Sannolikhet för en normalfördelad stokastisk variabel. Normal sannolikhetsfördelningslag för en kontinuerlig stokastisk variabel. Förhållande till andra distributioner
Ersätter φ(x)=π /4 ,f(x)=1/(b-a)
D[π /4]=( /720) ).
№319 kubkant x uppmätt ungefär, och a . Betrakta kanten på en kub som en slumpvariabel X, fördelad enhetligt i intervallet (a, b), hitta den matematiska förväntan och variansen för kubens volym.
1. Låt oss hitta den matematiska förväntan av arean av en cirkel - en slumpvariabel Y=φ(K)= - enligt formeln
M[φ(X)]= ![]()
Genom att placera φ(x)= ,f(x)=1/(b-a) och utför integration, får vi
M( )=
 .
.
2. Hitta spridningen av arean av en cirkel med hjälp av formeln
D [φ(X)]= ![]() -
-
![]() .
.
Ersätter φ(x)= ,f(x)=1/(b-a) och utför integration, får vi
D =
 .
.
№320 Slumpvariabler X och Y är oberoende och fördelade enhetligt: X i intervallet (a,b), Y i intervallet (c,d) Hitta den matematiska förväntan av produkten XY.
Den matematiska förväntan av produkten av oberoende slumpvariabler är lika med produkten av deras matematiska förväntningar, d.v.s.
M(XY)= 
№321 Slumpvariablerna X och Y är oberoende och fördelade enhetligt: X i intervallet (a,b), Y i intervallet (c,d). Hitta variansen för produkten XY.
Låt oss använda formeln
D(XY)=M[
Den matematiska förväntan av produkten av oberoende slumpvariabler är lika med produkten av deras matematiska förväntningar, därför
Låt oss hitta M med hjälp av formeln
M[φ(X)]= ![]()
Ersätter φ(x)= ,f(x)=1/(b-a) och utför integration, får vi
M (**)
Vi kan hitta på liknande sätt
M (***)
Ersätter M(X)=(a+b)/2, M(Y)=(c+d)/2, samt (***) och (**) i (*) får vi äntligen
D(XY)= -[
![]() .
.
№322 Den matematiska förväntan på en normalfördelad stokastisk variabel X är a=3 och standardavvikelsen σ=2. Skriv sannolikhetstätheten för X.
Låt oss använda formeln:
f(x)=  .
.
Genom att ersätta de tillgängliga värdena får vi:
f(x)=  =f(x)=
=f(x)=  .
.
№323 Skriv sannolikhetstätheten för en normalfördelad stokastisk variabel X, med vetskap om att M(X)=3, D(X)=16.
Låt oss använda formeln:
f(x)= .
För att hitta värdet på σ använder vi egenskapen att standardavvikelsen för en slumpvariabel X lika med kvadratroten av dess varians. Därför σ=4, M(X)=a=3. Ersätter i formeln vi får
f(x)=  =
=
 .
.
№324 En normalfördelad stokastisk variabel X ges av densitet
f(x)= ![]() .
Hitta den matematiska förväntan och variansen för X.
.
Hitta den matematiska förväntan och variansen för X.
Låt oss använda formeln
f(x)= ,
Var a-förväntat värde, σ - standardavvikelse X. Av denna formel följer att a=M(X)=1. För att hitta variansen använder vi egenskapen som standardavvikelsen för en slumpvariabel X lika med kvadratroten av dess varians. Därav D(X)= =
Svar: matematisk förväntan är 1; variansen är 25.
Bondarchuk Rodion
Givet fördelningsfunktionen för den normaliserade normallagen ![]() . Hitta fördelningsdensiteten f(x).
. Hitta fördelningsdensiteten f(x).
Veta att ![]() , hitta f(x).
, hitta f(x).

Svar: ![]()
Bevisa att Laplace fungerar ![]() . udda:
. udda: ![]() .
.

