Probabilitas variabel acak terdistribusi normal. Hukum normal distribusi probabilitas variabel acak kontinu. Hubungan dengan distribusi lain
Mengganti (x)=π /4 ,f(x)=1/(b-a)
D[π /4]=( /720) ).
№319 tepi kubus x diukur kira-kira sebuah . Mengingat rusuk kubus sebagai variabel acak X yang terdistribusi secara seragam dalam interval (a,b), tentukan ekspektasi matematis dan varians volume kubus.
1. Mari kita cari ekspektasi matematis dari luas lingkaran - variabel acak Y=φ(K)= - sesuai rumus
M[φ(X)]= ![]()
Menempatkan (x)= ,f(x)=1/(b-a) dan setelah diintegralkan diperoleh
M( )=
 .
.
2. Cari dispersi luas lingkaran menggunakan rumus
D[φ(X)]= ![]() -
-
![]() .
.
Mengganti (x)= ,f(x)=1/(b-a) dan setelah diintegralkan diperoleh
D =
 .
.
№320 Variabel acak X dan Y adalah bebas dan terdistribusi seragam: X-dalam interval (a,b), Y-dalam interval (c,d) Temukan ekspektasi matematis dari produk XY.
Ekspektasi matematis dari produk variabel acak independen sama dengan produk ekspektasi matematisnya, yaitu.
M(XY)= 
№321 Variabel acak X dan Y adalah independen dan terdistribusi seragam: X - dalam interval (a,b), Y - dalam interval (c,d). Temukan varians dari produk XY.
Mari kita gunakan rumus
D(XY)=M[
Ekspektasi matematis dari produk variabel acak independen sama dengan produk ekspektasi matematisnya, oleh karena itu
Mari kita cari M dengan rumus
M[φ(X)]= ![]()
Mengganti (x)= ,f(x)=1/(b-a) dan mengintegrasikan, kita dapatkan
M (**)
Demikian pula, kami menemukan
M (***)
Mengganti M(X)=(a+b)/2, M(Y)=(c+d)/2, serta (***) dan (**) di (*), kami akhirnya mendapatkan
D(XY)= -[
![]() .
.
№322 Ekspektasi matematis dari variabel acak X yang terdistribusi normal adalah a=3 dan simpangan baku =2. Tulis kerapatan peluang dari X.
Mari kita gunakan rumus:
f(x)=  .
.
Mengganti nilai yang tersedia, kami mendapatkan:
f(x)=  = f(x)=
= f(x)=  .
.
№323 Tulis kerapatan peluang dari variabel acak X yang terdistribusi normal, dengan mengetahui bahwa M(X)=3, D(X)=16.
Mari kita gunakan rumus:
f(x)= .
Untuk mencari nilai , kita menggunakan sifat bahwa simpangan baku suatu peubah acak X sama dengan akar kuadrat variansnya. Jadi =4, M(X)=a=3. Substitusikan ke dalam rumus yang kita peroleh
f(x)=  =
=
 .
.
№324 Variabel acak terdistribusi normal X diberikan oleh kerapatan
f(x)= ![]() .
Tentukan ekspektasi matematis dan varians dari X.
.
Tentukan ekspektasi matematis dan varians dari X.
Mari kita gunakan rumus
f(x)= ,
di mana sebuah-nilai yang diharapkan, σ -standar deviasi X. Dari rumus ini didapat bahwa a=M(X)=1. Untuk menemukan varians, kami menggunakan properti bahwa standar deviasi dari variabel acak X sama dengan akar kuadrat variansnya. Akibatnya D(X)= =
Jawaban: ekspektasi matematisnya adalah 1; variannya adalah 25.
Bondarchuk Rodion
Mengingat fungsi distribusi dari hukum normal yang dinormalisasi ![]() . Cari densitas distribusi f(x).
. Cari densitas distribusi f(x).
Mengetahui bahwa ![]() , kita temukan f(x).
, kita temukan f(x).

Menjawab: ![]()
Buktikan bahwa fungsi Laplace ![]() . aneh:
. aneh: ![]() .
.

