Основы игрового баланса: случайность и вероятность наступления разных событий. Вероятность события. Определение вероятности события
как онтологическая категория отражает меру возможности возникновения какого-либо сущего в каких-либо условиях. В отличие от математических и логической интерпретации этого понятия онтологическая В. не связывает себя с обязательностью количетвенного выражения. Значение В. раскрывается в контексте понимания детерминизма и характера развития в целом.
Отличное определение
Неполное определение ↓
ВЕРОЯТНОСТЬ
понятие, характеризующее количеств. меру возможности появления нек-рого события при определ. условиях. В науч. познании встречаются три интерпретации В. Классическая концепция В., возникшая из математич. анализа азартных игр и наиболее полно разработанная Б. Паскалем, Я. Бернулли и П. Лапласом, рассматривает В. как отношение числа благоприятствующих случаев к общему числу всех равновозможных. Напр., ири бросании игральной кости, имеющей 6 граней, выпадение каждой из них можно ожидать с В., равной 1/6, т. к. ни одна грань не имеет преимуществ перед другой. Подобная симметричность исходов опыта специально учитывается при организации игр, но сравнительно редко встречается при исследовании объективных событий в науке и практике. Классич. интерпретация В. уступила место статистич. концепции В., в основе к-рой лежат действит. наблюдения появления нек-рого события в ходе длит. опыта при точно фиксированных условиях. Практика подтверждает, что чем чаще происходит событие, тем больше степень объективной возможности его появления, или В. Поэтому статистич. интерпретация В. опирается на понятие относит. частоты, к-рое может быть определено опытным путем. В. как теоретич. понятие никогда не совпадает с эмпирически определяемой частотой, однако во мн. случаях она практически мало отличается от относит. частоты, найденной в результате длит. наблюдений. Многие статистики рассматривают В. как «двойник» относит. частоты, к-рая определяется при статистич. исследовании результатов наблюдений
или экспериментов. Менее реалистичным оказалось определение В. как предела относит. частот массовых событий, или коллективов, предложенное Р. Мизесом. В качестве дальнейшего развития частотного подхода к В. выдвигается диспозиционная, или пропенситивная, интерпретация В. (К. Поппер, Я. Хэккинг, М. Бунге, Т. Сетл). Согласно этой интерпретации, В. характеризует свойство порождающих условий, напр. эксперимент. установки, для получения последовательности массовых случайных событий. Именно такая установка порождает физич. диспозиции, или предрасположенности, В. к-рых может быть проверена с помощью относит. частот.
Статистич. интерпретация В. доминирует в науч. познании, ибо она отражает специфич. характер закономерностей, присущих массовым явлениям случайного характера. Во многих физич., биологич., экономич., демографич. и др. социальных процессах приходится учитывать действие множества случайных факторов, к-рые характеризуются устойчивой частотой. Выявление этой устойчивой частоты и количеств. ее оценка с помощью В. дает возможность вскрыть необходимость, к-рая прокладывает себе путь через совокупное действие множества случайностей. В этом находит свое проявление диалектика превращения случайности в необходимость (см. Ф. Энгельс, в кн.: Маркс К. и Энгельс Ф., Соч., т. 20, с. 535-36).
Логическая, или индуктивная, В. характеризует отношение между посылками и заключением недемонстративного и, в частности, индуктивного рассуждения. В отличие от дедукции, посылки индукции не гарантируют истинности заключения, а лишь делают его в той или иной степени правдоподобным. Это правдоподобие при точно сформулированных посылках иногда можно оценивать с помощью В. Значение этой В. чаще всего определяется посредством сравнит. понятий (больше, меньше или равно), а иногда и численным способом. Логич. интерпретацию часто используют для анализа индуктивных рассуждений и построения различных систем вероятностных логик (Р. Карнап, Р. Джефри). В семантич. концепции логич. В. часто определяется как степень подтверждения одного высказывания другими (напр., гипотезы ее эмпирич. данными) .
В связи с развитием теорий принятия решений и игр все большее распростраиение получает т. н. персоналистская интерпретация В. Хотя В. при этом выражает степень веры субъекта и появление нек-рого события, сами В. должны выбираться с таким расчетом, чтобы удовлетворялись аксиомы исчисления В. Поэтому В. при такой интерпретации выражает не столько степень субъективной, сколько разумной веры. Следовательно, решения, принимаемые на основе такой В., будут рациональными, ибо они не учитывают психологич. особенностей и склонностей субъекта.
С гносеологич. т. зр. различие между статистич., логич. и персоналистской интерпретациями В. состоит в том, что если первая дает характеристику объективным свойствам и отношениям массовых явлений случайного характера, то последние две анализируют особенности субъективной, познават. деятельности людей в условиях неопределенности.
ВЕРОЯТНОСТЬ
одно из важнейших понятий науки, характеризующее особое системное видение мира, его строения, эволюции и познания. Специфика вероятностного взгляда на мир раскрывается через включение в число базовых понятий бытия понятий случайности, независимости и иерархии (идеи уровней в структуре и детерминации систем).