Vi kommer att göra en ersättare


Vi gör det omvända utbytet och får:
![]() =
= ![]() =
=


Det kommer också att finnas problem för dig att lösa på egen hand, som du kan se svaren på.
Normalfördelning: teoretiska grunder
Exempel på slumpvariabler fördelade enligt en normallag är längden på en person och massan av fiskar av samma art som fångas. Normalfördelning innebär följande : det finns värden för mänsklig höjd, massan av fiskar av samma art, som intuitivt uppfattas som "normala" (och faktiskt genomsnittliga), och i ett tillräckligt stort urval finns de mycket oftare än de som skiljer sig uppåt eller nedåt.
Den normala sannolikhetsfördelningen för en kontinuerlig slumpvariabel (ibland en Gauss-fördelning) kan kallas klockformad på grund av att densitetsfunktionen för denna fördelning, symmetrisk om medelvärdet, är mycket lik snittet av en klocka (röd kurva) i figuren ovan).
Sannolikheten för att stöta på vissa värden i ett prov är lika med arean av figuren under kurvan, och i fallet med en normalfördelning ser vi det under toppen av "klockan", vilket motsvarar värden Med hänsyn till genomsnittet är arean och därmed sannolikheten större än under kanterna. Således får vi samma sak som redan har sagts: sannolikheten att träffa en person av "normal" längd och fånga en fisk med "normal" vikt är högre än för värden som skiljer sig uppåt eller nedåt. I många praktiska fall fördelas mätfel enligt en lag nära det normala.
Låt oss titta igen på figuren i början av lektionen, som visar densitetsfunktionen för en normalfördelning. Grafen för denna funktion erhölls genom att beräkna ett visst dataprov i mjukvarupaketet STATISTIK. På den representerar histogramkolumnerna intervall av provvärden, vars fördelning är nära (eller, som det brukar sägas i statistik, inte skiljer sig väsentligt från) den faktiska grafen för normalfördelningstäthetsfunktionen, som är en röd kurva . Grafen visar att denna kurva verkligen är klockformad.
Normalfördelningen är värdefull på många sätt eftersom du bara känner till det förväntade värdet av en kontinuerlig slumpvariabel och dess standardavvikelse, och du kan beräkna vilken sannolikhet som helst som är associerad med den variabeln.
Normalfördelningen har också fördelen att vara en av de enklaste att använda. statistiska tester som används för att testa statistiska hypoteser - Elevens t-test- kan endast användas om provdata följer normalfördelningslagen.
Densitetsfunktion av normalfördelningen av en kontinuerlig stokastisk variabel kan hittas med formeln:
 ,
,
Var x- värdet på den ändrade kvantiteten, - medelvärde, - standardavvikelse, e=2,71828... - basen för den naturliga logaritmen, =3,1416...
Egenskaper för normalfördelningstäthetsfunktionen
Förändringar i medelvärdet flyttar den normala densitetsfunktionskurvan mot axeln Oxe. Om den ökar, flyttas kurvan åt höger, om den minskar, sedan till vänster.
Om standardavvikelsen ändras ändras höjden på toppen av kurvan. När standardavvikelsen ökar är toppen av kurvan högre och när den minskar är den lägre.
Sannolikhet för att en normalfördelad stokastisk variabel faller inom ett givet intervall
Redan i detta stycke kommer vi att börja lösa praktiska problem, vars innebörd anges i titeln. Låt oss titta på vilka möjligheter teorin ger för att lösa problem. Utgångskonceptet för att beräkna sannolikheten för att en normalfördelad stokastisk variabel faller in i ett givet intervall är den kumulativa funktionen av normalfördelningen.
Kumulativ normalfördelningsfunktion:
 .
.
Det är dock problematiskt att få fram tabeller för varje möjlig kombination av medelvärde och standardavvikelse. Därför är ett av de enkla sätten att beräkna sannolikheten för att en normalfördelad stokastisk variabel faller in i ett givet intervall att använda sannolikhetstabeller för den standardiserade normalfördelningen.
En normalfördelning kallas standardiserad eller normaliserad., vars medelvärde är , och standardavvikelsen är .
Standardiserad normalfördelningstäthetsfunktion:
![]() .
.
Kumulativ funktion av den standardiserade normalfördelningen:
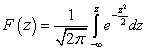 .
.
Figuren nedan visar integralfunktionen för den standardiserade normalfördelningen, vars graf erhölls genom att beräkna ett visst dataprov i mjukvarupaketet STATISTIK. Själva grafen är en röd kurva och provvärdena närmar sig den.

För att förstora bilden kan du klicka på den med vänster musknapp.
Att standardisera en slumpmässig variabel innebär att man går från de ursprungliga enheterna som används i uppgiften till standardiserade enheter. Standardisering utförs enligt formeln
I praktiken är alla möjliga värden för en slumpvariabel ofta okända, så värdena för medelvärdet och standardavvikelsen kan inte bestämmas exakt. De ersätts av det aritmetiska medelvärdet av observationer och standardavvikelse s. Magnitud z uttrycker avvikelserna av värdena för en slumpvariabel från det aritmetiska medelvärdet vid mätning av standardavvikelser.
Öppet intervall
Sannolikhetstabellen för den standardiserade normalfördelningen, som finns i nästan vilken bok som helst om statistik, innehåller sannolikheterna för att en slumpvariabel har en standardnormalfördelning Z kommer att ta ett värde mindre än ett visst tal z. Det vill säga, det kommer att falla in i det öppna intervallet från minus oändlighet till z. Till exempel sannolikheten för att kvantiteten Z mindre än 1,5, lika med 0,93319.
Exempel 1. Företaget tillverkar delar vars livslängd är normalfördelad med i medeltal 1000 timmar och en standardavvikelse på 200 timmar.
För en slumpmässigt vald del, beräkna sannolikheten att dess livslängd kommer att vara minst 900 timmar.
Lösning. Låt oss presentera den första notationen:
Den önskade sannolikheten.
Slumpvariabelvärdena är i ett öppet intervall. Men vi vet hur man beräknar sannolikheten för att en slumpmässig variabel kommer att ta ett värde som är mindre än en given, och enligt villkoren för problemet måste vi hitta en lika med eller större än en given. Detta är den andra delen av utrymmet under den normala densitetskurvan (klocka). Därför, för att hitta den önskade sannolikheten, måste du subtrahera från enhet den nämnda sannolikheten att den slumpmässiga variabeln kommer att ta ett värde mindre än den angivna 900:
Nu måste den slumpmässiga variabeln standardiseras.
Vi fortsätter att introducera notationen:
z = (X ≤ 900) ;
x= 900 - specificerat värde för den slumpmässiga variabeln;
μ = 1000 - medelvärde;
σ = 200 - standardavvikelse.
Med hjälp av dessa data får vi villkoren för problemet:
![]() .
.
Enligt tabeller med standardiserad slumpvariabel (intervallgräns) z= −0,5 motsvarar en sannolikhet på 0,30854. Subtrahera det från enhet och få det som krävs i problemformuleringen:
Så sannolikheten att delen kommer att ha en livslängd på minst 900 timmar är 69%.
Denna sannolikhet kan erhållas med MS Excel-funktionen NORM.DIST (integralvärde - 1):
P(X≥900) = 1 - P(X≤900) = 1 - NORM.FÖRD(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
Om beräkningar i MS Excel - i ett av de efterföljande styckena i denna lektion.
Exempel 2. I en viss stad är den genomsnittliga årliga familjeinkomsten en normalfördelad stokastisk variabel med ett medelvärde på 300 000 och en standardavvikelse på 50 000. Det är känt att inkomsten för 40 % av familjerna är mindre än A. Hitta värdet A.
Lösning. I det här problemet är 40 % inget annat än sannolikheten att den slumpmässiga variabeln tar ett värde från ett öppet intervall som är mindre än ett visst värde, indikerat med bokstaven A.
För att hitta värdet A, först komponerar vi integralfunktionen:
![]()
Enligt förutsättningarna för problemet
μ = 300 000 - medelvärde;
σ = 50000 - standardavvikelse;
x = A- den kvantitet som ska hittas.
Att skapa en jämställdhet
![]() .
.
Från de statistiska tabellerna finner vi att sannolikheten 0,40 motsvarar värdet på intervallgränsen z = −0,25 .
Därför skapar vi jämställdheten
![]()
och hitta sin lösning:
A = 287300 .
Svar: 40 % av familjerna har inkomster under 287 300.
Stängt intervall
I många problem krävs att man hittar sannolikheten för att en normalfördelad stokastisk variabel tar ett värde i intervallet från z 1 till z 2. Det vill säga, det kommer att falla in i ett slutet intervall. För att lösa sådana problem är det nödvändigt att i tabellen hitta sannolikheterna som motsvarar intervallets gränser och sedan hitta skillnaden mellan dessa sannolikheter. Detta kräver att man subtraherar det mindre värdet från det större. Exempel på lösningar på dessa vanliga problem är följande, och du ombeds lösa dem själv, och sedan kan du se de rätta lösningarna och svaren.
Exempel 3. Ett företags vinst under en viss period är en slumpmässig variabel som omfattas av normalfördelningslagen med ett medelvärde på 0,5 miljoner. och standardavvikelse 0,354. Bestäm, med två decimaler, sannolikheten för att företagets vinst kommer att vara från 0,4 till 0,6 c.u.
Exempel 4. Längden på den tillverkade delen är en slumpmässig variabel fördelad enligt normallagen med parametrar μ =10 och σ =0,071. Hitta sannolikheten för defekter, exakt med två decimaler, om delens tillåtna dimensioner måste vara 10±0,05.
Tips: i det här problemet måste du, förutom att hitta sannolikheten för att en slumpvariabel faller in i ett slutet intervall (sannolikheten att ta emot en icke-defekt del), utföra ytterligare en åtgärd.