Kami akan membuat penggantinya


Kami membuat substitusi terbalik dan mendapatkan:
![]() =
= ![]() =
=


Juga akan ada tugas untuk solusi independen, di mana Anda dapat melihat jawabannya.
Distribusi normal: landasan teori
Contoh variabel acak yang didistribusikan menurut hukum normal adalah tinggi badan seseorang, massa ikan yang ditangkap dari spesies yang sama. Distribusi normal berarti sebagai berikut: : ada nilai tinggi manusia, massa ikan dari spesies yang sama, yang secara intuitif dianggap "normal" (dan sebenarnya - rata-rata), dan mereka jauh lebih umum dalam sampel yang cukup besar daripada yang yang berbeda naik atau turun.
Distribusi probabilitas normal dari variabel acak kontinu (kadang-kadang distribusi Gaussian) dapat disebut berbentuk lonceng karena fakta bahwa fungsi kerapatan dari distribusi ini, yang simetris terhadap rata-rata, sangat mirip dengan potongan lonceng ( kurva merah pada gambar di atas).
Probabilitas memenuhi nilai-nilai tertentu dalam sampel sama dengan luas gambar di bawah kurva, dan dalam kasus distribusi normal, kita melihat bahwa di bawah bagian atas "lonceng" , yang sesuai dengan nilai yang cenderung ke rata-rata, area, dan oleh karena itu probabilitasnya, lebih besar daripada di bawah tepi. Dengan demikian, kita mendapatkan hal yang sama yang telah dikatakan: kemungkinan bertemu seseorang dengan tinggi "normal", menangkap ikan dengan berat "normal" lebih tinggi daripada nilai yang berbeda naik atau turun. Dalam banyak kasus praktik, kesalahan pengukuran didistribusikan menurut hukum yang mendekati normal.
Mari kita berhenti lagi pada gambar di awal pelajaran, yang menunjukkan fungsi kerapatan dari distribusi normal. Grafik fungsi ini diperoleh dengan menghitung beberapa sampel data dalam paket perangkat lunak STATISTIK. Di atasnya, kolom histogram mewakili interval nilai sampel yang distribusinya dekat (atau, seperti yang mereka katakan dalam statistik, tidak berbeda secara signifikan dari) dengan grafik fungsi kerapatan distribusi normal itu sendiri, yang merupakan kurva merah. Grafik menunjukkan bahwa kurva ini memang berbentuk lonceng.
Distribusi normal berharga dalam banyak hal karena hanya mengetahui rata-rata variabel acak kontinu dan simpangan baku, Anda dapat menghitung probabilitas apa pun yang terkait dengan variabel tersebut.
Distribusi normal memiliki manfaat tambahan sebagai salah satu yang paling mudah digunakan kriteria statistik yang digunakan untuk menguji hipotesis statistik - Uji-t Student- hanya dapat digunakan jika data sampel mematuhi hukum distribusi normal.
Fungsi kepadatan dari distribusi normal dari variabel acak kontinu dapat dicari dengan menggunakan rumus :
 ,
,
di mana x- nilai variabel, - nilai rata-rata, - simpangan baku, e\u003d 2.71828 ... - basis logaritma natural, \u003d 3.1416 ...
Sifat-sifat fungsi densitas distribusi normal
Perubahan rata-rata menggerakkan kurva fungsi densitas distribusi normal ke arah sumbu Sapi. Jika meningkat, kurva bergerak ke kanan, jika menurun, maka ke kiri.
Jika standar deviasi berubah, maka ketinggian titik kurva berubah. Ketika standar deviasi meningkat, bagian atas kurva lebih tinggi, ketika menurun, itu lebih rendah.
Probabilitas bahwa nilai variabel acak terdistribusi normal akan jatuh dalam interval tertentu
Sudah di paragraf ini, kita akan mulai memecahkan masalah praktis, yang artinya ditunjukkan dalam judul. Mari kita menganalisis kemungkinan apa yang disediakan teori untuk memecahkan masalah. Konsep awal untuk menghitung peluang suatu variabel acak terdistribusi normal yang jatuh ke dalam interval tertentu adalah fungsi integral dari distribusi normal.
Fungsi distribusi normal integral:
 .
.
Namun, sulit untuk mendapatkan tabel untuk setiap kemungkinan kombinasi mean dan standar deviasi. Oleh karena itu, salah satu cara sederhana untuk menghitung probabilitas variabel acak terdistribusi normal yang jatuh ke dalam interval tertentu adalah dengan menggunakan tabel probabilitas untuk distribusi normal standar.
Distribusi normal disebut distribusi terstandardisasi atau ternormalisasi., yang nilai rata-ratanya adalah , dan simpangan bakunya adalah .
Fungsi densitas dari distribusi normal standar:
![]() .
.
Fungsi kumulatif dari distribusi normal standar:
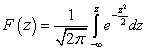 .
.
Gambar di bawah menunjukkan fungsi integral dari distribusi normal standar, grafik yang diperoleh dengan menghitung beberapa sampel data dalam paket perangkat lunak STATISTIK. Grafik itu sendiri adalah kurva merah, dan nilai sampel mendekatinya.

Untuk memperbesar gambar, Anda dapat mengkliknya dengan tombol kiri mouse.
Standarisasi variabel acak berarti berpindah dari unit asli yang digunakan dalam tugas ke unit standar. Standardisasi dilakukan sesuai dengan rumus
Dalam prakteknya, semua nilai yang mungkin dari variabel acak seringkali tidak diketahui, sehingga nilai mean dan standar deviasi tidak dapat ditentukan secara akurat. Mereka digantikan oleh rata-rata aritmatika dari pengamatan dan standar deviasi s. Nilai z menyatakan penyimpangan nilai variabel acak dari rata-rata aritmatika saat mengukur simpangan baku.
Interval terbuka
Tabel probabilitas untuk distribusi normal standar, yang tersedia di hampir semua buku statistik, berisi probabilitas bahwa variabel acak memiliki distribusi normal standar. Z mengambil nilai kurang dari angka tertentu z. Artinya, itu akan jatuh ke dalam interval terbuka dari minus tak terhingga ke z. Misalnya, probabilitas bahwa nilai Z kurang dari 1,5 sama dengan 0,93319.
Contoh 1 Perusahaan memproduksi suku cadang yang memiliki masa pakai terdistribusi normal dengan rata-rata 1000 dan standar deviasi 200 jam.
Untuk bagian yang dipilih secara acak, hitung probabilitas bahwa masa pakainya setidaknya 900 jam.
Larutan. Mari kita perkenalkan notasi pertama:
Probabilitas yang diinginkan.
Nilai variabel acak berada dalam interval terbuka. Tetapi kita dapat menghitung probabilitas bahwa variabel acak akan mengambil nilai yang lebih kecil dari yang diberikan, dan sesuai dengan kondisi masalah, diperlukan untuk menemukan yang sama dengan atau lebih besar dari yang diberikan. Ini adalah bagian lain dari ruang di bawah kurva lonceng. Oleh karena itu, untuk menemukan probabilitas yang diinginkan, perlu untuk mengurangi dari satu probabilitas yang disebutkan bahwa variabel acak akan mengambil nilai kurang dari 900 yang ditentukan:
Sekarang variabel acak perlu distandarisasi.
Kami terus memperkenalkan notasi:
z = (X ≤ 900) ;
x= 900 - nilai yang diberikan dari variabel acak;
μ = 1000 - nilai rata-rata;
σ = 200 - simpangan baku.
Berdasarkan data ini, kami memperoleh kondisi masalah:
![]() .
.
Menurut tabel variabel acak standar (batas interval) z= 0,5 sesuai dengan probabilitas 0,30854. Kurangi dari kesatuan dan dapatkan apa yang diperlukan dalam kondisi masalah:
Jadi, probabilitas bahwa umur suku cadang akan menjadi setidaknya 900 jam adalah 69%.
Probabilitas ini dapat diperoleh dengan menggunakan fungsi MS Excel NORM.DIST (nilai dari nilai integral adalah 1):
P(X≥900) = 1 - P(X 900) = 1 - NORM.DIST(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
Tentang perhitungan di MS Excel - di salah satu paragraf berikutnya dari pelajaran ini.
Contoh 2 Di suatu kota, rata-rata pendapatan tahunan keluarga merupakan variabel acak berdistribusi normal dengan nilai rata-rata 300.000 dan simpangan baku 50.000. Diketahui pendapatan 40% keluarga lebih kecil dari nilai SEBUAH. Temukan nilai SEBUAH.
Larutan. Dalam masalah ini, 40% tidak lebih dari probabilitas bahwa variabel acak akan mengambil nilai dari interval terbuka yang kurang dari nilai tertentu, ditunjukkan dengan huruf SEBUAH.
Untuk mencari nilai SEBUAH, pertama-tama kita buat fungsi integralnya:
![]()
Sesuai tugas
μ = 300000 - nilai rata-rata;
σ = 50000 - simpangan baku;
x = SEBUAH adalah nilai yang akan ditemukan.
Membuat kesetaraan
![]() .
.
Menurut tabel statistik, kami menemukan bahwa probabilitas 0,40 sesuai dengan nilai batas interval z = −0,25 .
Oleh karena itu, kami membuat persamaan
![]()
dan temukan solusinya:
SEBUAH = 287300 .
Jawaban: pendapatan 40% keluarga kurang dari 287300.
Interval tertutup
Dalam banyak masalah, diperlukan untuk menemukan probabilitas bahwa variabel acak terdistribusi normal mengambil nilai dalam interval dari z 1 sampai z 2. Artinya, itu akan jatuh ke dalam interval tertutup. Untuk memecahkan masalah seperti itu, perlu untuk menemukan dalam tabel probabilitas yang sesuai dengan batas-batas interval, dan kemudian menemukan perbedaan antara probabilitas ini. Ini membutuhkan pengurangan nilai yang lebih kecil dari yang lebih besar. Contoh untuk memecahkan masalah umum ini adalah sebagai berikut, dan diusulkan untuk menyelesaikannya sendiri, dan kemudian Anda dapat melihat solusi dan jawaban yang benar.
Contoh 3 Laba suatu perusahaan untuk periode tertentu adalah variabel acak yang tunduk pada hukum distribusi normal dengan nilai rata-rata 0,5 juta c.u. dan standar deviasi 0,354. Tentukan, dengan akurasi dua tempat desimal, probabilitas bahwa laba perusahaan akan dari 0,4 hingga 0,6 c.u.
Contoh 4 Panjang bagian yang diproduksi adalah variabel acak yang didistribusikan menurut hukum normal dengan parameter μ = 10 dan σ = 0,071 . Temukan, dengan akurasi dua tempat desimal, probabilitas pernikahan jika dimensi bagian yang diizinkan harus 10 ± 0,05.
Petunjuk: dalam soal ini, selain mencari peluang peubah acak jatuh ke dalam interval tertutup (probabilitas memperoleh bagian yang tidak cacat), diperlukan satu tindakan lagi.

