Можливість нормально розподіленої випадкової величини. Нормальний закон розподілу ймовірностей безперервної випадкової величини. Зв'язок з іншими розподілами
Підставивши φ(x)=π /4 f(x)=1/(b-a)
D[π /4]=( /720) ).
№319 Ребро куба xвиміряно приблизно, причому a . Розглядаючи ребро куба як випадкову величину X, рівномірно розподілену в інтервалі (a, b), знайти математичне очікування і дисперсію обсягу куба.
1.Знайдемо математичне очікування площі кола – випадкової величини Y=φ(K)= - за формулою
M[φ(X)]= ![]()
Поставивши φ(x)= f(x)=1/(b-a)та виконавши інтегрування, отримаємо
M( )=
 .
.
2.Знайдемо дисперсію площі кола за формулою
D [φ(X)] = ![]() -
-
![]() .
.
Підставивши φ(x)= f(x)=1/(b-a)та виконавши інтегрування, отримаємо
D =
 .
.
№320 Випадкові величини X і Y незалежні і розподілені рівномірно: X-в інтервалі (a, b), Y-в інтервалі (c, d). Знайти математичне очікування твору XY.
Математичне очікування твору незалежних випадкових величин дорівнює добутку їх математичних очікувань, тобто.
M(XY)= 
№321 Випадкові величини X і Y незалежні і рівномірно розподілені: X- в інтервалі (a,b), Y – в інтервалі (c,d). Знайти дисперсію твору XY.
Скористаємося формулою
D(XY)=M[
Математичне очікування твору незалежних випадкових величин дорівнює твору їх математичних очікувань, тому
Знайдемо M за формулою
M[φ(X)]= ![]()
Підставляючи φ(x)= f(x)=1/(b-a)і виконуючи інтегрування, отримаємо
M (**)
Аналогічно знайдемо
M (***)
Підставивши M(X)=(a+b)/2, M(Y)=(c+d)/2,а також (***) і (**) в (*), остаточно отримаємо
D(XY)= -[
![]() .
.
№322 Математичне очікування нормально розподіленої випадкової величини X дорівнює a=3 та середнє квадратичне відхилення σ=2.Написати щільність ймовірності X.
Скористаємося формулою:
f(x)=  .
.
Підставляючи наявні значення отримаємо:
f(x)=  = f(x)=
= f(x)=  .
.
№323 Написати густину ймовірності нормально розподіленої випадкової величини X, знаючи, що M(X)=3, D(X)=16.
Скористаємося формулою:
f(x)= .
Для того, щоб знайти значення σ скористаємось властивістю, що середнє квадратичне відхилення випадкової величини Xдорівнює квадратному кореню з її дисперсії. Отже σ=4, M(X)=a=3. Підставляючи у формулу отримаємо
f(x)=  =
=
 .
.
№324 Нормально розподілена випадкова величина X задана щільністю
f(x)= ![]() .
Знайти математичне очікування та дисперсію X.
.
Знайти математичне очікування та дисперсію X.
Скористаємося формулою
f(x)= ,
де a-математичне очікування, σ -Середнє квадратичне відхилення X. З цієї формули випливає, що a=M(X)=1. Для знаходження дисперсії скористаємось властивістю, що середнє квадратичне відхилення випадкової величини Xдорівнює квадратному кореню з її дисперсії. Отже D(X)= =
Відповідь: математичне очікування дорівнює 1; дисперсія дорівнює 25.
Бондарчук Родіон
Дано функцію розподілу нормованого нормального закону ![]() . Знайти густину розподілу f(x).
. Знайти густину розподілу f(x).
Знаючи, що ![]() , Знаходимо f(x).
, Знаходимо f(x).

Відповідь: ![]()
Довести, що функція Лапласа ![]() . непарна:
. непарна: ![]() .
.

