Basics of game balance: randomness and the likelihood of various events occurring. Probability of an event. Determining the probability of an event
as an ontological category reflects the extent of the possibility of the emergence of any entity under any conditions. Unlike mathematical and logical interpretation of this concept, ontological V. does not associate itself with the obligation of quantitative expression. The meaning of V. is revealed in the context of understanding determinism and the nature of development in general.
Excellent definition
Incomplete definition ↓
PROBABILITY
concept characterizing quantities. the measure of the possibility of the occurrence of a certain event at a certain conditions. In scientific knowledge there are three interpretations of V. The classical concept of V., which arose from mathematical. analysis of gambling and most fully developed by B. Pascal, J. Bernoulli and P. Laplace, considers winning as the ratio of the number of favorable cases to total number all equally possible. For example, or throwing dice, having 6 sides, the loss of each of them can be expected with a V. equal to 1/6, since no one side has advantages over the other. Such symmetry of experimental outcomes is specially taken into account when organizing games, but is relatively rare in the study of objective events in science and practice. Classic V.'s interpretation gave way to statistics. V.'s concepts, which are based on the actual observing the occurrence of a certain event over a long period of time. experience under precisely fixed conditions. Practice confirms that the more often an event occurs, the greater the degree of objective possibility of its occurrence, or B. Therefore, statistical. V.'s interpretation is based on the concept of relates. frequency, which can be determined experimentally. V. as a theoretical the concept never coincides with the empirically determined frequency, however, in plural. In cases, it differs practically little from the relative one. frequency found as a result of duration. observations. Many statisticians consider V. as a “double” refers. frequencies, edges are determined statistically. study of observational results
or experiments. Less realistic was the definition of V. as the limit relates. frequencies of mass events, or groups, proposed by R. Mises. As further development The frequency approach to V. puts forward a dispositional, or propensitive, interpretation of V. (K. Popper, J. Hacking, M. Bunge, T. Settle). According to this interpretation, V. characterizes the property of generating conditions, for example. experiment. installations to obtain a sequence of massive random events. It is precisely this attitude that gives rise to physical dispositions, or predispositions, V. which can be checked using relatives. frequency
Statistical V.'s interpretation dominates scientific research. cognition, because it reflects specific. the nature of the patterns inherent in mass phenomena of a random nature. In many physical, biological, economic, demographic. and etc. social processes it is necessary to take into account the effect of many random factors, which are characterized by a stable frequency. Identifying these stable frequencies and quantities. its assessment with the help of V. makes it possible to reveal the necessity that makes its way through the cumulative action of many accidents. This is where the dialectic of transforming chance into necessity finds its manifestation (see F. Engels, in the book: K. Marx and F. Engels, Works, vol. 20, pp. 535-36).
Logical, or inductive, reasoning characterizes the relationship between the premises and the conclusion of non-demonstrative and, in particular, inductive reasoning. Unlike deduction, the premises of induction do not guarantee the truth of the conclusion, but only make it more or less plausible. This plausibility, with precisely formulated premises, can sometimes be assessed using V. The value of this V. is most often determined by comparison. concepts (more than, less than or equal to), and sometimes in a numerical way. Logical interpretation is often used to analyze inductive reasoning and construct various systems of probabilistic logic (R. Carnap, R. Jeffrey). In semantics logical concepts V. is often defined as the degree to which one statement is confirmed by others (for example, a hypothesis by its empirical data).
In connection with the development of theories of decision making and games, the so-called personalistic interpretation of V. Although V. at the same time expresses the degree of faith of the subject and the occurrence of a certain event, V. themselves must be chosen in such a way that the axioms of the calculus of V. are satisfied. Therefore, V. with such an interpretation expresses not so much the degree of subjective, but rather reasonable faith . Consequently, decisions made on the basis of such V. will be rational, because they do not take into account the psychological. characteristics and inclinations of the subject.
With epistemological t.zr. difference between statistical, logical. and personalistic interpretations of V. is that if the first characterizes the objective properties and relationships of mass phenomena of a random nature, then the last two analyze the features of the subjective, cognizant. human activities under conditions of uncertainty.