memungkinkan Anda untuk menentukan probabilitas bahwa nilai standar Z tidak kurang -z Dan tidak lagi +z, di mana z- nilai yang dipilih secara sewenang-wenang dari variabel acak standar.
Metode Perkiraan untuk Memeriksa Normalitas Distribusi
Metode perkiraan untuk memeriksa normalitas distribusi nilai sampel didasarkan pada yang berikut: properti dari distribusi normal: skewness β 1 dan koefisien kurtosis β 2 nol.
Koefisien asimetri β 1 numerik mencirikan simetri distribusi empiris sehubungan dengan mean. Jika kemiringannya nol, maka rata-rata aritmetrik, median, dan modus adalah sama: dan kurva densitas distribusi simetris terhadap rata-rata. Jika koefisien asimetri kurang dari nol (β 1 < 0 ), maka rata-rata aritmatika lebih kecil dari median, dan median, pada gilirannya, lebih kecil dari modus () dan kurva digeser ke kanan (dibandingkan dengan distribusi normal). Jika koefisien asimetri lebih besar dari nol (β 1 > 0 ), maka rata-rata aritmatika lebih besar dari median, dan median, pada gilirannya, lebih besar dari modus () dan kurva bergeser ke kiri (dibandingkan dengan distribusi normal).
Koefisien Kurtosis β 2 mencirikan konsentrasi distribusi empiris di sekitar rata-rata aritmatika dalam arah sumbu Oy dan derajat puncak kurva densitas distribusi. Jika koefisien kurtosis lebih besar dari nol, maka kurva lebih memanjang (dibandingkan dengan distribusi normal) sepanjang sumbu Oy(grafiknya lebih runcing). Jika koefisien kurtosis kurang dari nol, maka kurva lebih rata (dibandingkan dengan distribusi normal) sepanjang sumbu Oy(grafiknya lebih tumpul).
Koefisien skewness dapat dihitung dengan menggunakan fungsi MS Excel SKRS. Jika Anda memeriksa satu larik data, maka Anda harus memasukkan rentang data dalam satu kotak "Nomor".

Koefisien kurtosis dapat dihitung menggunakan fungsi kurtosis MS Excel. Saat memeriksa satu larik data, itu juga cukup untuk memasukkan rentang data dalam satu kotak "Nomor".

Jadi, seperti yang sudah kita ketahui, dengan distribusi normal, koefisien skewness dan kurtosis sama dengan nol. Tetapi bagaimana jika kita mendapatkan koefisien skewness sebesar -0,14, 0,22, 0,43, dan koefisien kurtosis sebesar 0,17, -0,31, 0,55? Pertanyaannya cukup adil, karena dalam praktiknya kita hanya berurusan dengan perkiraan, nilai selektif asimetri dan kurtosis, yang tunduk pada beberapa pencar yang tak terhindarkan dan tak terkendali. Oleh karena itu, tidak mungkin untuk meminta kesetaraan yang ketat dari koefisien-koefisien ini menjadi nol, mereka hanya boleh cukup dekat dengan nol. Tapi apa artinya cukup?
Diperlukan untuk membandingkan nilai empiris yang diterima dengan nilai yang dapat diterima. Untuk melakukan ini, Anda perlu memeriksa ketidaksetaraan berikut (bandingkan nilai modulo koefisien dengan nilai kritis - batas area pengujian hipotesis).
Untuk koefisien asimetri β 1 .
Hukum distribusi normal adalah yang paling umum dalam praktek. Ciri utama yang membedakannya dari undang-undang lain adalah bahwa itu adalah undang-undang yang membatasi, di mana undang-undang distribusi lainnya mendekati dalam kondisi yang sangat umum.
Definisi. Sebuah variabel acak kontinu X memiliki hukum biasa distribusi(hukum Gauss )dengan parameter a dan 2 jika kerapatan probabilitasnya f(x) memiliki bentuk:
| . | (6.19) |
Kurva distribusi normal disebut normal atau kurva gaussian. pada gambar. 6.5 a), b) menunjukkan kurva normal dengan parameter sebuah dan 2 dan grafik fungsi distribusi.
 Perhatikan bahwa kurva normal adalah simetris terhadap garis lurus. X = sebuah, memiliki maksimum pada titik X = sebuah, sama dengan , dan dua titik belok X = sebuah σ
dengan ordinat.
Perhatikan bahwa kurva normal adalah simetris terhadap garis lurus. X = sebuah, memiliki maksimum pada titik X = sebuah, sama dengan , dan dua titik belok X = sebuah σ
dengan ordinat.
Dapat dilihat bahwa dalam ekspresi kerapatan hukum normal, parameter distribusi dilambangkan dengan huruf sebuah dan 2, yang kami tunjukkan harapan dan varians matematis. Kebetulan seperti itu bukan kebetulan. Mari kita pertimbangkan teorema yang menetapkan makna probabilistik dari parameter hukum normal.
Dalil. Ekspektasi matematis dari variabel acak X yang didistribusikan menurut hukum normal sama dengan parameter a dari distribusi ini, yaitu
| M(X) = sebuah, | (6.20) |
dan variansnya ke parameter 2, yaitu
| D(X) = 2. | (6.21) |
Cari tahu bagaimana kurva normal akan berubah saat mengubah parameter sebuah dan σ .
Jika sebuah σ = const, dan parameternya berubah sebuah (sebuah 1 < sebuah 2 < sebuah 3), yaitu pusat simetri distribusi, maka kurva normal akan bergeser sepanjang sumbu x tanpa mengubah bentuknya (Gbr. 6.6).