Зробимо заміну


Робимо зворотну заміну та отримуємо:
![]() =
= ![]() =
=


Будуть і завдання для самостійного вирішення, до яких можна переглянути відповіді.
Нормальний розподіл: теоретичні засади
Прикладами випадкових величин, розподілених за нормальним законом, є зростання людини, маса виловлюваної риби одного виду. Нормальність розподілу означає таке : існують значення росту людини, маси риби одного виду, які на інтуїтивному рівні сприймаються як "нормальні" (а по суті - усереднені), і вони досить великій вибірці зустрічаються набагато частіше, ніж відрізняються в більшу або меншу сторону.
Нормальний розподіл ймовірностей безперервної випадкової величини (іноді - розподіл Гауса) можна назвати дзвоноподібним через те, що симетрична відносно середнього функція щільності цього розподілу дуже схожа на розріз дзвона (червона крива на малюнку вище).
Імовірність зустріти у вибірці ті чи інші значення дорівнює площі фігури під кривою і у разі нормального розподілу ми бачимо, що під верхом "дзвона", якому відповідають значення, що прагнуть середнього, площа, а значить, ймовірність, більша, ніж під краями. Таким чином, отримуємо те саме, що вже сказано: ймовірність зустріти людину "нормального" зростання, зловити рибу "нормальної" маси вище, ніж для значень, що відрізняються у більшу чи меншу сторону. У багатьох випадках практики помилки виміру розподіляються за законом, близькому до нормальному.
Зупинимося ще раз малюнку на початку уроку, у якому представлена функція щільності нормального розподілу. Графік цієї функції отримано при розрахунку деякої вибірки даних у пакеті програмних засобів STATISTICA. На ній стовпці гістограми є інтервали значень вибірки, розподіл яких близько (або, як прийнято говорити в статистиці, незначно відрізняються від) до власне графіку функції щільності нормального розподілу, який є кривою червоного кольору. На графіці видно, що ця крива дійсно дзвоноподібна.
Нормальний розподіл багато в чому цінний завдяки тому, що знаючи лише математичне очікування безперервної випадкової величини та стандартне відхилення, можна обчислити будь-яку ймовірність, пов'язану з цією величиною.
Нормальний розподіл має ще й ту перевагу, що один із найпростіших у використанні статистичних критеріїв, що використовуються для перевірки статистичних гіпотез - критерій Стьюдента- може бути використаний тільки в тому випадку, коли ці вибірки підпорядковуються нормальному закону розподілу.
Функцію щільності нормального розподілу безперервної випадкової величиниможна знайти за формулою:
 ,
,
де x- значення величини, що змінюється, - середнє значення, - стандартне відхилення, e=2,71828... - основа натурального логарифму, =3,1416...
Властивості функції щільності нормального розподілу
Зміни середнього значення переміщують криву функції щільності нормального розподілу у напрямку осі Ox. Якщо зростає, крива переміщається праворуч, якщо зменшується, то вліво.
Якщо змінюється стандартне відхилення, змінюється висота вершини кривої. При збільшенні стандартного відхилення вершина кривої знаходиться вище, при зменшенні нижче.
Імовірність влучення значення нормально розподіленої випадкової величини у заданий інтервал
Вже у цьому параграфі почнемо вирішувати практичні завдання, зміст яких позначений у заголовку. Розберемо, які можливості для вирішення задач надає теорія. Відправне поняття для обчислення ймовірності попадання нормально розподіленої випадкової величини заданий інтервал - інтегральна функція нормального розподілу.
Інтегральна функція нормального розподілу:
 .
.
Однак проблематично отримати таблиці для кожної можливої комбінації середнього та стандартного відхилення. Тому одним із простих способів обчислення ймовірності попадання нормально розподіленої випадкової величини заданий інтервал є використання таблиць ймовірностей для стандартизованого нормального розподілу.
Стандартизованим або нормованим називається нормальний розподіл, середнє значення якого , а стандартне відхилення .
Функція густини стандартизованого нормального розподілу:
![]() .
.
Інтегральна функція стандартизованого нормального розподілу:
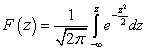 .
.
На малюнку нижче представлено інтегральну функцію стандартизованого нормального розподілу, графік якої отримано при розрахунку певної вибірки даних у пакеті програмних засобів STATISTICA. Власне графік є кривою червоного кольору, а значення вибірки наближаються до нього.

Для збільшення малюнка можна натиснути по ньому лівою кнопкою миші.
Стандартизація випадкової величини означає перехід від початкових одиниць, що використовуються в завданні, до стандартизованих одиниць. Стандартизація виконується за формулою
На практиці всі можливі значення випадкової величини часто не відомі, тому значення середнього та стандартного відхилення точно визначити не можна. Їх замінюють середнім арифметичним спостереженням та стандартним відхиленням s. Величина zвиражає відхилення значень випадкової величини від середнього арифметичного при вимірі стандартних відхилень.
Відкритий інтервал
Таблиця ймовірностей для стандартизованого нормального розподілу, яка є практично в будь-якій книзі за статистикою, містить ймовірність того, що випадкова величина, що має стандартний нормальний розподіл Zнабуде значення менше деякого числа z. Тобто потрапить у відкритий інтервал від мінус нескінченності до z. Наприклад, ймовірність того, що величина Zменше 1,5, дорівнює 0,93319.
приклад 1.Підприємство виробляє деталі, термін служби яких нормально розподілений із середнім значенням 1000 та стандартним відхиленням 200 годин.
Для випадково відібраної деталі визначити ймовірність того, що її термін служби буде не менше 900 годин.
Рішення. Введемо перше позначення:
Шукана ймовірність.
Значення випадкової величини перебувають у відкритому інтервалі. Але ми вміємо обчислювати ймовірність того, що випадкова величина набуде значення, менше заданого, а за умовою завдання потрібно знайти рівне або більше заданого. Це інша частина простору під кривою густини нормального розподілу (дзвони). Тому, щоб знайти ймовірність, потрібно з одиниці відняти згадану ймовірність того, що випадкова величина прийме значення, менше заданого 900:
Тепер випадкову величину слід стандартизувати.
Продовжуємо вводити позначення:
z = (X ≤ 900) ;
x= 900 – задане значення випадкової величини;
μ = 1000 – середнє значення;
σ = 200 – стандартне відхилення.
За цими даними умови завдання отримуємо:
![]() .
.
За таблицями стандартизованої випадкової величини (межі інтервалу) z= −0,5 відповідає ймовірність 0,30854. Віднімемо її з одиниці і отримаємо те, що потрібно за умови завдання:
Отже, ймовірність того, що термін служби деталі буде не менше ніж 900 годин, становить 69%.
Цю можливість можна отримати, використовуючи функцію MS Excel НОРМ.РАСП (значення інтегральної величини - 1):
P(X≥900) = 1 - P(X≤900) = 1 - НОРМ.РАСП(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
Про розрахунки в MS Excel – в одному з наступних параграфів цього уроку.
приклад 2.У деякому місті середньорічний дохід сім'ї є нормально розподіленою випадковою величиною із середнім значенням 300000 та стандартним відхиленням 50000. Відомо, що доходи 40 % сімей менші за величину A. Знайти величину A.
Рішення. У цьому завданні 40 % - ні що інше, як ймовірність того, що випадкова величина набуде значення з відкритого інтервалу, меншого за певне значення, позначеного буквою A.
Щоб знайти величину A, спочатку складемо інтегральну функцію:
![]()
За умовою завдання
μ = 300000 – середнє значення;
σ = 50000 – стандартне відхилення;
x = A- Величина, яку потрібно знайти.
Складаємо рівність
![]() .
.
За статистичними таблицями знаходимо, що ймовірність 0,40 відповідає значенню межі інтервалу z = −0,25 .
Тому складаємо рівність
![]()
і знаходимо його рішення:
A = 287300 .
Відповідь: доходи 40% сімей менше 287300.
Закритий інтервал
У багатьох завданнях потрібно знайти ймовірність того, що нормально розподілена випадкова величина набуде значення в інтервалі від z 1 до z 2 . Тобто потрапить до закритого інтервалу. Для вирішення таких завдань необхідно знайти в таблиці ймовірності, що відповідають межі інтервалу, а потім знайти різницю цих ймовірностей. При цьому потрібно віднімати менше значення з більшого. Приклади на вирішення цих поширених завдань - наступні, причому вирішити їх пропонується самостійно, а потім можна переглянути правильні рішення та відповіді.
приклад 3.Прибуток підприємства за період - випадкова величина, підпорядкована нормальному закону розподілу із середнім значенням 0,5 млн. у.о. та стандартним відхиленням 0,354. Визначити з точністю до двох знаків після коми ймовірність того, що прибуток підприємства становитиме від 0,4 до 0,6 у.о.
приклад 4.Довжина деталі, що виготовляється, являє собою випадкову величину, розподілену за нормальним законом з параметрами μ =10 і σ = 0,071. Знайти з точністю до двох знаків після коми можливість шлюбу, якщо допустимі розміри деталі повинні бути 10±0,05 .
Підказка: в цьому завданні, крім знаходження ймовірності потрапляння випадкової величини в закритий інтервал (ймовірність отримання небракованої деталі), потрібно виконати ще одну дію.