Представления о вероятности зародились еще в древности и относились к характеристике нашего знания, при этом признавалось наличие вероятностного знания, отличающегося от достоверного знания и от ложного. Воздействие идеи вероятности на научное мышление, на развитие познания прямо связано с разработкой теории вероятностей как математической дисциплины. Зарождение математического учения о вероятности относится к 17 в., когда было положено начало разработке ядра понятий, допускающих. количественную (числовую) характеристику и выражающих вероятностную идею.
Интенсивные приложения вероятности к развитию познания приходятся на 2-ю пол. 19- 1-ю пол. 20 в. Вероятность вошла в структуры таких фундаментальных наук о природе, как классическая статистическая физика, генетика, квантовая теория, кибернетика (теория информации). Соответственно вероятность олицетворяет тот этап в развитии науки, который ныне определяется как неклассическая наука. Чтобы раскрыть новизну, особенности вероятностного образа мышления, необходимо исходить из анализа предмета теории вероятностей и оснований ее многочисленных приложений. Теорию вероятностей обычно определяют как математическую дисциплину, изучающую закономерности массовых случайных явлений при определенных условиях. Случайность означает, что в рамках массовости бытие каждого элементарного явления не зависит и не определяется бытием других явлений. В то же время сама массовость явлений обладает устойчивой структурой, содержит определенные регулярности. Массовое явление вполне строго делится на подсистемы, и относительное число элементарных явлений в каждой из подсистем (относительная частота) весьма устойчиво. Эта устойчивость сопоставляется с вероятностью. Массовое явление в целом характеризуется распределением вероятностей, т. е. заданием подсистем и соответствующих им вероятностей. Язык теории вероятностей есть язык вероятностных распределений. Соответственно теорию вероятностей и определяют как абстрактную науку об оперировании распределениями.
Вероятность породила в науке представления о статистических закономерностях и статистических системах. Последние суть системы, образованные из независимых или квазинезависимых сущностей, их структура характеризуется распределениями вероятностей. Но как возможно образование систем из независимых сущностей? Обычно предполагается, что для образования систем, имеющих целостные характеристики, необходимо, чтобы между их элементами существовали достаточно устойчивые связи, которые цементируют системы. Устойчивость статистическим системам придает наличие внешних условий, внешнего окружения, внешних, а не внутренних сил. Само определение вероятности всегда опирается на задание условий образования исходного массового явления. Еще одной важнейшей идеей, характеризующей вероятностную парадигму, является идея иерархии (субординации). Эта идея выражает взаимоотношения между характеристиками отдельных элементов и целостными характеристиками систем: последние как бы надстраиваются над первыми.
Значение вероятностных методов в познании заключается в том, что они позволяют исследовать и теоретически выражать закономерности строения и поведения объектов и систем, имеющих иерархическую, «двухуровневую» структуру.
Анализ природы вероятности опирается на частотную, статистическую ее трактовку. Вместе с тем весьма длительное время в науке господствовало такое понимание вероятности, которое получило название логической, или индуктивной, вероятности. Логическую вероятность интересуют вопросы обоснованности отдельного, индивидуального суждения в определенных условиях. Можно ли оценить степень подтверждения (достоверности, истинности) индуктивного заключения (гипотетического вывода) в количественной форме? В ходе становления теории вероятностей такие вопросы неоднократно обсуждались, и стали говорить о степенях подтверждения гипотетических заключений. Эта мера вероятности определяется имеющейся в распоряжении данного человека информацией, его опытом, воззрениями на мир и психологическим складом ума. Во всех подобных случаях величина вероятности не поддается строгим измерениям и практически лежит вне компетенции теории вероятностей как последовательной математической дисциплины.
Объективная, частотная трактовка вероятности утверждалась в науке со значительными трудностями. Первоначально на понимание природы вероятности оказали сильное воздействие те философско-методологические взгляды, которые были характерны для классической науки. Исторически становление вероятностных методов в физике происходило под определяющим воздействием идей механики: статистические системы трактовались просто как механические. Поскольку соответствующие задачи не решались строгими методами механики, то возникли утверждения, что обращение к вероятностным методам и статистическим закономерностям есть результат неполноты наших знаний. В истории развития классической статистической физики предпринимались многочисленные попытки обосновать ее на основе классической механики, однако все они потерпели неудачу. Основания вероятности состоят в том, что она выражает собою особенности структуры определенного класса систем, иного, чем системы механики: состояние элементов этих систем характеризуется неустойчивостью и особым (не сводящимся к механике) характером взаимодействий.
Вхождение вероятности в познание ведет к отрицанию концепции жесткого детерминизма, к отрицанию базовой модели бытия и познания, выработанных в процессе становления классической науки. Базовые модели, представленные статистическими теориями, носят иной, более общий характер: они включают в себя идеи случайности и независимости. Идея вероятности связана с раскрытием внутренней динамики объектов и систем, которая не может быть всецело определена внешними условиями и обстоятельствами.
Концепция вероятностного видения мира, опирающаяся на абсолютизацию представлений о независимости (как и прежде парадигма жесткой детерминации), в настоящее время выявила свою ограниченность, что наиболее сильно сказывается при переходе современной науки к аналитическим методам исследования сложноорганизованных систем и физико-математических основ явлений самоорганизации.
Отличное определение
Неполное определение ↓
Формулы для вычисления вероятности событий
1.3.1. Последовательность независимых испытаний (схема Бернулли)
Предположим, что некоторый эксперимент можно проводить неоднократно при одних и тех же условиях. Пусть этот опыт производится n раз, т. е. проводится последовательность из n испытаний.