Beras. 6.6

Beras. 6.7
Jika sebuah sebuah= const dan parameter berubah σ , maka ordinat maksimum kurva berubah fmax(sebuah) = . Dengan peningkatan σ ordinat penurunan maksimum, tetapi karena area di bawah kurva distribusi harus tetap sama dengan satu, kurva menjadi lebih datar, membentang sepanjang sumbu x. Saat menurun σ , sebaliknya, kurva normal membentang ke atas, secara bersamaan menyusut dari samping (Gbr. 6.7).
Jadi, parameter sebuah mencirikan posisi, dan parameter σ adalah bentuk kurva normal.
Distribusi normal dari variabel acak dengan parameter sebuah= 0 dan σ = 1 disebut standar atau dinormalisasi, dan kurva normal yang sesuai adalah standar atau dinormalisasi.
Sulitnya menemukan secara langsung fungsi distribusi dari variabel acak yang terdistribusi menurut hukum normal disebabkan oleh fakta bahwa integral dari fungsi distribusi normal tidak dapat dinyatakan dalam bentuk fungsi elementer. Namun, dapat dihitung melalui fungsi khusus yang menyatakan integral tertentu dari ekspresi atau . Fungsi seperti ini disebut Fungsi Laplace, tabel telah dikompilasi untuk itu. Ada banyak variasi fungsi ini, misalnya:
![]() ,
, ![]() .
.
Kami akan menggunakan fungsi
Pertimbangkan sifat-sifat variabel acak yang didistribusikan menurut hukum normal.
1. Probabilitas bahwa variabel acak X, didistribusikan menurut hukum normal, jatuh ke dalam interval [α , β ] adalah sama dengan
Dengan menggunakan rumus ini, kami menghitung probabilitas untuk berbagai nilai δ (menggunakan tabel nilai fungsi Laplace):
pada δ = σ = 2Ф(1) = 0,6827;
pada δ = 2σ = 2Ф(2) = 0,9545;
pada δ = 3σ = 2Ф(3) = 0,9973.
Di sinilah yang disebut " aturan tiga sigma»:
Jika suatu peubah acak X mempunyai hukum distribusi normal dengan parameter a dan , maka praktis dapat dipastikan bahwa nilainya berada dalam selang(sebuah – 3σ ; sebuah + 3σ ).
Contoh 6.3. Dengan asumsi bahwa tinggi badan laki-laki dari kelompok umur tertentu adalah variabel acak terdistribusi normal X dengan parameter sebuah= 173 dan σ 2 = 36, carilah:
1. Ekspresi kepadatan probabilitas dan fungsi distribusi dari variabel acak X;
2. Bagian jas dengan tinggi ke-4 (176 - 183 cm) dan bagian jas dengan tinggi ke-3 (170 - 176 cm), yang harus disediakan dalam total volume produksi untuk kelompok usia ini;
3. Rumuskan "aturan tiga sigma" untuk variabel acak X.
1. Menemukan kerapatan probabilitas
![]()
dan fungsi distribusi variabel acak X
![]() = .
= .
2. Proporsi pakaian dengan tinggi ke-4 (176 - 182 cm) ditemukan sebagai probabilitas
R(176 ≤ X ≤ 182) = ![]() = F(1.5) – F(0.5).
= F(1.5) – F(0.5).
Menurut tabel nilai fungsi Laplace ( Lampiran 2) kita menemukan:
(1,5) = 0,4332, (0,5) = 0,1915.
Akhirnya kita mendapatkan
R(176 ≤ X ≤ 182) = 0,4332 – 0,1915 = 0,2417.
Bagian jas dengan tinggi ke-3 (170 - 176 cm) dapat ditemukan dengan cara yang sama. Namun, lebih mudah untuk melakukan ini jika kita memperhitungkan bahwa interval ini simetris terhadap ekspektasi matematis sebuah= 173, yaitu ketimpangan 170 X 176 setara dengan pertidaksamaan X– 173│≤ 3. Kemudian
R(170 ≤X ≤176) = R(│X– 173│≤ 3) = 2Ф(3/6) = 2Ф(0,5) = 2 0,1915 = 0,3830.
3. Mari kita merumuskan "aturan tiga sigma" untuk variabel acak X:
Hampir dapat dipastikan bahwa pertumbuhan laki-laki dalam kelompok usia ini berada dalam batas-batas sebuah – 3σ = 173 - 3 6 = 155 ke sebuah + 3σ = 173 + 3 6 = 191, mis. 155 X ≤ 191. ◄
7. TEOREMA BATAS TEORI PROBABILITAS
Seperti yang telah disebutkan dalam studi variabel acak, tidak mungkin untuk memprediksi terlebih dahulu nilai apa yang akan diambil oleh variabel acak sebagai hasil dari satu pengujian - ini tergantung pada banyak alasan yang tidak dapat diperhitungkan.
Namun, dengan pengulangan pengujian yang berulang, perilaku jumlah variabel acak hampir kehilangan karakter acaknya dan menjadi teratur. Kehadiran pola-pola terkait secara tepat dengan sifat massa fenomena yang secara totalitasnya menghasilkan variabel acak yang tunduk pada hukum yang terdefinisi dengan baik. Inti dari stabilitas fenomena massa adalah sebagai berikut: ciri-ciri khusus dari setiap fenomena acak individu hampir tidak berpengaruh pada hasil rata-rata massa dari fenomena tersebut; penyimpangan acak dari rata-rata, tak terelakkan dalam setiap fenomena individu, dalam massa saling dibatalkan, diratakan, diratakan.
Kestabilan rata-rata inilah yang merupakan isi fisik dari "hukum bilangan besar", yang dipahami dalam arti luas: dengan sejumlah besar fenomena acak, hasilnya praktis tidak lagi acak dan dapat diprediksi dengan tingkat kepastian yang tinggi.
Dalam arti kata yang sempit, "hukum bilangan besar" dalam teori probabilitas dipahami sebagai sejumlah teorema matematika, di mana masing-masing, untuk kondisi tertentu, fakta perkiraan karakteristik rata-rata dari sejumlah besar eksperimen untuk beberapa konstanta tertentu ditetapkan.
Hukum bilangan besar memainkan peran penting dalam aplikasi praktis teori probabilitas. Properti variabel acak dalam kondisi tertentu untuk berperilaku praktis sebagai variabel non-acak memungkinkan kita untuk beroperasi dengan percaya diri dengan jumlah ini, untuk memprediksi hasil fenomena acak massa dengan kepastian yang hampir lengkap.
Kemungkinan prediksi semacam itu di bidang fenomena acak massa semakin diperluas dengan adanya kelompok teorema limit lain, yang tidak lagi menyangkut nilai batas variabel acak, tetapi hukum distribusi batas. Ini adalah sekelompok teorema yang dikenal sebagai "teorema limit pusat". Bentuk yang berbeda dari teorema limit pusat berbeda satu sama lain dalam kondisi di mana sifat batas dari jumlah variabel acak ini ditetapkan.