дозволяє визначити ймовірність того, що стандартизоване значення Zне менше -zі не більше +z, де z- Довільно обране значення стандартизованої випадкової величини.
Наближений метод перевірки нормальності розподілу
Наближений метод перевірки нормальності розподілу значень вибірки ґрунтується на наступному властивості нормального розподілу: коефіцієнт асиметрії β 1 та коефіцієнт ексцесу β 2 рівні нулю.
Коефіцієнт асиметрії β 1 чисельно характеризує симетрію емпіричного розподілу щодо середнього. Якщо коефіцієнт асиметрії дорівнює нулю, то середнє арифметричне значення, медіана та мода рівні: і крива щільності розподілу симетрична щодо середнього. Якщо коефіцієнт асиметрії менший за нуль (β 1 < 0 ), то середнє арифметичне менше медіани, а медіана, у свою чергу, менше моди () і крива зсунута вправо (порівняно з нормальним розподілом). Якщо коефіцієнт асиметрії більший за нуль (β 1 > 0 ), то середнє арифметичне більше медіани, а медіана, у свою чергу, більше моди () і крива зрушена вліво (порівняно з нормальним розподілом).
Коефіцієнт ексцесу β 2 характеризує концентрацію емпіричного розподілу навколо арифметичного середнього у напрямку осі Ойі ступінь гостроверхості кривої щільності розподілу. Якщо коефіцієнт ексцесу більший за нуль, то крива більш витягнута (порівняно з нормальним розподілом)вздовж осі Ой(графік більш гостроверхий). Якщо коефіцієнт ексцесу менше нуля, то крива сплющена (порівняно з нормальним розподілом)вздовж осі Ой(графік більш туповершинний).
Коефіцієнт асиметрії можна визначити за допомогою функції MS Excel СКОС. Якщо ви перевіряєте один масив даних, потрібно ввести діапазон даних в одне вікно "Число".

Коефіцієнт ексцесу можна визначити за допомогою функції MS Excel ЕКСЦЕС. При перевірці одного масиву даних достатньо ввести діапазон даних в одне вікно "Число".

Отже, як ми вже знаємо, при нормальному розподілі коефіцієнти асиметрії та ексцесу дорівнюють нулю. Але що якщо ми отримали коефіцієнти асиметрії, рівні -0,14, 0,22, 0,43, а коефіцієнти ексцесу, рівні 0,17, -0,31, 0,55? Питання цілком справедливе, оскільки практично ми маємо справу лише з наближеними, вибірковими значеннями асиметрії та ексцесу, які схильні до деякого неминучого, неконтрольованого розкиду. Тому не можна вимагати суворої рівності цих коефіцієнтів нулю, вони повинні бути досить близькими до нуля. Але що означає – достатньо?
Потрібно порівняти отримані емпіричні значення з допустимими значеннями. Для цього потрібно перевірити такі нерівності (порівняти значення коефіцієнтів за модулем з критичними значеннями - межами області перевірки гіпотези).
Для коефіцієнта асиметрії β 1 .
Нормальний закон розподілу найчастіше зустрічається практично. Головна особливість, що виділяє його серед інших законів, полягає в тому, що він є граничним законом, до якого наближаються інші закони розподілу за типових умов, що дуже часто зустрічаються.
Визначення. Безперервна випадкова величина Х має нормальний законрозподілу(закон Гауса )з параметрами а і σ 2 якщо її щільність ймовірності f(x) має вигляд:
| . | (6.19) |
Криву нормального закону розподілу називають нормальноюабо гаусової кривої. На рис. 6.5 а), б) показано нормальну криву з параметрами аі σ 2та графік функції розподілу.
 Звернемо увагу на те, що нормальна крива симетрична щодо прямої х = а, має максимум у точці х = а, рівний , і дві точки перегину х = а σ
з ординатами.
Звернемо увагу на те, що нормальна крива симетрична щодо прямої х = а, має максимум у точці х = а, рівний , і дві точки перегину х = а σ
з ординатами.
Можна помітити, що у вираженні густини нормального закону параметри розподілу позначені буквами аі σ 2, якими ми означали математичне очікування та дисперсію. Такий збіг не випадковий. Розглянемо теорему, яка встановлює теоретико-імовірнісний зміст параметрів нормального закону.
Теорема. Математичне очікування випадкової величини Х, розподіленої за нормальним законом, дорівнює параметру a цього розподілу, тобто.
| М(Х) = а, | (6.20) |
а її дисперсія – параметр σ 2, тобто.
| D(X) = σ 2. | (6.21) |
З'ясуємо, як змінюватиметься нормальна крива при зміні параметрів аі σ .
Якщо σ = const і змінюється параметр a (а 1 < а 2 < а 3), тобто. центр симетрії розподілу, то нормальна крива зміщуватиметься вздовж осі абсцис, не змінюючи форми (рис. 6.6).