låter dig bestämma sannolikheten för att det standardiserade värdet Z inte mindre -z och inte mer +z, Var z- ett godtyckligt valt värde av en standardiserad slumpvariabel.
En ungefärlig metod för att kontrollera normaliteten hos en fördelning
En ungefärlig metod för att kontrollera normaliteten i fördelningen av provvärden baseras på följande egenskap hos normalfördelning: skevhetskoefficient β 1 och kurtos koefficient β 2 är lika med noll.
Asymmetrikoefficient β 1 numeriskt karaktäriserar den empiriska fördelningens symmetri i förhållande till medelvärdet. Om skevhetskoefficienten är noll, är det aritmetriska medelvärdet, medianen och moden lika: och fördelningsdensitetskurvan är symmetrisk kring medelvärdet. Om asymmetrikoefficienten är mindre än noll (β 1 < 0 ), då är det aritmetiska medelvärdet mindre än medianen, och medianen är i sin tur mindre än mode () och kurvan förskjuts åt höger (jämfört med normalfördelningen). Om asymmetrikoefficienten är större än noll (β 1 > 0 ), då är det aritmetiska medelvärdet större än medianen, och medianen är i sin tur större än läget () och kurvan förskjuts åt vänster (jämfört med normalfördelningen).
Kurtos koefficient β 2 karakteriserar koncentrationen av den empiriska fördelningen kring det aritmetiska medelvärdet i axelns riktning Oj och graden av topp för fördelningsdensitetskurvan. Om kurtos-koefficienten är större än noll, är kurvan mer långsträckt (jämfört med normalfördelningen) längs axeln Oj(grafen är mer toppad). Om kurtos-koefficienten är mindre än noll, är kurvan mer tillplattad (jämfört med normalfördelningen) längs axeln Oj(grafen är mer trubbig).
Asymmetrikoefficienten kan beräknas med MS Excel SKOS-funktionen. Om du markerar en datamatris måste du ange dataintervallet i en "Nummer"-ruta.

Kurtos-koefficienten kan beräknas med MS Excel KURTESS-funktionen. När du kontrollerar en datamatris räcker det också att ange dataintervallet i en "Number"-ruta.

Så, som vi redan vet, med en normalfördelning är koefficienterna för skevhet och kurtos lika med noll. Men vad händer om vi fick skevhetskoefficienter på -0,14, 0,22, 0,43 och kurtos koefficienter på 0,17, -0,31, 0,55? Frågan är ganska rättvis, eftersom vi i praktiken endast har att göra med ungefärliga provvärden av asymmetri och kurtos, som är föremål för en oundviklig, okontrollerad spridning. Därför kan man inte kräva att dessa koefficienter är strikt lika med noll, de får bara vara tillräckligt nära noll. Men vad betyder tillräckligt?
Det krävs att de erhållna empiriska värdena jämförs med acceptabla värden. För att göra detta måste du kontrollera följande ojämlikheter (jämför värdena för modulkoefficienterna med de kritiska värdena - gränserna för hypotestestområdet).
För asymmetrikoefficienten β 1 .
Normalfördelningslagen möter man oftast i praktiken. Huvuddraget som skiljer den från andra lagar är att det är en begränsande lag, som andra distributionslagar närmar sig under mycket vanliga typiska förhållanden.
Definition. En kontinuerlig stokastisk variabel X har normal lag distribution(Gauss lag )med parametrarna a och σ 2 om dess sannolikhetstäthet f(x) ser ut som:
| . | (6.19) |
Normalfördelningskurvan kallas vanligt eller Gaussisk kurva. I fig. 6.5 a), b) visar en normalkurva med parametrar A Och σ 2 och distributionsfunktionsdiagram.
 Låt oss vara uppmärksamma på det faktum att normalkurvan är symmetrisk med avseende på den räta linjen X = A, har ett maximum vid punkten X = A, lika med , och två böjningspunkter X = A σ
med ordinater.
Låt oss vara uppmärksamma på det faktum att normalkurvan är symmetrisk med avseende på den räta linjen X = A, har ett maximum vid punkten X = A, lika med , och två böjningspunkter X = A σ
med ordinater.
Det kan noteras att i det normala lagdensitetsuttrycket indikeras fördelningsparametrarna med bokstäverna A Och σ 2, som vi använde för att beteckna den matematiska förväntan och spridning. Denna slump är ingen tillfällighet. Låt oss betrakta ett teorem som fastställer den probabilistiska teoretiska innebörden av parametrarna för normallagen.
Sats. Den matematiska förväntan av en slumpvariabel X, fördelad enligt en normallag, är lika med parametern a för denna fördelning, dvs.
| M(X) = A, | (6.20) |
och dess spridning – till parametern σ 2, dvs.
| D(X) = σ 2. | (6.21) |
Låt oss ta reda på hur normalkurvan kommer att förändras när parametrarna ändras A Och σ .
Om σ = const, och parametern ändras a (A 1 < A 2 < A 3), dvs. fördelningens symmetricentrum, då kommer normalkurvan att förskjutas längs abskissaxeln utan att ändra dess form (fig. 6.6).