Berbagai bentuk hukum bilangan besar dengan berbagai bentuk teorema limit pusat membentuk himpunan yang disebut teorema limit teori probabilitas. Teorema batas memungkinkan tidak hanya untuk membuat prakiraan ilmiah di bidang fenomena acak, tetapi juga untuk mengevaluasi keakuratan prakiraan ini.
Variabel acak disebut terdistribusi menurut hukum normal (Gaussian) dengan parameter sebuah dan () , jika densitas distribusi probabilitas memiliki bentuk
Suatu nilai yang didistribusikan menurut hukum normal selalu memiliki jumlah kemungkinan nilai yang tak terbatas, sehingga lebih mudah untuk menggambarkannya secara grafis, menggunakan grafik kepadatan distribusi. Menurut rumus
probabilitas bahwa variabel acak akan mengambil nilai dari interval sama dengan area di bawah grafik fungsi pada interval ini (makna geometris dari integral tertentu). Fungsi yang dipertimbangkan adalah non-negatif dan kontinu. Grafik suatu fungsi berbentuk lonceng dan disebut kurva Gaussian atau kurva normal.
Gambar tersebut menunjukkan beberapa kurva densitas distribusi dari variabel acak yang ditentukan menurut hukum normal.
Semua kurva memiliki satu titik maksimum, dari mana kurva menurun ke kanan dan ke kiri. Maksimum dicapai pada dan sama dengan .
Kurvanya simetris terhadap garis lurus vertikal yang ditarik melalui titik tertinggi. Luas subplot masing-masing kurva adalah 1.
Perbedaan antara kurva distribusi individu hanya terletak pada kenyataan bahwa luas total subplot, yang sama untuk semua kurva, didistribusikan dengan cara yang berbeda antara bagian yang berbeda. Bagian utama dari area subgraf kurva apa pun terkonsentrasi di sekitar nilai yang paling mungkin, dan nilai ini berbeda untuk ketiga kurva. Untuk nilai yang berbeda dan sebuah berbagai hukum normal dan berbagai grafik densitas fungsi distribusi diperoleh.
Studi teoritis telah menunjukkan bahwa sebagian besar variabel acak yang ditemui dalam praktek memiliki hukum distribusi normal. Menurut hukum ini, kecepatan molekul gas, berat bayi baru lahir, ukuran pakaian dan sepatu penduduk negara itu, dan banyak peristiwa acak lainnya yang bersifat fisik dan biologis didistribusikan. Untuk pertama kalinya pola ini diperhatikan dan didukung secara teoritis oleh A. De Moivre.
Untuk , fungsi bertepatan dengan fungsi , yang telah dibahas dalam teorema limit lokal Moivre–Laplace. Kepadatan probabilitas dari distribusi normal itu mudah diungkapkan melalui:
Untuk nilai parameter seperti itu, hukum normal disebut utama .
Fungsi distribusi untuk densitas ternormalisasi disebut Fungsi Laplace dan dilambangkan (x). Kami juga telah memenuhi fungsi ini.
Fungsi Laplace tidak bergantung pada parameter tertentu sebuah dan . Untuk fungsi Laplace, menggunakan metode integrasi perkiraan, tabel nilai pada interval dikompilasi dengan berbagai tingkat akurasi. Jelas bahwa fungsi Laplace ganjil, oleh karena itu, tidak perlu memasukkan nilainya ke dalam tabel untuk negatif .
Untuk variabel acak yang terdistribusi menurut hukum normal dengan parameter sebuah dan , harapan matematis dan varians dihitung dengan rumus: , Standar deviasi sama dengan .
Probabilitas bahwa kuantitas yang terdistribusi normal mengambil nilai dari interval sama dengan
di mana fungsi Laplace diperkenalkan dalam teorema limit integral.
Seringkali dalam masalah diperlukan untuk menghitung probabilitas bahwa deviasi dari variabel acak terdistribusi normal X dari harapan matematisnya dalam nilai absolut tidak melebihi beberapa nilai , yaitu menghitung probabilitas. Menerapkan rumus (19.2), kami memiliki:
Sebagai kesimpulan, kami menyajikan satu konsekuensi penting dari formula (19.3). Mari kita masukkan ke dalam rumus ini. Kemudian , yaitu probabilitas bahwa nilai absolut dari deviasi X dari ekspektasi matematisnya tidak akan melebihi , sebesar 99,73%. Dalam praktiknya, peristiwa semacam itu dapat dianggap dapat diandalkan. Ini adalah inti dari aturan tiga sigma.
Aturan tiga sigma. Jika suatu peubah acak terdistribusi normal, maka nilai mutlak simpangannya dari harapan matematis praktis tidak melebihi tiga kali simpangan baku.
Artikel ini menunjukkan secara rinci apa hukum distribusi normal dari variabel acak dan bagaimana menggunakannya dalam memecahkan masalah praktis.
Distribusi normal dalam statistik
Sejarah hukum memiliki 300 tahun. Penemu pertama adalah Abraham de Moivre, yang datang dengan perkiraan sedini 1733. Bertahun-tahun kemudian, Carl Friedrich Gauss (1809) dan Pierre-Simon Laplace (1812) menurunkan fungsi matematika.
Laplace juga menemukan keteraturan yang luar biasa dan diformulasikan teorema limit pusat (CPT), yang menurutnya jumlah dari sejumlah besar variabel kecil dan independen memiliki distribusi normal.
Hukum normal bukanlah persamaan tetap tentang bagaimana satu variabel tergantung pada yang lain. Hanya sifat ketergantungan ini yang tetap. Bentuk distribusi spesifik ditentukan oleh parameter khusus. Sebagai contoh, y = kapak + b adalah persamaan garis lurus. Namun, di mana tepatnya ia lewat dan pada kemiringan apa ditentukan oleh parameter sebuah dan b. Sama dengan distribusi normal. Jelas bahwa ini adalah fungsi yang menggambarkan kecenderungan konsentrasi nilai yang tinggi di dekat pusat, tetapi bentuk persisnya diberikan oleh parameter khusus.
Kurva distribusi normal Gaussian memiliki bentuk sebagai berikut.
Grafik distribusi normal menyerupai lonceng, sehingga Anda dapat melihat namanya kurva lonceng. Grafik memiliki "punuk" di tengah dan penurunan kepadatan yang tajam di tepinya. Ini adalah inti dari distribusi normal. Probabilitas bahwa variabel acak akan berada di dekat pusat jauh lebih tinggi daripada yang sangat menyimpang dari tengah.