Определение. Последовательность n испытаний называют взаимно независимой , если любое событие, связанное с данным испытанием, не зависит от любых событий, относящихся к остальным испытаниям.
Допустим, что некоторое событие A может произойти с вероятностью p в результате одного испытания или не произойти с вероятностью q = 1- p .
Определение . Последовательность из n испытаний образует схему Бернулли, если выполняются следующие условия:
последовательность n испытаний взаимно независима,
2) вероятность события A не изменяется от испытания к испытанию и не зависит от результата в других испытаниях.
Событие A называют “ успехом” испытания, а противоположное событие - “неудачей”. Рассмотрим событие
 ={
в n
испытаниях произошло ровно m
“успехов”}.
={
в n
испытаниях произошло ровно m
“успехов”}.
Для вычисления вероятности этого события справедлива формула Бернулли
p
( )
=
)
=
 , m
= 1, 2, …, n
, (1.6)
, m
= 1, 2, …, n
, (1.6)
где
 - число сочетаний из n
элементов по m
:
- число сочетаний из n
элементов по m
:
 =
=
 =
= .
.
Пример 1.16. Три раза подбрасывают кубик. Найти:
а) вероятность того, что 6 очков выпадет два раза;
б) вероятность того, что число шестерок не появится более двух раз.
Решение . “Успехом” испытания будем считать выпадение на кубике грани с изображением 6 очков.
а)
Общее число испытаний – n
=3,
число “успехов” – m
=
2. Вероятность “успеха” - p
= ,
а вероятность “неудачи” - q
=
1 -
=.
Тогда по формуле Бернулли вероятность
того, что результате трехразового
бросания кубика два раза выпадет сторона
с шестью очками, будет равна
,
а вероятность “неудачи” - q
=
1 -
=.
Тогда по формуле Бернулли вероятность
того, что результате трехразового
бросания кубика два раза выпадет сторона
с шестью очками, будет равна
 .
.
б)
Обозначим через А
событие, которое заключается в том, что
грань с числом очков 6 появится не более
двух раз. Тогда событие можно представить
в виде суммы
трех несовместных
событий А=
 ,
,
где В 3 0 – событие, когда интересующая грань ни разу не появится,
В 3 1 - событие, когда интересующая грань появится один раз,
В 3 2 - событие, когда интересующая грань появится два раза.
По формуле Бернулли (1.6) найдем
p
(А
)
=
р ( )
=
p
(
)
=
p
( )=
)=
 +
+ +
+ =
=
=
 .
.
1.3.2. Условная вероятность события
Условная вероятность отражает влияние одного события на вероятность другого. Изменение условий, в которых проводится эксперимент, также влияет
на вероятность появления интересующего события.
Определение. Пусть A и B – некоторые события, и вероятность p (B )> 0.
Условной вероятностью события A при условии, что “событие B уже произошло” называется отношение вероятности произведения данных событий к вероятности события, которое произошло раньше, чем событие, вероятность которого требуется найти. Условная вероятность обозначается как p (A B ). Тогда по определению
p
(A
B
)
=
 .
(1.7)
.
(1.7)
Пример 1.17. Подбрасывают два кубика. Пространство элементарных событий состоит из упорядоченных пар чисел
(1,1) (1,2) (1,3) (1,4) (1,5) (1,6)
(2,1) (2,2) (2,3) (2,4) (2,5) (2,6)
(3,1) (3,2) (3,3) (3,4) (3,5) (3,6)
(4,1) (4,2) (4,3) (4,4) (4,5) (4,6)
(5,1) (5,2) (5,3) (5,4) (5,5) (5,6)
(6,1) (6,2) (6,3) (6,4) (6,5) (6,6).
В примере 1.16 было установлено, что событие A ={число очков на первом кубике > 4} и событие C ={сумма очков равна 8} зависимы. Составим отношение
 .
.
Это отношение можно интерпретировать следующим образом. Допустим, что о результате первого бросания известно, что число очков на первом кубике > 4. Отсюда следует, что бросание второго кубика может привести к одному из 12 исходов, составляющих событие A :
(5,1) (5,2) (5,3) (5,4) (5,5) (5,6)
(6,1) (6,2) (6,3) (6,4) (6,5) (6,6) .
При
этом событию C
могут соответствовать только два из
них (5,3) (6,2). В этом случае вероятность
события C
будет
равна
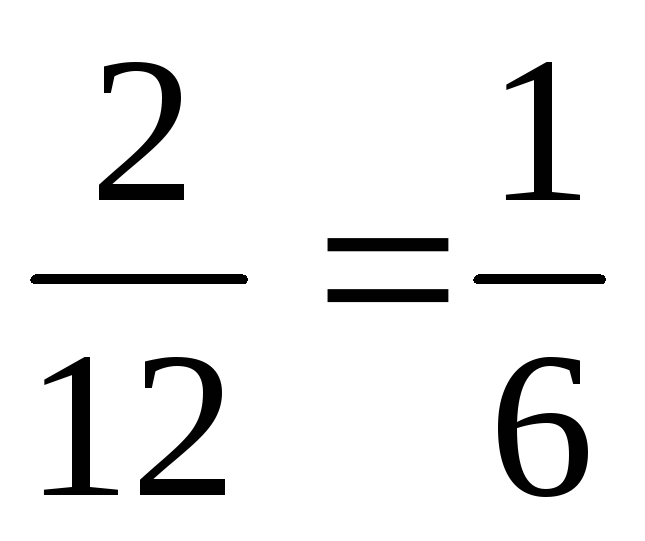 .