Ris. 6.6

Ris. 6.7
Om A= const och parametern ändras σ , då ändras ordinaten för kurvans maximum f max(a) = . Vid ökning σ ordinatan för maximum minskar, men eftersom arean under någon fördelningskurva måste förbli lika med enhet, blir kurvan plattare och sträcker sig längs x-axeln. När man minskar σ Tvärtom sträcker sig normalkurvan uppåt samtidigt som den komprimeras från sidorna (fig. 6.7).
Så parametern a kännetecknar positionen och parametern σ – formen på en normal kurva.
Normalfördelningslag för en stokastisk variabel med parametrar a= 0 och σ = 1 kallas standard eller normaliserats, och motsvarande normalkurva är standard eller normaliserats.
Svårigheten att direkt hitta fördelningsfunktionen för en stokastisk variabel fördelad enligt normallagen beror på att normalfördelningsfunktionens integral inte uttrycks genom elementära funktioner. Det kan dock beräknas genom en speciell funktion som uttrycker en bestämd integral av uttrycket eller. Denna funktion kallas Laplace funktion, tabeller har sammanställts för det. Det finns många varianter av denna funktion, till exempel:
![]() ,
, ![]() .
.
Vi kommer att använda funktionen
Låt oss betrakta egenskaperna hos en slumpvariabel fördelad enligt en normallag.
1. Sannolikheten för att en stokastisk variabel X, fördelad enligt en normallag, faller in i intervallet [α , β ] lika med
Med den här formeln beräknar vi sannolikheterna för olika värden δ (med hjälp av tabellen med Laplace-funktionsvärden):
på δ = σ = 2Ф(1) = 0,6827;
på δ = 2σ = 2Ф(2) = 0,9545;
på δ = 3σ = 2Ф(3) = 0,9973.
Detta leder till den så kallade " tre sigma regel»:
Om en stokastisk variabel X har en normalfördelningslag med parametrarna a och σ, så är det nästan säkert att dess värden ligger i intervallet(a – 3σ ; a + 3σ ).
Exempel 6.3. Om man antar att längden på män i en viss åldersgrupp är en normalfördelad slumpvariabel X med parametrar A= 173 och σ 2 = 36, hitta:
1. Uttryck av sannolikhetstäthet och fördelningsfunktion för en stokastisk variabel X;
2. Andelen dräkter av 4:e höjden (176 - 183 cm) och andelen dräkter av 3:e höjden (170 - 176 cm), som måste inkluderas i den totala produktionsvolymen för denna åldersgrupp;
3. Formulera "tre sigma-regeln" för en slumpvariabel X.
1. Hitta sannolikhetstätheten
![]()
och fördelningsfunktionen för den slumpmässiga variabeln X
![]() = .
= .
2. Vi finner andelen dräkter med höjd 4 (176 – 182 cm) som en sannolikhet
R(176 ≤ X ≤ 182) = ![]() = Ф(1,5) – Ф(0,5).
= Ф(1,5) – Ф(0,5).
Enligt värdetabellen för Laplace-funktionen ( Bilaga 2) vi hittar:
F(1,5) = 0,4332, F(0,5) = 0,1915.
Äntligen får vi
R(176 ≤ X ≤ 182) = 0,4332 – 0,1915 = 0,2417.
Andelen dräkter av den 3:e höjden (170 – 176 cm) kan hittas på liknande sätt. Det är dock lättare att göra detta om vi tar hänsyn till att detta intervall är symmetriskt med avseende på den matematiska förväntan A= 173, dvs. ojämlikhet 170 ≤ X≤ 176 är ekvivalent med olikhet │ X– 173│≤ 3. Sedan
R(170 ≤X ≤176) = R(│X– 173│≤ 3) = 2Ф(3/6) = 2Ф(0,5) = 2·0,1915 = 0,3830.
3. Låt oss formulera "tre sigma-regeln" för den slumpmässiga variabeln X:
Det är nästan säkert att längden på män i denna åldersgrupp sträcker sig från A – 3σ = 173 – 3 6 = 155 till A + 3σ = 173 + 3,6 = 191, dvs. 155 ≤ X ≤ 191. ◄
7. BEGRÄNSNINGAR FÖR SANNOLIKHETSTEORI
Som redan nämnts när man studerar slumpvariabler är det omöjligt att i förväg förutsäga vilket värde en slumpvariabel kommer att ta som ett resultat av ett enda test - det beror på många skäl som inte kan tas med i beräkningen.
Men när tester upprepas många gånger, förlorar beteendet hos summan av slumpvariabler nästan sin slumpmässiga karaktär och blir naturligt. Förekomsten av mönster är just förknippad med massan av fenomen som i sin helhet genererar en slumpmässig variabel som är föremål för en väldefinierad lag. Kärnan i massfenomenens stabilitet kommer ner på följande: de specifika egenskaperna hos varje enskilt slumpmässigt fenomen har nästan ingen effekt på det genomsnittliga resultatet av massan av sådana fenomen; slumpmässiga avvikelser från genomsnittet, oundvikliga i varje enskilt fenomen, utjämnas ömsesidigt, utjämnas, utjämnas i massan.
Det är denna stabilitet av medelvärden som representerar det fysiska innehållet i "lagen om stora siffror", uppfattad i ordets breda bemärkelse: med ett mycket stort antal slumpmässiga fenomen upphör deras resultat praktiskt taget att vara slumpmässigt och kan förutsägas med en hög grad av säkerhet.
I ordets snäva bemärkelse förstås "lagen om stora siffror" i sannolikhetsteorin som en serie matematiska satser, som var och en, under vissa förhållanden, fastställer det faktum att medelegenskaperna för ett stort antal experiment närmar sig vissa vissa konstanter.
Lagen om stora tal spelar en viktig roll i de praktiska tillämpningarna av sannolikhetsteorin. Egenskapen hos slumpvariabler, under vissa förhållanden, att bete sig nästan som icke-slumpmässiga gör att man med säkerhet kan arbeta med dessa storheter och förutsäga resultaten av slumpmässiga massfenomen med nästan fullständig säkerhet.
Möjligheterna för sådana förutsägelser inom området för slumpmässiga massfenomen utökas ytterligare av närvaron av en annan grupp av gränssatser, som inte rör de gränsvärdena för slumpmässiga variabler, utan de begränsande distributionslagarna. Vi talar om en grupp av satser som kallas "central limit theorem". De olika formerna av den centrala gränssatsen skiljer sig från varandra i de förhållanden för vilka denna begränsande egenskap hos summan av stokastiska variabler är etablerad.