Gambar di atas menunjukkan dua area di bawah kurva Gaussian: biru dan hijau. Alasan, yaitu interval sama di kedua bagian. Tetapi ketinggiannya sangat berbeda. Area biru jauh dari pusat, dan memiliki ketinggian yang jauh lebih rendah daripada area hijau, yang terletak di pusat distribusi. Akibatnya, area juga berbeda, yaitu, probabilitas jatuh ke dalam interval yang ditunjukkan.
Rumus untuk distribusi normal (densitas) adalah sebagai berikut.
![]()
Rumus terdiri dari dua konstanta matematika:
π – nomor pi 3.142;
e– dasar logaritma natural 2,718;
dua parameter variabel yang menentukan bentuk kurva tertentu:
m– ekspektasi matematis (notasi lain dapat digunakan dalam berbagai sumber, misalnya, µ atau sebuah);
2- dispersi;
baik, variabel itu sendiri x, yang kepadatan probabilitasnya dihitung.
Bentuk spesifik dari distribusi normal tergantung pada 2 parameter: ( m) dan ( 2). Dilambangkan secara singkat N(m, 2) atau N(m, ). Parameter m(Ekspektasi) menentukan pusat distribusi, yang sesuai dengan ketinggian maksimum grafik. Penyebaran 2 mencirikan rentang variasi, yaitu "pengolesan" data.
Parameter ekspektasi matematis menggeser pusat distribusi ke kanan atau ke kiri tanpa mempengaruhi bentuk kurva densitas.

Tetapi dispersi menentukan ketajaman kurva. Ketika data memiliki sebaran kecil, maka semua massanya terkonsentrasi di pusat. Jika data memiliki sebaran yang besar, maka data tersebut “diolesi” pada rentang yang luas.

Kepadatan distribusi tidak memiliki aplikasi praktis langsung. Untuk menghitung probabilitas, Anda perlu mengintegrasikan fungsi kepadatan.
Probabilitas bahwa variabel acak akan kurang dari beberapa nilai x, ditentukan fungsi distribusi normal:
Dengan menggunakan sifat matematis dari setiap distribusi kontinu, tidak sulit untuk menghitung probabilitas lainnya, karena
P(a X< b) = Ф(b) – Ф(a)
distribusi normal standar
Distribusi normal tergantung pada parameter mean dan varians, itulah sebabnya sifat-sifatnya kurang terlihat. Alangkah baiknya jika ada standar distribusi yang tidak bergantung pada skala data. Dan dia ada. ditelepon distribusi normal standar. Sebenarnya, ini adalah distribusi normal biasa, hanya dengan parameter ekspektasi matematis 0, dan variansnya adalah 1, ditulis N(0, 1).
Setiap distribusi normal dapat dengan mudah diubah menjadi distribusi standar dengan melakukan normalisasi:
di mana z adalah variabel baru yang digunakan sebagai pengganti x;
m- nilai yang diharapkan;
σ
- simpangan baku.
Untuk data sampel, perkiraan diambil:
Rata-rata aritmatika dan varians dari variabel baru z sekarang juga sama dengan 0 dan 1, masing-masing. Ini mudah diverifikasi dengan bantuan transformasi aljabar dasar.
Nama muncul dalam literatur z-skor. Ini dia - data yang dinormalisasi. Z-skor dapat langsung dibandingkan dengan probabilitas teoretis, karena skalanya sesuai standar.
Sekarang mari kita lihat seperti apa densitas dari distribusi normal standar (untuk z-skor). Biarkan saya mengingatkan Anda bahwa fungsi Gaussian memiliki bentuk:
![]()
Pengganti bukannya (x-m)/ surat z, melainkan σ - satu, kita dapatkan fungsi densitas dari distribusi normal standar:
![]()
Grafik Kepadatan:

Pusat, seperti yang diharapkan, berada di titik 0. Pada titik yang sama, fungsi Gaussian mencapai maksimumnya, yang sesuai dengan variabel acak yang mengambil nilai rata-ratanya (yaitu, x-m=0). Kepadatan pada titik ini adalah 0,3989, yang dapat dihitung bahkan dalam pikiran, karena. e 0 =1 dan tetap menghitung hanya rasio 1 ke akar 2 pi.
Dengan demikian, grafik dengan jelas menunjukkan bahwa nilai-nilai yang memiliki penyimpangan kecil dari rata-rata lebih sering jatuh daripada yang lain, dan yang sangat jauh dari pusat jauh lebih jarang. Skala absis diukur dalam deviasi standar, yang memungkinkan Anda untuk menyingkirkan unit pengukuran dan mendapatkan struktur universal dari distribusi normal. Kurva Gaussian untuk data yang dinormalisasi dengan sempurna menunjukkan sifat-sifat lain dari distribusi normal. Misalnya simetris terhadap sumbu y. Dalam ±1σ dari rata-rata aritmatika, sebagian besar dari semua nilai terkonsentrasi (kami masih memperkirakan dengan mata). Sebagian besar data berada dalam ±2σ. Hampir semua data berada dalam ±3σ. Properti terakhir umumnya dikenal sebagai aturan tiga sigma untuk distribusi normal.
Fungsi distribusi normal standar memungkinkan Anda menghitung probabilitas.
![]()
Tentu saja, tidak ada yang menghitung dengan tangan. Semuanya dihitung dan ditempatkan dalam tabel khusus, yang ada di akhir setiap buku teks tentang statistik.
Tabel distribusi normal
Tabel distribusi normal terdiri dari dua jenis:
- meja kepadatan;
- meja fungsi(kepadatan integral).
Meja kepadatan jarang digunakan. Namun, mari kita lihat seperti apa bentuknya. Katakanlah kita perlu mendapatkan kepadatan untuk z = 1, yaitu kepadatan nilai yang 1 sigma jauh dari nilai yang diharapkan. Di bawah ini adalah sebagian dari tabel.