Таким образом, информация о наступлении
событияA
оказала влияние на вероятность события
C
.
.
Таким образом, информация о наступлении
событияA
оказала влияние на вероятность события
C
.
Вероятность произведения событий
Теорема умножения
Вероятность произведения событий A 1 A 2 A n определяется формулой
p (A 1 A 2 A n ) = p (A 1) p (A 2 A 1)) p (A n A 1 A 2 A n- 1). (1.8)
Для произведения двух событий отсюда следует, что
p (AB ) = p (A B) p {B ) = p (B A ) p {A ). (1.9)
Пример 1.18. В партии из 25 изделий 5 изделий бракованных. Последовательно наугад выбирают 3 изделия. Определить вероятность того, что все выбранные изделия бракованные.
Решение. Обозначим события:
A 1 = {первое изделие бракованное},
A 2 = {второе изделие бракованное},
A 3 = {третье изделие бракованное},
A = {все изделия бракованные}.
Событие А есть произведение трех событий A = A 1 A 2 A 3 .
Из теоремы умножения (1.6) получим
p (A ) = р( A 1 A 2 A 3 ) = p (A 1) p (A 2 A 1))p (A 3 A 1 A 2).
Классическое определение вероятности позволяет найти p (A 1) – это отношение числа бракованных изделий к общему количеству изделий:
p
(A
1)=
 ;
;
p (A 2) – это отношение числа бракованных изделий, оставшихся после изъятия одного, к общему числу оставшихся изделий:
p
(A
2
A
1))=
 ;
;
p (A 3) – это отношение числа бракованных изделий, оставшихся после изъятия двух бракованных, к общему числу оставшихся изделий:
p
(A
3
A
1 A
2)= .
.
Тогда вероятность события A будет равна
p
(A
)
=

 =
= .
.
Это отношение количества тех наблюдений, при которых рассматриваемое событие наступило, к общему количеству наблюдений. Такая трактовка допустима в случае достаточно большого количества наблюдений или опытов. Например, если среди встреченных на улице людей примерно половина - женщины, то можно говорить, что вероятность того, что встреченный на улице человек окажется женщиной, равна 1/2. Другими словами, оценкой вероятности события может служить частота его наступления в длительной серии независимых повторений случайного эксперимента .
Вероятность в математике
В современном математическом подходе классическая (то есть не квантовая) вероятность задаётся аксиоматикой Колмогорова . Вероятностью называется мера P , которая задаётся на множестве X , называемом вероятностным пространством . Эта мера должна обладать следующими свойствами:
Из указанных условий следует, что вероятностная мера P также обладает свойством аддитивности : если множества A 1 и A 2 не пересекаются, то . Для доказательства нужно положить все A 3 , A 4 , … равными пустому множеству и применить свойство счётной аддитивности.
Вероятностная мера может быть определена не для всех подмножеств множества X . Достаточно определить её на сигма-алгебре , состоящей из некоторых подмножеств множества X . При этом случайные события определяются как измеримые подмножества пространства X , то есть как элементы сигма-алгебры .
Вероятность смысле
Когда мы находим, что основания для того, чтобы какой-нибудь возможный факт произошел в действительности, перевешивают противоположные основания, мы считаем этот факт вероятным , в противном случае - невероятным . Этот перевес положительных оснований над отрицательными, и наоборот, может представлять неопределённое множество степеней, вследствие чего вероятность (и невероятность ) бывает большею или меньшею .
Сложные единичные факты не допускают точного вычисления степеней своей вероятности, но и здесь важно бывает установить некоторые крупные подразделения. Так, например, в области юридической , когда подлежащий суду личный факт устанавливается на основании свидетельских показаний, он всегда остаётся, строго говоря, лишь вероятным, и необходимо знать, насколько эта вероятность значительна; в римском праве здесь принималось четверное деление: probatio plena (где вероятность практически переходит в достоверность ), далее - probatio minus plena , затем - probatio semiplena major и, наконец, probatio semiplena minor .
Кроме вопроса о вероятности дела, может возникать, как в области права, так и в области нравственной (при известной этической точке зрения) вопрос о том, насколько вероятно, что данный частный факт составляет нарушение общего закона. Этот вопрос, служащий основным мотивом в религиозной юриспруденции Талмуда , вызвал и в римско-католическом нравственном богословии (особенно с конца XVI века) весьма сложные систематические построения и огромную литературу, догматическую и полемическую (см. Пробабилизм) .