PROBABILITY
one of the most important concepts of science, characterizing a special systemic vision of the world, its structure, evolution and knowledge. The specificity of the probabilistic view of the world is revealed through the inclusion of the concepts of randomness, independence and hierarchy (the idea of levels in the structure and determination of systems) among the basic concepts of existence.
Ideas about probability originated in ancient times and related to the characteristics of our knowledge, while the existence of probabilistic knowledge was recognized, which differed from reliable knowledge and from false knowledge. The impact of the idea of probability on scientific thinking and on the development of knowledge is directly related to the development of probability theory as a mathematical discipline. The origin of the mathematical doctrine of probability dates back to the 17th century, when the development of a core of concepts allowing. quantitative (numerical) characteristics and expressing a probabilistic idea.
Intensive applications of probability to the development of cognition occur in the 2nd half. 19 - 1st half. 20th century Probability has entered the structures of such fundamental sciences of nature as classical statistical physics, genetics, quantum theory, and cybernetics (information theory). Accordingly, probability personifies that stage in the development of science, which is now defined as non-classical science. To reveal the novelty and features of the probabilistic way of thinking, it is necessary to proceed from an analysis of the subject of probability theory and the foundations of its numerous applications. Probability theory is usually defined as a mathematical discipline that studies the patterns of mass random phenomena under certain conditions. Randomness means that within the framework of mass character, the existence of each elementary phenomenon does not depend on and is not determined by the existence of other phenomena. At the same time, the mass nature of phenomena itself has a stable structure and contains certain regularities. A mass phenomenon is quite strictly divided into subsystems, and the relative number of elementary phenomena in each of the subsystems (relative frequency) is very stable. This stability is compared with probability. A mass phenomenon as a whole is characterized by a probability distribution, that is, by specifying subsystems and their corresponding probabilities. The language of probability theory is the language of probability distributions. Accordingly, probability theory is defined as the abstract science of operating with distributions.
Probability gave rise in science to ideas about statistical patterns and statistical systems. The last essence systems formed from independent or quasi-independent entities, their structure is characterized by probability distributions. But how is it possible to form systems from independent entities? It is usually assumed that for the formation of systems with integral characteristics, it is necessary that sufficiently stable connections exist between their elements that cement the systems. Stability of statistical systems is given by the presence of external conditions, external environment, external rather than internal forces. The very definition of probability is always based on setting the conditions for the formation of the initial mass phenomenon. Another important idea characterizing the probabilistic paradigm is the idea of hierarchy (subordination). This idea expresses the relationship between characteristics individual elements and holistic characteristics of systems: the latter seem to be built on top of the former.
The importance of probabilistic methods in cognition lies in the fact that they make it possible to study and theoretically express the patterns of structure and behavior of objects and systems that have a hierarchical, “two-level” structure.
Analysis of the nature of probability is based on its frequency, statistical interpretation. At the same time, for a very long time, such an understanding of probability dominated in science, which was called logical, or inductive, probability. Logical probability is interested in questions of the validity of a separate, individual judgment under certain conditions. Is it possible to evaluate the degree of confirmation (reliability, truth) of an inductive conclusion (hypothetical conclusion) in quantitative form? During the development of probability theory, such questions were repeatedly discussed, and they began to talk about the degrees of confirmation of hypothetical conclusions. This measure of probability is determined by the available this person information, his experience, views on the world and psychological mindset. In all such cases, the magnitude of probability is not amenable to strict measurements and practically lies outside the competence of probability theory as a consistent mathematical discipline.
The objective, frequentist interpretation of probability was established in science with significant difficulties. Initially, the understanding of the nature of probability was strongly influenced by those philosophical and methodological views that were characteristic of classical science. Historically, the development of probabilistic methods in physics occurred under the determining influence of the ideas of mechanics: statistical systems were interpreted simply as mechanical. Since the corresponding problems were not solved by strict methods of mechanics, assertions arose that turning to probabilistic methods and statistical laws is the result of the incompleteness of our knowledge. In the history of the development of classical statistical physics, numerous attempts were made to substantiate it on the basis of classical mechanics, but they all failed. The basis of probability is that it expresses the structural features of a certain class of systems, other than mechanical systems: the state of the elements of these systems is characterized by instability and a special (not reducible to mechanics) nature of interactions.