Olika former av lagen om stora tal med olika former av centralgränssatsen bildar en uppsättning s.k. gränssatser sannolikhetsteori. Gränssatser gör det möjligt att inte bara göra vetenskapliga prognoser inom området för slumpmässiga fenomen, utan också att utvärdera exaktheten i dessa prognoser.
Slumpvariabeln kallas fördelade enligt den normala (gaussiska) lagen med parametrar A och () , om sannolikhetsfördelningstätheten har formen
En normalfördelad storhet har alltid ett oändligt antal möjliga värden, så det är bekvämt att avbilda det grafiskt med hjälp av en distributionstäthetsgraf. Enligt formeln
sannolikheten att en slumpvariabel tar ett värde från ett intervall är lika med arean under grafen för en funktion på detta intervall (den geometriska betydelsen av en bestämd integral). Den aktuella funktionen är icke-negativ och kontinuerlig. Funktionens graf har formen av en klocka och kallas en Gaussisk kurva eller normalkurva.
Figuren visar flera fördelningsdensitetskurvor för en stokastisk variabel specificerad enligt normallagen.
Alla kurvor har en maxpunkt, och när du rör dig bort från den till höger och vänster minskar kurvorna. Maximum uppnås vid och är lika med .
Kurvorna är symmetriska kring en vertikal linje som dras genom den högsta punkten. Arean av subgrafen för varje kurva är 1.
Skillnaden mellan individuella fördelningskurvor är bara att den totala arean av subgrafen, samma för alla kurvor, är fördelad olika mellan olika sektioner. Huvuddelen av subgrafområdet för varje kurva är koncentrerad i omedelbar närhet av det mest sannolika värdet, och detta värde är annorlunda för alla tre kurvorna. För olika värden och A olika normallagar och olika densitetsfördelningsfunktionsgrafer erhålls.
Teoretiska studier har visat att de flesta stokastiska variabler som påträffas i praktiken har en normalfördelningslag. Enligt denna lag fördelas gasmolekylernas hastighet, vikten av nyfödda, storleken på kläder och skor för landets befolkning och många andra slumpmässiga händelser av fysisk och biologisk natur. Detta mönster uppmärksammades först och teoretiskt underbyggdes av A. Moivre.
Funktionen sammanfaller nämligen med den funktion som redan diskuterades i Moivre–Laplaces lokala gränssats. Sannolikhetstätheten för en normalfördelning är lätt uttryckt genom:
För sådana parametervärden kallas normallagen huvud .
Fördelningsfunktionen för normaliserad densitet kallas Laplace funktion och är utsedd Φ(x). Vi har också redan stött på denna funktion.
Laplace-funktionen är inte beroende av specifika parametrar A och σ. För Laplace-funktionen, med hjälp av ungefärliga integrationsmetoder, har värdetabeller på intervallet med varierande noggrannhetsgrad sammanställts. Uppenbarligen är Laplace-funktionen udda, därför finns det inget behov av att sätta dess värden i tabellen för negativa .
För en stokastisk variabel fördelad enligt normallagen med parametrar A och , matematisk förväntan och spridning beräknas med hjälp av formlerna: , .Standardavvikelsen är lika med .
Sannolikheten att en normalfördelad storhet tar ett värde från intervallet är lika med
var är Laplace-funktionen införd i integralgränssatsen.
Ofta i problem krävs att man beräknar sannolikheten för att avvikelsen för en normalfördelad stokastisk variabel X från dess matematiska förväntan i absolut värde inte överstiger ett visst värde, dvs. beräkna sannolikhet. Med formeln (19.2) har vi:
Sammanfattningsvis presenterar vi en viktig följd av formel (19.3). Låt oss lägga in den här formeln. Sedan, d.v.s. sannolikheten att det absoluta värdet av avvikelsen X av dess matematiska förväntan kommer inte att överstiga , lika med 99,73%. I praktiken kan en sådan händelse anses tillförlitlig. Detta är kärnan i tre sigma-regeln.
Tre sigma regel. Om en slumpvariabel är normalfördelad, överstiger det absoluta värdet av dess avvikelse från den matematiska förväntan praktiskt taget inte tre gånger standardavvikelsen.
Artikeln visar i detalj vad normalfördelningslagen för en stokastisk variabel är och hur man använder den när man löser praktiska problem.
Normalfördelning i statistik
Lagens historia går 300 år tillbaka i tiden. Den första upptäckaren var Abraham de Moivre, som kom med uppskattningen redan 1733. Många år senare härledde Carl Friedrich Gauss (1809) och Pierre-Simon Laplace (1812) matematiska funktioner.
Laplace upptäckte också ett anmärkningsvärt mönster och formulerade Centrala gränsvärdessatsen (CPT), enligt vilken summan av ett stort antal små och oberoende kvantiteter har en normalfördelning.
Normallagen är inte en fast ekvation för en variabels beroende av en annan. Endast arten av detta beroende registreras. Den specifika distributionsformen specificeras av speciella parametrar. Till exempel, y = axe + bär ekvationen för en rät linje. Men var exakt den passerar och i vilken vinkel bestäms av parametrarna A Och b. Samma med normalfördelning. Det är tydligt att detta är en funktion som beskriver tendensen till en hög koncentration av värden runt mitten, men dess exakta form bestäms av speciella parametrar.
Den Gaussiska normalfördelningskurvan ser ut så här.
Normalfördelningsgrafen liknar en klocka, varför du kanske ser namnet klockkurva. Grafen har en "puckel" i mitten och en kraftig minskning av densiteten vid kanterna. Detta är kärnan i normalfördelningen. Sannolikheten att en slumpvariabel kommer att vara nära centrum är mycket högre än att den kommer att avvika mycket från centrum.

