Promjenom vrijednosti varijable (vjerojatnost u ćeliji A2) dobivamo različite granice intervala.

Interval pouzdanosti od 95% je 1,96, odnosno gotovo 2 standardne devijacije. Odavde je lako, čak i mentalno, procijeniti moguće širenje normalne slučajne varijable. Općenito, intervali pouzdanosti od 90%, 95% i 99% odgovaraju intervalima pouzdanosti od ±1,64, ±1,96 i ±2,58σ.
Općenito, funkcije NORM.ST.DIST i NORM.ST.REV omogućuju izvođenje bilo kojeg izračuna koji se odnosi na normalnu distribuciju. Ali kako bi stvari bile lakše i manje komplicirane, Excel ima nekoliko drugih značajki. Na primjer, možete koristiti NORMU POVJERANJA za izračun intervala pouzdanosti za srednju vrijednost. Za provjeru aritmetičke sredine postoji formula Z.TEST.
Pogledajmo još nekoliko korisnih formula s primjerima.
Funkcija NORMAL DIST
Funkcija NORMALNA DIST. razlikuje se od NORM.ST.DIST. samo zato što se koristi za obradu podataka bilo koje razine, a ne samo normaliziranih. Parametri normalne distribucije navedeni su u sintaksi.
=NORM.DIST(x,prosjek,standardna_devijacija,integral)
prosjek– matematičko očekivanje koje se koristi kao prvi parametar modela normalne distribucije
standard_off– standardna devijacija – drugi parametar modela
sastavni– ako je 0, računa se gustoća, ako je 1 – vrijednost funkcije, tj. P(X
Na primjer, gustoća za vrijednost 15, koja je izdvojena iz normalnog uzorka s očekivanim 10, standardnom devijacijom 3, izračunava se na sljedeći način:

Ako je zadnji parametar postavljen na 1, tada dobivamo vjerojatnost da će normalna slučajna varijabla biti manja od 15 za dane parametre distribucije. Stoga se vjerojatnosti mogu izračunati izravno iz izvornih podataka.
funkcija NORM.REV
Ovo je kvantil normalne distribucije, tj. vrijednost inverzne funkcije. Sintaksa je sljedeća.
=NORM.REV(vjerojatnost,prosjek,standardna_devijacija)
vjerojatnost- vjerojatnost
prosjek– matematičko očekivanje
standard_off– standardna devijacija
Svrha je ista kao NORM.ST.REV, samo funkcija radi s podacima bilo koje razine.
Primjer je prikazan u videu na kraju članka.
Modeliranje normalne distribucije
Neki problemi zahtijevaju generiranje normalnih nasumičnih brojeva. Ne postoji gotova funkcija za to. Međutim, Excel ima dvije funkcije koje vraćaju nasumične brojeve: SLUČAJ IZMEĐU I RAND. Prvi proizvodi nasumične, ravnomjerno raspoređene cijele brojeve unutar određenih granica. Druga funkcija generira ravnomjerno distribuirane slučajne brojeve između 0 i 1. Da biste napravili umjetni uzorak s bilo kojom danom distribucijom, potrebna vam je funkcija RAND.
Recimo da je za provođenje eksperimenta potrebno dobiti uzorak iz normalno raspoređene populacije s očekivanjem od 10 i standardnom devijacijom od 3. Za jednu slučajnu vrijednost napisat ćemo formulu u Excelu.
NORM.INV(RAND();10;3)
Proširimo ga na potreban broj stanica i normalni uzorak je spreman.
Za modeliranje standardiziranih podataka trebali biste koristiti NORM.ST.REV.
Proces pretvaranja uniformnih brojeva u normalne brojeve može se prikazati na sljedećem dijagramu. Iz uniformnih vjerojatnosti koje generira RAND formula, vodoravne linije se povlače na grafikon funkcije normalne distribucije. Zatim se iz točaka sjecišta vjerojatnosti s grafom projekcije spuštaju na vodoravnu os.