Bergantung pada organisasi data, kami mencari nilai yang diinginkan dengan nama kolom dan baris. Dalam contoh kami, kami mengambil garis 1,0 dan kolom 0 , karena tidak ada seperseratus. Nilai yang diinginkan adalah 0,2420 (0 sebelum 2420 dihilangkan).
Fungsi Gaussian simetris terhadap sumbu y. Itu sebabnya (z)= (-z), yaitu kepadatan untuk 1 identik dengan densitas untuk -1 , yang terlihat jelas pada gambar.

Agar tidak membuang kertas, tabel dicetak hanya untuk nilai positif.
Dalam praktiknya, nilai sering digunakan fungsi distribusi normal standar, yaitu peluang untuk z.
Tabel tersebut juga hanya berisi nilai positif. Oleh karena itu, untuk memahami dan menemukan setiap probabilitas yang diperlukan harus diketahui sifat-sifat distribusi normal standar.
Fungsi (z) simetris tentang nilainya 0,5 (dan bukan sumbu y, seperti kepadatan). Oleh karena itu persamaannya benar:
Fakta ini ditunjukkan dalam gambar:

Nilai fungsi (-z) dan (z) membagi grafik menjadi 3 bagian. Selain itu, bagian atas dan bawah adalah sama (ditunjukkan dengan tanda centang). Untuk menyelesaikan probabilitas (z) ke 1, tambahkan saja nilai yang hilang (-z). Anda mendapatkan persamaan yang sama seperti di atas.
Jika Anda perlu mencari peluang jatuh ke dalam interval (0;z), yaitu, probabilitas penyimpangan dari nol dalam arah positif ke sejumlah standar deviasi tertentu, cukup untuk mengurangi 0,5 dari nilai fungsi distribusi normal standar:

Agar lebih jelas, Anda dapat melihat gambar.

Pada kurva Gaussian, situasi yang sama terlihat seperti area dari pusat ke kanan untuk z.

Cukup sering, analis tertarik pada probabilitas penyimpangan di kedua arah dari nol. Dan karena fungsinya simetris terhadap pusat, rumus sebelumnya harus dikalikan dengan 2:

Gambar di bawah.

Di bawah kurva Gaussian, ini adalah bagian tengah, dibatasi oleh nilai yang dipilih -z kiri dan z di kanan.

Sifat-sifat ini harus diperhitungkan, karena nilai tabel jarang sesuai dengan interval yang diinginkan.
Untuk memudahkan tugas, buku teks biasanya menerbitkan tabel untuk fungsi formulir:

Jika Anda membutuhkan probabilitas deviasi di kedua arah dari nol, maka, seperti yang baru saja kita lihat, nilai tabel untuk fungsi ini dikalikan dengan 2.
Sekarang mari kita lihat contoh spesifik. Di bawah ini adalah tabel distribusi normal standar. Mari kita temukan nilai tabular untuk tiga z: 1.64, 1.96 dan 3.

Bagaimana memahami arti angka-angka ini? Mari kita mulai dengan z=1.64, yang nilai tabelnya adalah 0,4495 . Cara termudah untuk menjelaskan artinya adalah pada gambar.

Artinya, probabilitas bahwa variabel acak terstandarisasi terdistribusi normal berada dalam interval dari 0 sebelum 1,64 , adalah sama dengan 0,4495 . Saat memecahkan masalah, biasanya perlu menghitung probabilitas penyimpangan di kedua arah, jadi kami mengalikan nilainya 0,4495 dengan 2 dan dapatkan sekitar 0,9. Area yang ditempati di bawah kurva Gaussian ditunjukkan di bawah ini.

Dengan demikian, 90% dari semua nilai yang terdistribusi normal berada dalam interval ±1,64σ dari rata-rata aritmatika. Saya tidak memilih artinya secara kebetulan z=1.64, karena lingkungan sekitar mean aritmatika, menempati 90% dari total luas, kadang-kadang digunakan untuk menghitung interval kepercayaan. Jika nilai yang diperiksa tidak jatuh ke area yang ditentukan, maka kemunculannya tidak mungkin (hanya 10%).
Namun, untuk menguji hipotesis, interval yang mencakup 95% dari semua nilai lebih sering digunakan. Setengah dari kemungkinan 0,95 - ini 0,4750 (lihat nilai kedua yang disorot dalam tabel).

Untuk kemungkinan ini z=1,96. Itu. dalam hampir ±2σ dari rata-rata adalah 95% dari nilai-nilai. Hanya 5% yang berada di luar batas ini.

Nilai tabel lain yang menarik dan sering digunakan sesuai dengan z=3, itu sama menurut tabel kami 0,4986 . Kalikan dengan 2 dan dapatkan 0,997 . Jadi, dalam kerangka ±3σ hampir semua nilai dimasukkan dari mean aritmatika.

Ini adalah bagaimana aturan 3 sigma terlihat seperti distribusi normal pada grafik.
Dengan bantuan tabel statistik, Anda bisa mendapatkan probabilitas apa pun. Namun, metode ini sangat lambat, tidak nyaman, dan sangat ketinggalan zaman. Hari ini semuanya dilakukan di komputer. Selanjutnya, kita beralih ke praktik perhitungan di Excel.
Distribusi normal di Excel
Excel memiliki beberapa fungsi untuk menghitung probabilitas atau kebalikan dari distribusi normal.

Fungsi NORM.S.DIST
Fungsi NORM.ST.DIST dirancang untuk menghitung kepadatan (z) atau probabilitas (z) menurut data yang dinormalisasi ( z).
= NORM.ST.DIST(z, kumulatif)
z adalah nilai dari variabel standar
integral– jika 0, maka densitasnya dihitung(z) , jika 1 adalah nilai fungsi (z), mis. probabilitas P(Z
Hitung kerapatan dan nilai fungsi untuk berbagai z: -3, -2, -1, 0, 1, 2, 3(kami akan menunjukkannya di sel A2).
Untuk menghitung densitas, Anda memerlukan rumus =NORM.ST.DIST(A2;0). Dalam diagram di bawah, ini adalah titik merah.
Untuk menghitung nilai fungsi =NORM.ST.DIST(A2;1). Rajah menunjukkan daerah yang diarsir di bawah kurva normal.