Понятие вероятности допускает определенное численное выражение в применении лишь к таким фактам, которые входят в состав определенных однородных рядов. Так (в самом простом примере), когда кто-нибудь бросает сто раз кряду монету, мы находим здесь один общий или большой ряд (сумма всех падений монеты), слагающийся из двух частных или меньших, в данном случае численно равных, рядов (падения «орлом» и падения «решкой»); Вероятность, что в данный раз монета упадет решкой, то есть что этот новый член общего ряда будет принадлежать к этому из двух меньших рядов, равняется дроби, выражающей численное отношение между этим малым рядом и большим, именно 1/2, то есть одинаковая вероятность принадлежит к тому или другому из двух частных рядов. В менее простых примерах заключение не может быть выведено прямо из данных самой задачи, а требует предварительной индукции . Так, например, спрашивается: какая вероятность существует для данного новорожденного дожить до 80 лет? Здесь должно составить общий, или большой, ряд из известного числа людей, рожденных в подобных же условиях и умирающих в различном возрасте (это число должно быть достаточно велико, чтобы устранить случайные отклонения, и достаточно мало, чтобы сохранялась однородность ряда, ибо для человека, рождённого, например, в Санкт-Петербурге в обеспеченном культурном семействе, всё миллионное население города, значительная часть которого состоит из лиц разнообразных групп, могущих умереть раньше времени - солдат, журналистов, рабочих опасных профессий, - представляет группу слишком разнородную для настоящего определения вероятности); пусть этот общий ряд состоит из десяти тысяч человеческих жизней; в него входят меньшие ряды, представляющие число доживающих до того или другого возраста; один из этих меньших рядов представляет число доживающих до 80 лет. Но определить численность этого меньшего ряда (как и всех других) невозможно a priori ; это делается чисто индуктивным путем, посредством статистики . Положим, статистические исследования установили, что из 10000 петербуржцев среднего класса до 80 лет доживают только 45; таким образом, этот меньший ряд относится к большому, как 45 к 10000, и вероятность для данного лица принадлежать к этому меньшему ряду, то есть дожить до 80 лет, выражается дробью 0,0045. Исследование вероятности с математической точки зрения составляет особую дисциплину - теорию вероятностей .
См. также
Примечания
Литература
- Альфред Реньи. Письма о вероятности / пер. с венг. Д.Сааса и А.Крамли под ред. Б. В. Гнеденко. М.: Мир. 1970
- Гнеденко Б. В. Курс теории вероятностей. М., 2007. 42 с.
- Купцов В. И. Детерминизм и вероятность. М., 1976. 256 с.
Wikimedia Foundation . 2010 .
Синонимы :Антонимы :
Смотреть что такое "Вероятность" в других словарях:
Общенаучная и филос. категория, обозначающая количественную степень возможности появления массовых случайных событий при фиксированных условиях наблюдения, характеризующую устойчивость их относительных частот. В логике семантическая степень… … Философская энциклопедия
ВЕРОЯТНОСТЬ, число в интервале от нуля до единицы включительно, представляющее возможность свершения данного события. Вероятность события определяется как отношение числа шансов того, что событие может произойти, к общему количеству возможных… … Научно-технический энциклопедический словарь
По всей вероятности.. Словарь русских синонимов и сходных по смыслу выражений. под. ред. Н. Абрамова, М.: Русские словари, 1999. вероятность возможность, вероятие, шанс, объективная возможность, маза, допустимость, риск. Ant. невозможность… … Словарь синонимов
вероятность - Мера того, что событие может произойти. Примечание Математическое определение вероятности: «действительное число в интервале от 0 до 1, относящееся к случайному событию». Число может отражать относительную частоту в серии наблюдений… … Справочник технического переводчика
Вероятность - «математическая, числовая характеристика степени возможности появления какого либо события в тех или иных определенных, могущих повторяться неограниченное число раз условиях». Если исходить из этого классического… … Экономико-математический словарь
- (probability) Возможность наступления какого либо события или определенного результата. Может быть представлена в виде шкалы с делениями от 0 до 1. При нулевой вероятности события его наступление невозможно. При вероятности, равной 1, наступление … Словарь бизнес-терминов
Знать, как оценить вероятность того или иного события на основе коэффициентов, крайне важно для выбора правильной ставки. Если вы не понимаете, как перевести букмекерский коэффициент в вероятность, то никогда не сможете определить, как соотносится букмекерский коэффициент с реальными шансами того, что событие состоится. Следует понимать, если вероятность события по версии букмекеров ниже, чем вероятность этого же события по вашей собственной версии, ставка на это событие будет ценной. Сравнить коэффициенты на разные события можно на сайте Odds.ru .
1.1. Типы коэффициентов
Букмекерские конторы, как правило, предлагают три типа коэффициентов – десятичный, дробный и американский. Разберем каждую из разновидностей.
1.2. Десятичные коэффициенты
Десятичные коэффициенты при умножении на размер ставки позволяют рассчитать всю сумму, которую вы получите на руки в случае выигрыша. К примеру, если вы поставили 1 доллар на коэффициент 1,80, в случае выигрыша вы получите 1 доллар 80 центов (1 доллар – возвращенная сумма ставки, 0,80 – выигрыш по ставке, он же ваша чистая прибыль).
То есть вероятность исхода, по версии букмекеров, составляет 55%.
1.3. Дробные коэффициенты
Дробные коэффициенты – наиболее традиционный вид коэффициентов. В числителе показана потенциальная сумма чистого выигрыша. В знаменателе – сумма ставки, которую нужно сделать, чтобы этот самый выигрыш получить. К примеру, коэффициент 7/2 означает, что для того, чтобы получить чистый выигрыш в размере 7 долларов, вам необходимо поставить 2 доллара.