Мал. 6.6

Мал. 6.7
Якщо а= const і змінюється параметр σ , то змінюється ордината максимуму кривої f max(a) = . При збільшенні σ ордината максимуму зменшується, але так як площа під будь-якою кривою розподілу повинна залишатися рівною одиниці, то крива стає більш плоскою, розтягуючись уздовж осі абсцис. При зменшенні σ , Навпаки, нормальна крива витягується вгору, одночасно стискаючись з боків (рис. 6.7).
Таким чином, параметр aхарактеризує становище, а параметр σ - Форму нормальної кривої.
Нормальний закон розподілу випадкової величини з параметрами a= 0 і σ = 1 називається стандартнимабо нормованим, а відповідна нормальна крива – стандартноюабо нормованою.
Складність безпосереднього знаходження функції розподілу випадкової величини, розподіленої за нормальним законом, пов'язана з тим, що інтеграл від функції нормального розподілу не виражається через елементарні функції. Однак його можна обчислити через спеціальну функцію, що виражає певний інтеграл від виразу або . Таку функцію називають функцією Лапласадля неї складені таблиці. Існує багато різновидів такої функції, наприклад:
![]() ,
, ![]() .
.
Ми будемо використовувати функцію
Розглянемо властивості випадкової величини, розподіленої за нормальним законом.
1. Імовірність влучення випадкової величини Х, розподіленої за нормальним законом, в інтервал [α , β ] дорівнює
Обчислимо за цією формулою ймовірності при різних значеннях δ (використовуючи таблицю значень функції Лапласа):
при δ = σ = 2Ф(1) = 0,6827;
при δ = 2σ = 2Ф(2) = 0,9545;
при δ = 3σ = 2Ф (3) = 0,9973.
Звідси випливає так зване « правило трьох сигм»:
Якщо випадкова величина Х має нормальний закон розподілу з параметрами a і σ то практично достовірно, що її значення укладені в інтервалі(a – 3σ ; a + 3σ ).
Приклад 6.3.Вважаючи, що зростання чоловіків певної вікової групи є нормально розподіленою випадковою величиною Хз параметрами а= 173 та σ 2 = 36, знайти:
1. Вираз щільності ймовірності та функції розподілу випадкової величини Х;
2. Частку костюмів 4-го зростання (176 – 183 див) і частку костюмів 3-го зростання (170 – 176 див), які необхідно передбачити у загальному обсязі виробництва для цієї вікової групи;
3. Сформулювати «правило трьох сигм» для випадкової величини Х.
1. Знаходимо щільність імовірності
![]()
та функцію розподілу випадкової величини Х
![]() = .
= .
2. Частку костюмів 4-го зросту (176 – 182 см) знаходимо як ймовірність
Р(176 ≤ Х ≤ 182) = ![]() = Ф (1,5) - Ф (0,5).
= Ф (1,5) - Ф (0,5).
За таблицею значень функції Лапласа ( Додаток 2) знаходимо:
Ф(1,5) = 0,4332, Ф(0,5) = 0,1915.
Остаточно отримуємо
Р(176 ≤ Х ≤ 182) = 0,4332 – 0,1915 = 0,2417.
Частку костюмів 3-го зросту (170 - 176 см) можна знайти аналогічно. Однак простіше це зробити, якщо врахувати, що цей інтервал симетричний щодо математичного очікування а= 173, тобто. нерівність 170 ≤ Х≤ 176 рівносильно нерівності │ Х– 173│≤ 3. Тоді
Р(170 ≤Х ≤176) = Р(│Х- 173│≤ 3) = 2Ф (3/6) = 2Ф (0,5) = 2 · 0,1915 = 0,3830.
3. Сформулюємо «правило трьох сигм» для випадкової величини Х:
Практично достовірно, що зростання чоловіків цієї вікової групи укладено у межах від а – 3σ = 173 - 3 · 6 = 155 до а + 3σ = 173 + 3 · 6 = 191, тобто. 155 ≤ Х ≤ 191. ◄
7. Граничні ТЕОРЕМИ ТЕОРІЇ ймовірності
Як мовилося раніше щодо випадкових величин, неможливо заздалегідь передбачити, яке значення прийме випадкова величина внаслідок одиничного випробування – це від багатьох причин, врахувати які неможливо.
Однак при багаторазовому повторенні випробувань характер поведінки суми випадкових величин майже втрачає випадковий і стає закономірним. Наявність закономірностей пов'язано саме з масовістю явищ, що породжують у своїй сукупності випадкову величину, підпорядковану цілком певному закону. Суть стійкості масових явищ зводиться до такого: конкретні особливості кожного окремого випадкового явища майже позначаються середньому результаті маси таких явищ; випадкові відхилення від середнього, неминучі у кожному окремому явище, у масі взаємно погашаються, нівелюються, вирівнюються.
Саме ця стійкість середніх і являє собою фізичний зміст «закону великих чисел», що розуміється в широкому значенні слова: за дуже великої кількості випадкових явищ їхній результат практично перестає бути випадковим і може бути передбачений з великим ступенем визначеності.
У вузькому значенні слова під «законом великих чисел» теоретично ймовірностей розуміється ряд математичних теорем, у кожному з яких тих чи інших умов встановлюється факт наближення середніх показників величезної кількості дослідів до певним постійним.
Закон великих чисел відіграє у практичних застосуваннях теорії ймовірностей. Властивість випадкових величин за певних умов поводитися практично не випадково дозволяє впевнено оперувати цими величинами, передбачати результати масових випадкових явищ майже з повною визначеністю.
Можливості таких передбачень у сфері масових випадкових явищ ще більше розширюються наявністю іншої групи граничних теорем, що стосуються не граничних значень випадкових величин, а граничних законів розподілу. Йдеться групі теорем, відомих під назвою «центральної граничної теореми». Різні форми центральної граничної теореми різняться між собою тими умовами, котрим встановлюється це граничне властивість суми випадкових величин.