Pada kenyataannya, lebih sering diperlukan untuk menghitung probabilitas bahwa variabel acak tidak akan melampaui beberapa batas dari rata-rata (dalam deviasi standar yang sesuai dengan variabel z), yaitu P(|Z|

Mari kita tentukan berapa probabilitas bahwa variabel acak akan jatuh dalam batas ±1z, ±2z dan ±3z dari nol. Diperlukan rumus 2Ф(z)-1, di Excel =2*NORM.ST.DIST(A2;1)-1.

Diagram dengan jelas menunjukkan sifat dasar utama dari distribusi normal, termasuk aturan tiga sigma. Fungsi NORM.ST.DIST adalah spreadsheet otomatis nilai fungsi distribusi normal di Excel.
Mungkin juga ada masalah terbalik: menurut probabilitas yang tersedia P(Z
Fungsi NORM.ST.INV
NORM.ST.INV menghitung kebalikan dari fungsi distribusi normal standar. Sintaksnya terdiri dari satu parameter:
=NORM.S.OBR(probabilitas)
kemungkinan adalah probabilitas.
Rumus ini digunakan sesering yang sebelumnya, karena tabel yang sama harus mencari tidak hanya probabilitas, tetapi juga kuantil.

Misalnya, saat menghitung interval kepercayaan, probabilitas kepercayaan ditentukan, yang menurutnya perlu untuk menghitung nilainya z.

Mengingat bahwa selang kepercayaan terdiri dari batas atas dan batas bawah dan bahwa distribusi normal simetris terhadap nol, maka cukup untuk memperoleh batas atas (deviasi positif). Batas bawah diambil dengan tanda negatif. Mari kita nyatakan probabilitas kepercayaan sebagai γ (gamma), maka batas atas selang kepercayaan dihitung dengan menggunakan rumus berikut.
![]()
Hitung nilai di Excel z(yang sesuai dengan deviasi dari rata-rata dalam sigma) untuk beberapa probabilitas, termasuk yang diketahui oleh setiap ahli statistik: 90%, 95%, dan 99%. Di sel B2, masukkan rumus: =NORM.ST.OBR((1+A2)/2). Dengan mengubah nilai variabel (probabilitas di sel A2), kami mendapatkan batas interval yang berbeda.

Interval kepercayaan untuk 95% adalah 1,96, yang hampir 2 standar deviasi. Dari sini mudah bahkan dalam pikiran untuk memperkirakan kemungkinan penyebaran variabel acak normal. Secara umum, interval kepercayaan 90%, 95%, dan 99% sesuai dengan ±1,64, ±1,96, dan ±2,58 interval kepercayaan.
Secara umum, fungsi NORM.ST.DIST dan NORM.ST.OBR memungkinkan Anda untuk melakukan perhitungan apa pun yang terkait dengan distribusi normal. Tetapi untuk mempermudah dan mengurangi pekerjaan, Excel memiliki beberapa fitur lain. Misalnya, untuk menghitung interval kepercayaan untuk mean, Anda dapat menggunakan CONFID.NORM. Untuk memeriksa mean aritmatika ada rumus Z.TEST.
Pertimbangkan beberapa formula yang lebih berguna dengan contoh.
Fungsi NORM.DIST
Fungsi NORM.DIST berbeda dari NORM.ST.DIST hanya dengan fakta bahwa itu digunakan untuk memproses data dari skala apa pun, dan bukan hanya yang dinormalisasi. Parameter distribusi normal ditentukan dalam sintaks.
=NORM.DIST(x, mean, standard_dev, kumulatif)
rata-rata adalah ekspektasi matematis yang digunakan sebagai parameter pertama dari model distribusi normal
standar_off– simpangan baku – parameter kedua dari model
integral- jika 0, maka densitas dihitung, jika 1 - maka nilai fungsinya, yaitu. P(X
Misalnya, densitas untuk nilai 15, yang diambil dari sampel normal dengan rata-rata 10, standar deviasi 3, dihitung sebagai berikut:

Jika parameter terakhir diatur ke 1, maka kita mendapatkan probabilitas bahwa variabel acak normal akan kurang dari 15 untuk parameter distribusi yang diberikan. Dengan demikian, probabilitas dapat dihitung langsung dari data asli.
Fungsi NORM.INV
Ini adalah kuantil dari distribusi normal, yaitu nilai fungsi kebalikannya. Sintaksnya adalah sebagai berikut.
=NORM.INV(probabilitas, mean, standar deviasi)
kemungkinan- kemungkinan
rata-rata- ekspektasi
standar_off– simpangan baku
Tujuannya sama dengan NORM.ST.INV, hanya fungsi yang berfungsi dengan data skala apa pun.
Contohnya ditunjukkan dalam video di akhir artikel.
Pemodelan Distribusi Normal
Beberapa tugas memerlukan pembuatan bilangan acak normal. Tidak ada fungsi siap pakai untuk ini. Namun, Excel memiliki dua fungsi yang mengembalikan angka acak: RANDOMantara dan RAND. Yang pertama menghasilkan bilangan bulat yang terdistribusi secara acak dalam batas yang ditentukan. Fungsi kedua menghasilkan angka acak terdistribusi merata antara 0 dan 1. Untuk membuat sampel buatan dengan distribusi tertentu, Anda memerlukan fungsi RAND.
Misalkan untuk percobaan itu perlu untuk mendapatkan sampel dari populasi umum yang terdistribusi normal dengan rata-rata 10 dan standar deviasi 3. Untuk satu nilai acak, kami akan menulis rumus di Excel.
NORM.INV(RAND();10;3)
Mari kita perluas ke jumlah sel yang diperlukan dan seleksi normal sudah siap.
Untuk memodelkan data standar, Anda harus menggunakan NORM.ST.OBR.
Proses pengubahan bilangan seragam menjadi bilangan normal dapat ditunjukkan pada diagram berikut. Dari probabilitas seragam yang dihasilkan oleh rumus RAND, garis horizontal ditarik ke grafik fungsi distribusi normal. Kemudian, proyeksi ke sumbu horizontal diturunkan dari titik perpotongan probabilitas dengan grafik.