Для того чтобы рассчитать вероятность события на основе десятичного коэффициента, следует провести простые вычисления – знаменатель разделить на сумму числителя и знаменателя. Для вышеобозначенного коэффициента 7/2 расчет будет таким:
2 / (7+2) = 2 / 9 = 0,22
То есть вероятность исхода, по версии букмекеров, составляет 22%.
1.4. Американские коэффициенты
Данный вид коэффициентов популярен в Северной Америке. На первый взгляд, они кажутся довольно сложными и непонятными, но не стоит пугаться. Понимание американских коэффициентов может вам пригодиться, например, при игре в американских казино, для понимания котировок, демонстрируемых в североамериканских спортивных трансляциях. Разберем, как оценить вероятность исхода на основе американских коэффициентов.
В первую очередь надо понимать, что американские коэффициенты бывают положительными и отрицательными. Отрицательный американский коэффициент всегда идет в формате, к примеру, «-150». Это означает, что для того, чтобы получить 100 долларов чистой прибыли (выигрыш), необходимо поставить 150 долларов.
Положительный американский коэффициент рассчитывается наоборот. К примеру, у нас есть коэффициент «+120». Это означает, что для того, чтобы получить 120 долларов чистой прибыли (выигрыш), вам необходимо поставить 100 долларов.
Расчет вероятности на основе отрицательных американских коэффициентов делается по следующей формуле:
(-(отрицательный американский коэффициент)) / ((-(отрицательный американский коэффициент)) + 100)
(-(-150)) / ((-(-150)) + 100) = 150 / (150 + 100) = 150 / 250 = 0,6
То есть вероятность события, на которое дается отрицательный американский коэффициент «-150», составляет 60%.
Теперь рассмотрим аналогичные вычисления для положительного американского коэффициента. Вероятность в этом случае рассчитывается по следующей формуле:
100 / (положительный американский коэффициент + 100)
100 / (120 + 100) = 100 / 220 = 0.45
То есть вероятность события, на которое дается положительный американский коэффициент «+120», составляет 45%.
1.5. Как переводить коэффициенты из одного формата в другой?
Умение переводить коэффициенты из одного формата в другой может впоследствии сослужить вам хорошую службу. Как ни странно, до сих пор есть конторы, в которых коэффициенты не конвертируются и показаны лишь в одном, непривычном для нас формате. Рассмотрим на примерах, как это делать. Но для начала нам надо научиться вычислять вероятность исхода на основе данного нам коэффициента.
1.6. Как на основе вероятности рассчитать десятичный коэффициент?
Здесь все очень просто. Необходимо 100 разделить на вероятность события в процентном отношении. То есть, если предполагаемая вероятность события составляет 60%, вам надо:
При предполагаемой вероятности события в 60% десятичный коэффициент будет составлять 1,66.
1.7. Как на основе вероятности рассчитать дробный коэффициент?
В данном случае необходимо 100 разделить на вероятность события и от полученного результата отнять единицу. К примеру, вероятность события составляет 40%:
(100 / 40) — 1 = 2,5 — 1 = 1,5
То есть мы получаем дробный коэффициент 1,5/1 или, для удобства счета, – 3/2.
1.8. Как на основе вероятного исхода рассчитать американский коэффициент?
Здесь многое будет зависеть от вероятности события – будет ли она более 50% или менее. Если вероятность события более 50%, то расчет будет производиться по такой формуле:
— ((вероятность) / (100 — вероятность)) * 100
Например, если вероятность события составляет 80%, то:
— (80 / (100 — 80)) * 100 = — (80 / 20) * 100 = -4 * 100 = (-400)
При предполагаемой вероятности события в 80% мы получили отрицательный американский коэффициент «-400».
Если вероятность события менее 50 процентов, то формула будет следующей:
((100 — вероятность) / вероятность) * 100
Например, если вероятность события составляет 40%, то:
((100-40) / 40) * 100 = (60 / 40) * 100 = 1,5 * 100 = 150
При предполагаемой вероятности события в 40% мы получили положительный американский коэффициент «+150».
Эти вычисления помогут вам лучше понять концепцию ставок и коэффициентов, научиться оценивать истинную стоимость той или иной ставки.
Фактически формулы (1) и (2) это краткая запись условной вероятности на основе таблицы сопряженности признаков. Вернемся к примеру, рассмотренному (рис. 1). Предположим, что нам стало известно, будто некая семья собирается купить широкоэкранный телевизор. Какова вероятность того, что эта семья действительно купит такой телевизор?