Різні форми закону великих чисел з різними формами центральної граничної теореми утворюють сукупність про граничних теоремтеорії ймовірностей. Граничні теореми дають можливість як здійснювати наукові прогнози у сфері випадкових явищ, а й оцінювати точність цих прогнозів.
Випадкова величина називається розподіленого за нормальним (Гаусівським) законом з параметрами а та () якщо щільність розподілу ймовірностей має вигляд
Величина, розподілена за нормальним законом, завжди має безліч можливих значень, тому її зручно зображати графічно, за допомогою графіка щільності розподілу. Згідно з формулою
ймовірність того, що випадкова величина набуде значення інтервалу дорівнює площі під графіком функції на цьому інтервалі (геометричний зміст певного інтеграла). Ця функція невід'ємна і безперервна. Графік функції має вигляд дзвона і називається кривою Гауса або нормальною кривою.
На малюнку зображено кілька кривих густини розподілу випадкової величини, заданої за нормальним законом.
Всі криві мають одну точку максимуму, при віддаленні від якої праворуч і ліворуч криві зменшуються. Максимум досягається при і дорівнює.
Криві симетричні щодо вертикальної прямої, проведеної через найвищу точку. Площа підграфіку кожної кривої дорівнює 1.
Відмінність окремих кривих розподілу полягає лише в тому, що сумарна площа підграфіка, та сама для всіх кривих, по-різному розподілена між різними ділянками. Основна частина площі підграфіка будь-якої кривої зосереджена в безпосередній близькості до найімовірнішого значення, а це значення у всіх трьох кривих різне. При різних значеннях та авиходять різні нормальні закони та різні графіки щільності функції розподілу.
Теоретичні дослідження показали, що більшість випадкових величин, що зустрічаються на практиці, має нормальний закон розподілу. За цим законом розподіляється швидкість газових молекул, вага новонароджених, розмір одягу та взуття населення країни та багато інших випадкових подій фізичної та біологічної природи. Вперше цю закономірність помітив та теоретично обґрунтував А. Муавр.
При функція збігається з функцією , про яку вже йшлося в локальній граничній теоремі Муавра-Лапласа. Щільність ймовірності нормального розподілу легко виражається через:
За таких значень параметрів нормальний закон називається основним .
Функція розподілу для нормованої густини називається функцією Лапласа і позначається Φ(х). Ми також зустрічалися з цією функцією.
Функція Лапласа не залежить від конкретних параметрів ата σ. Для функції Лапласа за допомогою методів наближеного інтегрування складено таблиці значень на проміжку з різним ступенем точності. Очевидно, що функція Лапласа є непарною, отже, немає необхідності поміщати таблицю її значення при негативних .
Для випадкової величини, розподіленої за нормальним законом із параметрами аі , математичне очікування і дисперсія обчислюються за формулами: . Середнє квадратичне відхилення дорівнює .
Імовірність того, що нормально розподілена величина набуде значення з інтервалу, дорівнює
де є функція Лапласа, запроваджена в інтегральній граничній теоремі.
Часто у завданнях потрібно обчислити ймовірність того, що відхилення нормально розподіленої випадкової величини Xвід свого математичного очікування по абсолютній величині вбирається у деякого значення , тобто . обчислити ймовірність. Застосовуючи формулу (19.2), маємо:
На закінчення наведемо одне важливе слідство з формули (19.3). Покладемо у цій формулі. Тоді, тобто. ймовірність того, що абсолютна величина відхилення Xвід свого математичного очікування не перевищить, дорівнює 99,73%. Майже таку подію можна вважати достовірною. У цьому полягає сутність правила трьох сигм.
Правило трьох сигм. Якщо випадкова величина розподілена нормально, то абсолютна величина її відхилення від математичного очікування мало перевищує потрійного середнього квадратичного відхилення.
У статті докладно показано, що таке нормальний закон розподілу випадкової величини і як ним користуватися під час вирішення практично завдань.
Нормальний розподіл у статистиці
Історія закону налічує 300 років. Першим відкривачем став Абрахам де Муавр, який вигадав апроксимацію ще 1733 року. Через багато років Карл Фрідріх Гаусс (1809) і П'єр-Симон Лаплас (1812) вивели математичні функції.
Лаплас також виявив чудову закономірність та сформулював центральну граничну теорему (ЦПТ), згідно з якою сума великої кількості малих та незалежних величин має нормальний розподіл.
Нормальний закон не є фіксованим рівнянням залежності однієї змінної від іншої. Фіксується лише характер цієї залежності. Конкретна форма розподілу визначається спеціальними параметрами. Наприклад, у = аx + b- Це рівняння прямої. Однак де саме вона проходить і під яким нахилом визначається параметрами аі b. Також із нормальним розподілом. Зрозуміло, що це функція, яка описує тенденцію високої концентрації значень біля центру, та її точна форма задається спеціальними параметрами.
Крива нормального розподілу Гауса має такий вигляд.
Графік нормального розподілу нагадує дзвін, тож можна зустріти назву дзвоноподібна крива. Графік має «горб» у середині і різке зниження щільності по краях. У цьому полягає суть нормального розподілу. Імовірність того, що випадкова величина виявиться біля центру набагато вищою, ніж те, що вона сильно відхилиться від середини.