Figuren ovan visar två områden under den Gaussiska kurvan: blå och grön. Skäl, d.v.s. Intervallerna är lika för båda sektionerna. Men höjderna är märkbart olika. Det blå området är längre bort från centrum och har en betydligt lägre höjd än det gröna området, som ligger i mitten av utbredningen. Följaktligen skiljer sig också områdena, det vill säga sannolikheterna för att falla in i de angivna intervallen.
Formeln för normalfördelning (densitet) är följande.
![]()
Formeln består av två matematiska konstanter:
π – pi nummer 3,142;
e– naturlig logaritmbas 2,718;
två föränderliga parametrar som definierar formen på en specifik kurva:
m– matematisk förväntan (andra notationer kan användas i olika källor, t.ex. µ eller a);
σ 2– dispersion;
och själva variabeln x, för vilken sannolikhetstätheten beräknas.
Den specifika formen av normalfördelningen beror på 2 parametrar: ( m) Och ( σ 2). Kort angivet N(m, σ 2) eller N(m, σ). Parameter m(förväntning) bestämmer fördelningens centrum, vilket motsvarar grafens maximala höjd. Dispersion σ 2 kännetecknar variationens omfattning, det vill säga uppgifternas "smutsighet".
Den matematiska förväntansparametern flyttar fördelningens centrum åt höger eller vänster utan att påverka formen på själva densitetskurvan.

Men dispersion bestämmer kurvans skärpa. När data har en liten spridning, då är all dess massa koncentrerad till mitten. Om data har en stor spridning, är den "spridd" över ett brett spektrum.

Distributionsdensitet har ingen direkt praktisk tillämpning. För att beräkna sannolikheterna måste du integrera densitetsfunktionen.
Sannolikheten att en slumpvariabel är mindre än ett visst värde x, är bestämd normalfördelningsfunktion:
Med hjälp av de matematiska egenskaperna för varje kontinuerlig fördelning är det lätt att beräkna andra sannolikheter, eftersom
P(a ≤ X< b) = Ф(b) – Ф(a)
Standard normalfördelning
Normalfördelningen beror på parametrarna för medelvärdet och variansen, varför dess egenskaper är dåligt synliga. Det skulle vara trevligt att ha någon distributionsstandard som inte beror på omfattningen av data. Och det finns. Kallad standard normalfördelning. I själva verket är detta en vanlig normalfördelning, endast med parametrarna matematisk förväntan 0 och varians 1, kort skrivet N(0, 1).
Vilken normalfördelning som helst kan enkelt omvandlas till en standardfördelning genom normalisering:
Var z– en ny variabel som används istället x;
m- förväntat värde;
σ
- standardavvikelse.
För exempeldata tas uppskattningar:
Aritmetiskt medelvärde och varians för den nya variabeln zär nu också 0 respektive 1. Detta kan enkelt verifieras med hjälp av elementära algebraiska transformationer.
Namnet förekommer i litteraturen z-poäng. Detta är det – normaliserade data. Z-poäng kan direkt jämföras med teoretiska sannolikheter, eftersom dess skala överensstämmer med standarden.
Låt oss nu se hur densiteten för standardnormalfördelningen ser ut (för z-poäng). Låt mig påminna dig om att den Gaussiska funktionen har formen:
![]()
Låt oss ersätta istället (x-m)/a brev z, och istället σ – en, vi får densitetsfunktion för standardnormalfördelningen:
![]()
Densitetsdiagram:

Centrum, som förväntat, är vid punkt 0. Vid samma punkt når Gauss-funktionen sitt maximum, vilket motsvarar att den slumpmässiga variabeln accepterar sitt medelvärde (dvs. x-m=0). Densiteten vid denna punkt är 0,3989, vilket kan beräknas även i ditt huvud, eftersom e 0 =1 och allt som återstår är att beräkna förhållandet 1 till roten av 2 pi.
Således visar grafen tydligt att värden som har små avvikelser från genomsnittet förekommer oftare än andra, och de som är mycket långt från centrum förekommer mycket mer sällan. X-axelskalan mäts i standardavvikelser, vilket gör att du kan bli av med måttenheter och få en universell struktur med normalfördelning. Gauss-kurvan för normaliserade data visar perfekt andra egenskaper hos normalfördelningen. Till exempel att den är symmetrisk kring ordinataaxeln. De flesta av alla värden är koncentrerade inom ±1σ från det aritmetiska medelvärdet (vi uppskattar med ögat för närvarande). De flesta data ligger inom ±2σ. Nästan all data ligger inom ±3σ. Den sista fastigheten är allmänt känd som tre sigma regel för normalfördelning.
Den vanliga normalfördelningsfunktionen låter dig beräkna sannolikheter.
![]()
Det är tydligt att ingen räknar manuellt. Allt beräknas och placeras i speciella tabeller, som finns i slutet av någon statistiklärobok.
Normalfördelningstabell
Det finns två typer av normalfördelningstabeller:
- bord densitet;
- bord funktioner(integral av densitet).
Tabell densitet används sällan. Men låt oss se hur det ser ut. Låt oss säga att vi måste få tätheten för z = 1, dvs. densiteten av ett värde skilt från förväntan med 1 sigma. Nedan är en bit av bordet.