Рис. 1. Поведение покупателей широкоэкранных телевизоров
В данном случае нам необходимо вычислить условную вероятность Р (покупка совершена | покупка планировалась). Поскольку нам известно, что семья планирует покупку, выборочное пространство состоит не из всех 1000 семей, а только из тех, которые планируют покупку широкоэкранного телевизора. Из 250 таких семей 200 действительно купили этот телевизор. Следовательно, вероятность того, что семья действительно купит широкоэкранный телевизор, если она это запланировала, можно вычислить по следующей формуле:
Р (покупка совершена | покупка планировалась) = количество семей, планировавших и купивших широкоэкранный телевизор / количество семей, планировавших купить широкоэкранный телевизор = 200 / 250 = 0,8
Этот же результат дает формула (2):

где событие А заключается в том, что семья планирует покупку широкоформатного телевизора, а событие В - в том, что она его действительно купит. Подставляя в формулу реальные данные, получаем:
Дерево решений
На рис. 1 семьи разделены на четыре категории: планировавшие покупку широкоэкранного телевизора и не планировавшие, а также купившие такой телевизор и не купившие. Аналогичную классификацию можно выполнить с помощью дерева решений (рис. 2). Дерево, изображенное на рис. 2, имеет две ветви, соответствующие семьям, которые планировали приобрести широкоэкранный телевизор, и семьям, которые не делали этого. Каждая из этих ветвей разделяется на две дополнительные ветви, соответствующие семьям, купившим и не купившим широкоэкранный телевизор. Вероятности, записанные на концах двух основных ветвей, являются безусловными вероятностями событий А и А’ . Вероятности, записанные на концах четырех дополнительных ветвей, являются условными вероятностями каждой комбинации событий А и В . Условные вероятности вычисляются путем деления совместной вероятности событий на соответствующую безусловную вероятность каждого из них.

Рис. 2. Дерево решений
Например, чтобы вычислить вероятность того, что семья купит широкоэкранный телевизор, если она запланировала сделать это, следует определить вероятность события покупка запланирована и совершена , а затем поделить его на вероятность события покупка запланирована . Перемещаясь по дереву решения, изображенному на рис. 2, получаем следующий (аналогичный предыдущему) ответ:
Статистическая независимость
В примере с покупкой широкоэкранного телевизора вероятность того, что случайно выбранная семья приобрела широкоэкранный телевизор при условии, что она планировала это сделать, равна 200/250 = 0,8. Напомним, что безусловная вероятность того, что случайно выбранная семья приобрела широкоэкранный телевизор, равна 300/1000 = 0,3. Отсюда следует очень важный вывод. Априорная информация о том, что семья планировала покупку, влияет на вероятность самой покупки. Иначе говоря, эти два события зависят друг от друга. В противоположность этому примеру, существуют статистически независимые события, вероятности которых не зависят друг от друга. Статистическая независимость выражается тождеством: Р(А|В) = Р(А) , где Р(А|В) - вероятность события А при условии, что произошло событие В , Р(А) - безусловная вероятность события А.
Обратите внимание на то, что события А и В Р(А|В) = Р(А) . Если в таблице сопряженности признаков, имеющей размер 2×2, это условие выполняется хотя бы для одной комбинации событий А и В , оно будет справедливым и для любой другой комбинации. В нашем примере события покупка запланирована и покупка совершена не являются статистически независимыми, поскольку информация об одном событии влияет на вероятность другого.
Рассмотрим пример, в котором показано, как проверить статистическую независимость двух событий. Спросим у 300 семей, купивших широкоформатный телевизор, довольны ли они своей покупкой (рис. 3). Определите, связаны ли между собой степень удовлетворенности покупкой и тип телевизора.

Рис. 3. Данные, характеризующие степень удовлетворенности покупателей широкоэкранных телевизоров
Судя по этим данным,
В то же время,
Р (покупатель удовлетворен) = 240 / 300 = 0,80
Следовательно, вероятность того, что покупатель удовлетворен покупкой, и того, что семья купила HDTV-телевизор, равны между собой, и эти события являются статистически независимыми, поскольку никак не связаны между собой.
Правило умножения вероятностей
Формула для вычисления условной вероятности позволяет определить вероятность совместного события А и В . Разрешив формулу (1)
![]()
относительно совместной вероятности Р(А и В) , получаем общее, правило умножения вероятностей. Вероятность события А и В равна вероятности события А при условии, что наступило событие В В :
(3) Р(А и В) = Р(А|В) * Р(В)
Рассмотрим в качестве примера 80 семей, купивших широкоэкранный HDTV-телевизор (рис. 3). В таблице указано, что 64 семьи удовлетворены покупкой и 16 - нет. Предположим, что среди них случайным образом выбираются две семьи. Определите вероятность, что оба покупателя окажутся довольными. Используя формулу (3), получаем:
Р(А и В) = Р(А|В) * Р(В)
где событие А заключается в том, что вторая семья удовлетворена своей покупкой, а событие В - в том, что первая семья удовлетворена своей покупкой. Вероятность того, что первая семья удовлетворена своей покупкой, равна 64/80. Однако вероятность того, что вторая семья также удовлетворена своей покупкой, зависит от ответа первой семьи. Если первая семья после опроса не возвращается в выборку (выбор без возвращения), количество респондентов снижается до 79. Если первая семья оказалась удовлетворенной своей покупкой, вероятность того, что вторая семья также будет довольна, равна 63/79, поскольку в выборке осталось только 63 семьи, удовлетворенные своим приобретением. Таким образом, подставляя в формулу (3) конкретные данные, получим следующий ответ:
Р(А и В) = (63/79)(64/80) = 0,638.
Следовательно, вероятность того, что обе семьи довольны своими покупками, равна 63,8%.