На малюнку вище зображені дві ділянки під кривою Гауса: синій та зелений. Підстави, тобто. інтервали, в обох ділянок рівні. Але помітно вирізняються висоти. Синя ділянка віддалена від центру, і має істотно меншу висоту, ніж зелена, яка знаходиться в самому центрі розподілу. Отже, відрізняються і площі, тобто ймовірності попадання в зазначені інтервали.
Формула нормального розподілу (щільності) така.
![]()
Формула складається з двох математичних констант:
π - Число пі 3,142;
е– основа натурального логарифму 2,718;
двох змінних параметрів, що задають форму конкретної кривої:
m– математичне очікування (у різних джерелах можуть використовуватись інші позначення, наприклад, µ або a);
σ 2– дисперсія;
ну і сама змінна x, на яку обчислюється щільність ймовірності.
Конкретна форма нормального розподілу залежить від 2-х параметрів: ( m) та ( σ 2). Коротко позначається N(m, σ 2)або N(m, σ). Параметр m(маточування) визначає центр розподілу, якому відповідає максимальна висота графіка. Дисперсія σ 2характеризує розмах варіації, тобто «розмазаність» даних.
Параметр математичного очікування зміщує центр розподілу вправо чи вліво, не впливаючи на форму кривої щільності.

А ось дисперсія визначає гострість кривої. Коли дані мають малий розкид, то вся їхня маса концентрується біля центру. Якщо ж у даних великий розкид, то вони розмазуються по широкому діапазону.

Щільність розподілу немає прямого практичного застосування. Для розрахунку можливостей потрібно проінтегрувати функцію щільності.
Імовірність того, що випадкова величина виявиться меншою за деяке значення x, визначається функцією нормального розподілу:
Використовуючи математичні властивості будь-якого безперервного розподілу, нескладно розрахувати будь-які інші ймовірності, оскільки
P(a ≤ X< b) = Ф(b) – Ф(a)
Стандартний нормальний розподіл
Нормальний розподіл залежить від параметрів середньої та дисперсії, через що погано видно його властивості. Добре мати певний зразок розподілу, який залежить від масштабу даних. І вона існує. Називається стандартним нормальним розподілом. Насправді це нормальний нормальний розподіл, тільки з параметрами математичного очікування 0, а дисперсією – 1, коротко записується N(0, 1).
Будь-який нормальний розподіл легко перетворюється на стандартне шляхом нормування:
де z– нова змінна, яка використовується замість x;
m- математичне очікування;
σ
- стандартне відхилення.
Для вибіркових даних беруться оцінки:
Середнє арифметичне та дисперсія нової змінної zтепер також дорівнюють 0 і 1 відповідно. У цьому вся легко переконатися з допомогою елементарних алгебраїчних перетворень.
У літературі зустрічається назва z-оцінка. Це воно саме – нормовані дані. Z-оцінкуможна безпосередньо порівнювати з теоретичними можливостями, т.к. її масштаб збігається із зразком.
Подивимося тепер, як виглядає щільність стандартного нормального розподілу (для z-оцінок). Нагадаю, що функція Гауса має вигляд:
![]()
Підставимо замість (x-m)/σбукву z, а замість σ – одиницю, отримаємо функцію щільності стандартного нормального розподілу:
![]()
Графік густини:

Центр, як і очікувалося, знаходиться в точці 0. У цій точці функція Гауса досягає свого максимуму, що відповідає прийняттю випадковою величиною свого середнього значення (тобто. x-m=0). Щільність у цій точці дорівнює 0,3989, що можна порахувати навіть у розумі, т.к. e 0 =1 і залишається розрахувати лише співвідношення 1 на корінь із 2 пі.
Таким чином, за графіком добре видно, що значення, що мають маленькі відхилення від середньої, випадають частіше за інші, а ті, які сильно віддалені від центру, зустрічаються значно рідше. Шкала осі абсцис вимірюється у стандартних відхиленнях, що дозволяє відв'язатися від одиниць вимірювання та отримати універсальну структуру нормального розподілу. Крива Гауса для нормованих даних чудово демонструє інші властивості нормального розподілу. Наприклад, що воно є симетричним щодо осі ординат. У межах ±1σ від середньої арифметичної сконцентрована більшість всіх значень (прикидаємо поки на вічко). У межах ±2σ перебуває більшість даних. У межах ±3σ перебувають майже всі дані. Остання властивість широко відома під назвою правило трьох сигмдля нормального розподілу.
Функція нормального стандартного розподілу дозволяє розраховувати ймовірності.
![]()
Зрозуміло, вручну ніхто не вважає. Все підраховано та розміщено у спеціальних таблицях, які є наприкінці будь-якого підручника зі статистики.
Таблиця нормального розподілу
Таблиці нормального розподілу зустрічаються двох типів:
- Таблиця щільності;
- Таблиця функції(Інтеграла від щільності).
Таблиця щільностівикористовується рідко. Тим не менш, побачимо, як вона виглядає. Допустимо, потрібно отримати щільність для z = 1, тобто. щільність значення, віддаленого від матожидания на 1 сигму. Нижче показано шматок таблиці.