Beroende på organisationen av data letar vi efter det önskade värdet med namnet på kolumnen och raden. I vårt exempel tar vi linjen 1,0 och kolumn 0 , därför att det finns inga hundradelar. Värdet du letar efter är 0,2420 (0:an före 2420 utelämnas).
Gaussfunktionen är symmetrisk kring ordinatan. Det är därför φ(z)= φ(-z), dvs. densitet för 1 är identisk med densiteten för -1 , vilket är tydligt synligt i figuren.

För att undvika slöseri med papper skrivs tabeller endast ut för positiva värden.
I praktiken används värdena oftare funktioner standardnormalfördelning, det vill säga sannolikheten för olika z.
Sådana tabeller innehåller också endast positiva värden. Därför att förstå och hitta några du bör känna till de nödvändiga sannolikheterna egenskaper hos standardnormalfördelningen.
Fungera Ф(z) symmetrisk om dess värde 0,5 (och inte ordinataaxeln, som densitet). Därför är jämställdheten sann:
Detta faktum visas på bilden:

Funktionsvärden Ф(-z) Och Ф(z) dela upp grafen i 3 delar. Dessutom är de övre och nedre delarna lika (indikeras med bockar). För att komplettera sannolikheten Ф(z) till 1, lägg bara till det saknade värdet Ф(-z). Du får den jämställdhet som anges precis ovan.
Om du behöver hitta sannolikheten att falla i intervallet (0; z), det vill säga sannolikheten för avvikelse från noll i positiv riktning till ett visst antal standardavvikelser, räcker det att subtrahera 0,5 från värdet av standardnormalfördelningsfunktionen:

För tydlighetens skull kan du titta på ritningen.

På en Gauss-kurva ser samma situation ut som området från mitten till höger z.

Ganska ofta är en analytiker intresserad av sannolikheten för avvikelse i båda riktningarna från noll. Och eftersom funktionen är symmetrisk kring mitten måste den föregående formeln multipliceras med 2:

Bild nedan.

Under Gauss-kurvan är detta den centrala delen som begränsas av det valda värdet –z vänster och z till höger.

Dessa egenskaper bör beaktas, eftersom tabellerade värden motsvarar sällan intervallet av intresse.
För att göra uppgiften enklare publicerar läroböcker vanligtvis tabeller för funktioner i formen:

Om du behöver sannolikheten för avvikelse i båda riktningarna från noll, så multipliceras, som vi just har sett, tabellvärdet för denna funktion helt enkelt med 2.
Låt oss nu titta på specifika exempel. Nedan finns en tabell över standardnormalfördelningen. Låt oss hitta tabellvärdena för tre z: 1,64, 1,96 och 3.

Hur förstår man innebörden av dessa siffror? Låt oss börja med z=1,64, för vilket tabellvärdet är 0,4495 . Det enklaste sättet att förklara innebörden är på bilden.

Det vill säga sannolikheten att en standardiserad normalfördelad stokastisk variabel faller inom intervallet från 0 innan 1,64 , är jämställd 0,4495 . När du löser problem behöver du vanligtvis beräkna sannolikheten för avvikelse i båda riktningarna, så låt oss multiplicera värdet 0,4495 med 2 och vi får ungefär 0,9. Det ockuperade området under Gauss-kurvan visas nedan.

Således faller 90% av alla normalfördelade värden inom intervallet ±1,64σ från det aritmetiska medelvärdet. Det var inte av en slump jag valde innebörden z=1,64, därför att grannskapet runt det aritmetiska medelvärdet, som upptar 90 % av hela området, används ibland för att beräkna konfidensintervall. Om värdet som testas inte faller inom det angivna området, är det osannolikt att det inträffar (endast 10%).
För att testa hypoteser används dock oftare ett intervall som täcker 95 % av alla värden. Halva chansen 0,95 - Det här 0,4750 (se det andra markerade värdet i tabellen).

För denna sannolikhet z=1,96. De där. inom nästan ±2σ 95% av värdena är från genomsnittet. Endast 5 % faller utanför dessa gränser.

Ett annat intressant och ofta använt tabellvärde motsvarar z=3, det är lika enligt vår tabell 0,4986 . Multiplicera med 2 och få 0,997 . Så inombords ±3σ Nästan alla värden härleds från det aritmetiska medelvärdet.

Så här ser 3 sigma-regeln ut för en normalfördelning i ett diagram.
Med hjälp av statistiska tabeller kan du få vilken sannolikhet som helst. Denna metod är dock mycket långsam, obekväm och mycket föråldrad. Idag görs allt på datorn. Därefter går vi vidare till övningen av beräkningar i Excel.
Normalfördelning i Excel
Excel har flera funktioner för att beräkna sannolikheter eller inverser av en normalfördelning.

NORMAL DIST-funktion
Fungera NORM.ST.DIST. utformad för att beräkna densitet ϕ(z) eller sannolikheter Φ(z) enligt normaliserade data ( z).
=NORM.ST.FÖRD(z;integral)
z– Värdet på den standardiserade variabeln
väsentlig– om 0, så beräknas densitetenϕ(z) , om 1 är värdet på funktionen Ф(z), dvs. sannolikhet P(Z
Låt oss beräkna densiteten och funktionsvärdet för olika z: -3, -2, -1, 0, 1, 2, 3(vi kommer att ange dem i cell A2).
För att beräkna densiteten behöver du formeln =NORM.ST.FÖRD(A2;0). I diagrammet nedan är detta den röda pricken.
För att beräkna värdet på funktionen =NORM.ST.FÖRD(A2;1). Diagrammet visar det skuggade området under normalkurvan.