Предположим, что после опроса первая семья возвращается в выборку. Определите вероятность того, что обе семьи окажутся довольными своей покупкой. В этом случае вероятности того, что обе семьи удовлетворены своей покупкой одинаковы, и равны 64/80. Следовательно, Р(А и В) = (64/80)(64/80) = 0,64. Таким образом, вероятность того, что обе семьи довольны своими покупками, равна 64,0%. Этот пример показывает, что выбор второй семьи не зависит от выбора первой. Таким образом, заменяя в формуле (3) условную вероятность Р(А|В) вероятностью Р(А) , мы получаем формулу умножения вероятностей независимых событий.
Правило умножения вероятностей независимых событий. Если события А и В являются статистически независимыми, вероятность события А и В равна вероятности события А , умноженной на вероятность события В .
(4) Р(А и В) = Р(А)Р(В)
Если это правило выполняется для событий А и В , значит, они являются статистически независимыми. Таким образом, существуют два способа определить статистическую независимость двух событий:
- События А и В являются статистически независимыми друг от друга тогда и только тогда, когда Р(А|В) = Р(А) .
- События А и B являются статистически независимыми друг от друга тогда и только тогда, когда Р(А и В) = Р(А)Р(В) .
Если в таблице сопряженности признаков, имеющей размер 2×2, одно из этих условий выполняется хотя бы для одной комбинации событий А и B , оно будет справедливым и для любой другой комбинации.
Безусловная вероятность элементарного события
(5) Р(А) = P(A|B 1)Р(B 1) + P(A|B 2)Р(B 2) + … + P(A|B k)Р(B k)
где события B 1 , B 2 , … B k являются взаимоисключающими и исчерпывающими.
Проиллюстрируем применение этой формулы на примере рис.1. Используя формулу (5), получаем:
Р(А) = P(A|B 1)Р(B 1) + P(A|B 2)Р(B 2)
где Р(А) - вероятность того, что покупка планировалась, Р(В 1) - вероятность того, что покупка совершена, Р(В 2) - вероятность того, что покупка не совершена.
ТЕОРЕМА БАЙЕСА
Условная вероятность события учитывает информацию о том, что произошло некое другое событие. Этот подход можно использовать как для уточнения вероятности с учетом вновь поступившей информации, так и для вычисления вероятности, что наблюдаемый эффект является следствием некоей конкретной причины. Процедура уточнения этих вероятностей называется теоремой Байеса. Впервые она была разработана Томасом Байесом в 18 веке.
Предположим, что компания, упомянутая выше, исследует рынок сбыта новой модели телевизора. В прошлом 40% телевизоров, созданных компанией, пользовались успехом, а 60% моделей признания не получили. Прежде чем объявить о выпуске новой модели, специалисты по маркетингу тщательно исследуют рынок и фиксируют спрос. В прошлом успех 80% моделей, получивших признание, прогнозировался заранее, в то же время 30% благоприятных прогнозов оказались неверными. Для новой модели отдел маркетинга дал благоприятный прогноз. Какова вероятность того, что новая модель телевизора будет пользоваться спросом?
Теорему Байеса можно вывести из определений условной вероятности (1) и (2). Чтобы вычислить вероятность Р(В|А), возьмем формулу (2):
и подставим вместо Р(А и В) значение из формулы (3):
Р(А и В) = Р(А|В) * Р(В)

Подставляя вместо Р(А) формулу (5), получаем теорему Байеса:
где события B 1 , В 2 , … В k являются взаимоисключающими и исчерпывающими.
Введем следующие обозначения: событие S - телевизор пользуется спросом , событие S’ - телевизор не пользуется спросом , событие F - благоприятный прогноз , событие F’ - неблагоприятный прогноз . Допустим, что P(S) = 0,4, P(S’) = 0,6, P(F|S) = 0,8, P(F|S’) = 0,3. Применяя теорему Байеса получаем:
Вероятность спроса на новую модель телевизора при условии благоприятного прогноза равна 0,64. Таким образом, вероятность отсутствия спроса при условии благоприятного прогноза равна 1–0,64=0,36. Процесс вычислений представлен на рис. 4.

Рис. 4. (а) Вычисления по формуле Байеса для оценки вероятности спроса телевизоров; (б) Дерево решения при исследовании спроса на новую модель телевизора
Рассмотрим пример применения теоремы Байеса для медицинской диагностики. Вероятность того, что человек страдает от определенного заболевания, равна 0,03. Медицинский тест позволяет проверить, так ли это. Если человек действительно болен, вероятность точного диагноза (утверждающего, что человек болен, когда он действительно болен) равна 0,9. Если человек здоров, вероятность ложноположительного диагноза (утверждающего, что человек болен, когда он здоров) равна 0,02. Допустим, что медицинский тест дал положительный результат. Какова вероятность того, что человек действительно болен? Какова вероятность точного диагноза?
Введем следующие обозначения: событие D - человек болен , событие D’ - человек здоров , событие Т - диагноз положительный , событие Т’ - диагноз отрицательный . Из условия задачи следует, что Р(D) = 0,03, P(D’) = 0,97, Р(T|D) = 0,90, P(T|D’) = 0,02. Применяя формулу (6), получаем:
Вероятность того, что при положительном диагнозе человек действительно болен, равна 0,582 (см. также рис. 5). Обратите внимание на то, что знаменатель формулы Байеса равен вероятности положительного диагноза, т.е. 0,0464.