Залежно від організації даних шукаємо потрібне значення за назвою стовпця та рядка. У нашому прикладі беремо рядок 1,0 і стовпець 0 , т.к. сотих часток немає. Шукане значення дорівнює 0,2420 (0 до 2420 опущений).
Функція Гауса симетрична щодо осі ординат. Тому φ(z)= φ(-z), тобто. щільність для 1 тотожна щільності для -1 що чітко видно на малюнку.

Щоб не марнувати папір, таблиці друкують тільки для позитивних значень.
На практиці частіше використовують значення функціїстандартного нормального розподілу, тобто ймовірності для різних z.
У таких таблицях містяться лише позитивні значення. Тому для розуміння та знаходження будь-якихпотрібних ймовірностей слід знати властивості стандартного нормального розподілу.
Функція Ф(z)симетрична щодо свого значення 0,5 (а не осі ординат, як густина). Звідси справедлива рівність:
Цей факт показаний на зображенні:

Значення функції Ф(-z)і Ф(z)ділять графік на 3 частини. Причому верхня та нижня частини рівні (позначені галочками). Для того, щоб доповнити ймовірність Ф(z)до 1, достатньо додати недостатню величину Ф(-z). Вийде рівність, вказана трохи вище.
Якщо необхідно знайти можливість потрапляння в інтервал (0; z)тобто можливість відхилення від нуля в позитивну сторону до деякої кількості стандартних відхилень, достатньо від значення функції стандартного нормального розподілу відібрати 0,5:

Для наочності можна подивитись малюнок.

На кривій Гауса, ця ж ситуація виглядає як площа від центру вправо до z.

Досить часто аналітика цікавить можливість відхилення в обидві сторони від нуля. Оскільки функція симетрична щодо центру, попередню формулу потрібно помножити на 2:

Малюнок нижче.

Під кривою Гауса це центральна частина, обмежена вибраним значенням -zзліва та zправоруч.

Зазначені характеристики слід взяти до уваги, т.к. Табличні значення рідко відповідають цікавому інтервалу.
Для полегшення завдання у підручниках зазвичай публікують таблиці для функції виду:

Якщо потрібна ймовірність відхилення в обидві сторони від нуля, то, як ми щойно переконалися, табличне значення цієї функції просто множиться на 2.
Тепер подивимося на конкретні приклади. Нижче показано таблицю стандартного нормального розподілу. Знайдемо табличні значення для трьох z: 1,64, 1,96 та 3.

Як зрозуміти зміст цих чисел? Почнемо з z=1,64, для якого табличне значення становить 0,4495 . Найпростіше пояснити сенс малюнку.

Тобто ймовірність того, що стандартизована нормально розподілена випадкова величина потрапить в інтервал від 0 до 1,64 , дорівнює 0,4495 . При вирішенні завдань зазвичай потрібно розрахувати ймовірність відхилення в обидві сторони, тому помножимо величину 0,4495 на 2 та отримаємо приблизно 0,9. Займана площа під кривою Гауса показана нижче.

Таким чином, 90% усіх нормально розподілених значень потрапляє до інтервалу ±1,64σвід середньої арифметичної. Я не випадково вибрав значення z=1,64, т.к. околиця навколо середньої арифметичної, що займає 90% всієї площі, іноді використовується для розрахунку довірчих інтервалів. Якщо перевірене значення не потрапляє в зазначену область, його наступ малоймовірно (всього 10%).
Проте для перевірки гіпотез частіше використовується інтервал, що накриває 95% усіх значень. Половина ймовірності від 0,95 – це 0,4750 (Див. друге виділене в таблиці значення).

Для цієї ймовірності z = 1,96.Тобто. в межах майже ±2σвід середньої є 95% значень. Лише 5% випадають за ці межі.

Ще одне цікаве та часто використовується табличне значення відповідає z=3, воно одно за нашою таблицею 0,4986 . Помножимо на 2 і отримаємо 0,997 . Отже, у межах ±3σвід середньої арифметичної укладено майже всі значення.

Так виглядає правило 3 сигми для нормального розподілу на діаграмі.
За допомогою статистичних таблиць можна отримати будь-яку можливість. Однак цей метод дуже повільний, незручний та сильно застарів. Сьогодні все робиться на комп'ютері. Далі переходимо до практики розрахунків у Excel.
Нормальний розподіл у Excel
У Excel є кілька функцій для підрахунку ймовірностей чи зворотних значень нормального розподілу.

Функція НОРМ.СТ.РАСП
Функція НОРМ.СТ.РАСПпризначена для розрахунку щільності ϕ(z)чи ймовірності Φ(z)за нормованими даними ( z).
=НОРМ.СТ.РАСП(z;інтегральна)
z– значення стандартизованої змінної
інтегральна- якщо 0, то розраховується щільністьϕ(z) , якщо 1 – значення функції Ф(z), тобто. ймовірність P(Z
Розрахуємо щільність та значення функції для різних z: -3, -2, -1, 0, 1, 2, 3(їх вкажемо в осередку А2).
Для розрахунку щільності знадобиться формула =НОРМ.СТ.РАСП(A2;0). На діаграмі нижче – червона точка.
Для розрахунку значення функції =НОРМ.СТ.РАСП(A2;1). На діаграмі зафарбована площа під нормальною кривою.