I verkligheten är det oftare nödvändigt att beräkna sannolikheten för att en stokastisk variabel inte kommer att överskrida vissa gränser från genomsnittet (i standardavvikelser motsvarande variabeln z), dvs. P(|Z|

Låt oss bestämma sannolikheten för att en slumpvariabel faller inom gränserna ±1z, ±2z och ±3z från noll. Behöver en formel 2Ф(z)-1, i Excel =2*NORM.ST.FÖRD(A2;1)-1.

Diagrammet visar tydligt de huvudsakliga grundläggande egenskaperna för normalfördelningen, inklusive tre-sigma-regeln. Fungera NORM.ST.DIST.är en automatisk tabell över normalfördelningsfunktionsvärden i Excel.
Det kan också finnas ett omvänt problem: enligt den tillgängliga sannolikheten P(Z
NORM.ST.REV-funktion
NORM.ST.REV beräknar inversen av standardnormalfördelningsfunktionen. Syntaxen består av en parameter:
=NORM.ST.REV(sannolikhet)
sannolikhetär en sannolikhet.
Den här formeln används lika ofta som den föregående, för med samma tabeller måste du inte bara leta efter sannolikheter utan också efter kvantiler.

Till exempel, vid beräkning av konfidensintervall anges en konfidenssannolikhet, enligt vilken det är nödvändigt att beräkna värdet z.

Med tanke på att konfidensintervallet består av en övre och nedre gräns och att normalfördelningen är symmetrisk kring noll, räcker det för att erhålla den övre gränsen (positiv avvikelse). Den nedre gränsen tas med negativt tecken. Låt oss beteckna konfidenssannolikheten som γ (gamma), då beräknas den övre gränsen för konfidensintervallet med hjälp av följande formel.
![]()
Låt oss beräkna värdena i Excel z(vilket motsvarar avvikelsen från genomsnittet i sigma) för flera sannolikheter, inklusive de som vilken statistiker som helst kan utantill: 90%, 95% och 99%. I cell B2 anger vi formeln: =NORM.ST.REV((1+A2)/2). Genom att ändra värdet på variabeln (sannolikhet i cell A2) får vi olika gränser för intervallen.

Konfidensintervallet på 95 % är 1,96, det vill säga nästan 2 standardavvikelser. Härifrån är det lätt, även mentalt, att uppskatta den möjliga spridningen av en normal slumpvariabel. I allmänhet motsvarar 90 %, 95 % och 99 % konfidensintervall konfidensintervall på ±1,64, ±1,96 och ±2,58σ.
I allmänhet låter funktionerna NORM.ST.DIST och NORM.ST.REV dig utföra alla beräkningar som är relaterade till normalfördelningen. Men för att göra saker enklare och mindre komplicerade har Excel flera andra funktioner. Du kan till exempel använda KONFIDENSNORM för att beräkna konfidensintervall för medelvärdet. För att kontrollera det aritmetiska medelvärdet finns formeln Z.TEST.
Låt oss titta på ytterligare ett par användbara formler med exempel.
NORMAL DIST-funktion
Fungera NORMAL DIST. skiljer sig från NORM.ST.DIST. bara för att den används för att bearbeta data av vilken skala som helst, och inte bara normaliserade sådana. Normalfördelningsparametrar anges i syntaxen.
=NORM.FÖRD(x;medelvärde;standardavvikelse;integral)
genomsnitt– matematisk förväntan som används som den första parametern i normalfördelningsmodellen
standard_av– standardavvikelse – den andra parametern i modellen
väsentlig– om 0 så beräknas densiteten, om 1 – då värdet på funktionen, dvs. P(X
Till exempel, densiteten för värdet 15, som extraherades från ett normalt prov med en förväntan på 10, en standardavvikelse på 3, beräknas enligt följande:

Om den sista parametern är satt till 1, så får vi sannolikheten att den normala slumpvariabeln blir mindre än 15 för de givna fördelningsparametrarna. Således kan sannolikheter beräknas direkt från originaldata.
NORM.REV-funktion
Detta är en kvantil av normalfördelningen, dvs. värdet av den inversa funktionen. Syntaxen är som följer.
=NORM.REV(sannolikhet;medelvärde;standardavvikelse)
sannolikhet- sannolikhet
genomsnitt– matematisk förväntan
standard_av- standardavvikelse
Syftet är detsamma som NORM.ST.REV, endast funktionen fungerar med data av valfri skala.
Ett exempel visas i videon i slutet av artikeln.
Normal distributionsmodellering
Vissa problem kräver generering av normala slumptal. Det finns ingen färdig funktion för detta. Excel har dock två funktioner som returnerar slumptal: FALL MELLAN Och RAND. Den första producerar slumpmässiga, enhetligt fördelade heltal inom specificerade gränser. Den andra funktionen genererar enhetligt fördelade slumptal mellan 0 och 1. För att göra ett artificiellt prov med en given fördelning behöver du funktionen RAND.
Låt oss säga att för att genomföra ett experiment är det nödvändigt att få ett urval från en normalfördelad population med en förväntan på 10 och en standardavvikelse på 3. För ett slumpmässigt värde kommer vi att skriva en formel i Excel.
NORM.INV(RAND();10;3)
Låt oss utöka det till det nödvändiga antalet celler och det normala provet är klart.
För att modellera standardiserade data bör du använda NORM.ST.REV.
Processen att konvertera enhetliga tal till normala tal kan visas i följande diagram. Från de enhetliga sannolikheterna som genereras av RAND-formeln dras horisontella linjer till grafen för normalfördelningsfunktionen. Sedan, från skärningspunkterna för sannolikheterna med grafen, sänks projektioner på den horisontella axeln.