Насправді частіше доводиться розраховувати ймовірність того, що випадкова величина не вийде за деякі межі від середньої (у середньоквадратичних відхиленнях, що відповідають змінній z), тобто. P(|Z|

Визначимо, чому дорівнює ймовірність попадання випадкової величини у межі ±1z, ±2z та ±3zвід нуля. Потрібна формула 2Ф(z)-1, Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На діаграмі добре видно основні основні властивості нормального розподілу, включаючи правило трьох сигм. Функція НОРМ.СТ.РАСП– це автоматична таблиця значень функції нормального розподілу Excel.
Може стояти і зворотне завдання: за ймовірністю P(Z
Функція НОРМ.СТ.ОБР
НОРМ.СТ.ОБРрозраховує зворотне значення функції стандартного нормального розподілу. Синтаксис складається з одного параметра:
=НОРМ.СТ.ОБР(імовірність)
ймовірність- Це ймовірність.
Дана формула використовується так само часто, як і попередня, адже за тими ж таблицями доводиться шукати не тільки ймовірності, а й квантили.

Наприклад, при розрахунку довірчих інтервалів визначається довірча ймовірність, за якою потрібно розрахувати величину z.

Враховуючи те, що довірчий інтервал складається з верхньої та нижньої межі та те, що нормальний розподіл симетрично щодо нуля, достатньо отримати верхню межу (позитивне відхилення). Нижня межа береться із негативним знаком. Позначимо довірчу ймовірність як γ (гамма), тоді верхня межа довірчого інтервалу розраховується за такою формулою.
![]()
Розрахуємо в Excel значення z(що відповідає відхилення від середньої в сигмах) для кількох ймовірностей, включаючи ті, які знає напам'ять будь-який статистик: 90%, 95% і 99%. У осередку B2 зазначимо формулу: =НОРМ.СТ.ОБР((1+A2)/2). Змінюючи значення змінної (ймовірності в осередку А2) отримаємо різні межі інтервалів.

Довірчий інтервал для 95% дорівнює 1,96, тобто майже 2 середньоквадратичні відхилення. Звідси легко навіть в умі оцінити можливий розкид нормальної випадкової величини. Загалом довірчим ймовірностям 90%, 95% і 99% відповідають довірчі інтервали ±1,64, ±1,96 та ±2,58 σ.
У цілому нині функції НОРМ.СТ.РАСП і НОРМ.СТ.ОБР дозволяють зробити будь-який розрахунок, що з нормальним розподілом. Але, щоб полегшити та зменшити кількість дій, у Excel є кілька інших функцій. Наприклад, для розрахунку довірчих інтервалів середньої можна використовувати ДОВЕРИТ.НОРМ. Для перевірки середньої арифметичної є формула Z.ТЕСТ.
Розглянемо ще кілька корисних формул із прикладами.
Функція НОРМ.РАСП
Функція НОРМ.РАСПвідрізняється від НОРМ.СТ.РАСПлише тим, що її використовують для обробки даних будь-якого масштабу, а не лише нормованих. Параметри нормального розподілу вказуються у синтаксисі.
=НОРМ.РАСП(x;середнє;стандартне_відкл;інтегральна)
середня– математичне очікування, яке використовується як перший параметр моделі нормального розподілу
стандартне_відкл– середньоквадратичне відхилення – другий параметр моделі
інтегральна– якщо 0, то розраховується щільність, якщо 1 – значення функції, тобто. P(X
Наприклад, щільність для значення 15, яке витягли з нормальної вибірки з маточенням 10, стандартним відхиленням 3, розраховується так:

Якщо останній параметр поставити 1, отримаємо ймовірність того, що нормальна випадкова величина виявиться менше 15 при заданих параметрах розподілу. Таким чином, ймовірності можна розраховувати безпосередньо за вихідними даними.
Функція НОРМ.ОБР
Це квантиль нормального розподілу, тобто. значення зворотної функції. Синтаксис наступний.
=НОРМ.ОБР(ймовірність;середнє;стандартне_відкл)
ймовірність- Імовірність
середня- маточіння
стандартне_відкл- середньоквадратичне відхилення
Призначення те саме, що й у НОРМ.СТ.ОБР, тільки функція працює з даними будь-якого масштабу.
Приклад показаний у ролику наприкінці статті.
Моделювання нормального розподілу
Для деяких завдань потрібна генерація нормальних випадкових чисел. Готовий функції цього немає. Однак Excel має дві функції, які повертають випадкові числа: ВИПАДМІЖі СЛЧИС.Перша видає випадкові рівномірно розподілені цілі числа у зазначених межах. Друга функція генерує рівномірно розподілені випадкові числа між 0 і 1. Щоб зробити штучну вибірку з будь-яким заданим розподілом, потрібна функція СЛЧИС.
Припустимо, для проведення експерименту необхідно отримати вибірку з нормально розподіленої генеральної сукупності з маточенням 10 і стандартним відхиленням 3. Для одного випадкового значення напишемо формулу Excel.
НОРМ.ОБР(СЛЧИС();10;3)
Простягнемо її на необхідну кількість осередків і нормальна вибірка готова.
Для моделювання стандартизованих даних слід користуватися НОРМ.СТ.ОБР.
Процес перетворення рівномірних чисел на нормальні можна показати на наступній діаграмі. Від рівномірних ймовірностей, що генеруються формулою СЛЧИС, проведено горизонтальні лінії до графіка функції нормального розподілу. Потім від точок перетину ймовірностей із графіком опущені проекції на горизонтальну вісь.