The entry of probability into knowledge leads to the denial of the concept of hard determinism, to the denial of the basic model of being and knowledge developed in the process of the formation of classical science. The basic models represented by statistical theories have a different, more general character: These include ideas of randomness and independence. The idea of probability is associated with the disclosure of the internal dynamics of objects and systems, which cannot be fully determined external conditions and circumstances.
The concept of a probabilistic vision of the world, based on the absolutization of ideas about independence (as before the paradigm of rigid determination), has now revealed its limitations, which most strongly affects the transition modern science To analytical methods research into complex systems and the physical and mathematical foundations of self-organization phenomena.
Excellent definition
Incomplete definition ↓
Formulas for calculating the probability of events
1.3.1. Sequence of independent tests (Bernoulli circuit)
Suppose that some experiment can be carried out repeatedly under the same conditions. Let this experience be made n times, i.e., a sequence of n tests.
Definition. Subsequence n tests are called mutually independent , if any event related to a given test is independent of any events related to other tests.
Let's assume that some event A likely to happen p as a result of one test or not likely to happen q= 1- p.
Definition . Sequence of n tests forms a Bernoulli scheme if the following conditions are met:
subsequence n tests are mutually independent,
2) probability of an event A does not change from trial to trial and does not depend on the result in other trials.
Event A is called the “success” of the test, and the opposite event is called “failure.” Consider the event
 =( in n tests happened exactly m“success”).
=( in n tests happened exactly m“success”).
To calculate the probability of this event, the Bernoulli formula is valid
p( )
=
)
=
 , m
= 1, 2, …, n
, (1.6)
, m
= 1, 2, …, n
, (1.6)
Where  - number of combinations of n elements by m
:
- number of combinations of n elements by m
:
 =
=
 =
= .
.
Example 1.16. The die is tossed three times. Find:
a) the probability that 6 points will appear twice;
b) the probability that the number of sixes will not appear more than twice.
Solution . We will consider the “success” of the test to be when the side with the image of 6 points appears on the die.
a) Total number of tests – n=3, number of “successes” – m
= 2. Probability of “success” - p= ,
and the probability of “failure” is q= 1 - =. Then, according to Bernoulli's formula, the probability that, as a result of throwing a die three times, the side with six points will appear twice, will be equal to
,
and the probability of “failure” is q= 1 - =. Then, according to Bernoulli's formula, the probability that, as a result of throwing a die three times, the side with six points will appear twice, will be equal to
 .
.
b) Let us denote by A an event that means that a side with a score of 6 will appear no more than twice. Then the event can be represented as the sum of three incompatible events A=
 ,
,
Where IN 3 0 – an event when the edge of interest never appears,
IN 3 1 - event when the edge of interest appears once,
IN 3 2 - event when the edge of interest appears twice.
Using the Bernoulli formula (1.6) we find
p(A)
= p ( )
=
p(
)
=
p( )=
)=
 +
+ +
+ =
=
=
 .
.
1.3.2. Conditional probability of an event
Conditional probability reflects the influence of one event on the probability of another. Changing the conditions under which the experiment is carried out also affects
on the probability of occurrence of the event of interest.
Definition. Let A And B– some events, and probability p(B)> 0.
Conditional probability events A provided that the “event Balready happened” is the ratio of the probability of the occurrence of these events to the probability of an event that occurred earlier than the event whose probability is required to be found. Conditional probability is denoted as p(A B). Then by definition
p
(A
B)
=
 .
(1.7)
.
(1.7)
Example 1.17. Two dice are tossed. The space of elementary events consists of ordered pairs of numbers
(1,1) (1,2) (1,3) (1,4) (1,5) (1,6)
(2,1) (2,2) (2,3) (2,4) (2,5) (2,6)
(3,1) (3,2) (3,3) (3,4) (3,5) (3,6)
(4,1) (4,2) (4,3) (4,4) (4,5) (4,6)
(5,1) (5,2) (5,3) (5,4) (5,5) (5,6)
(6,1) (6,2) (6,3) (6,4) (6,5) (6,6).
In Example 1.16 it was determined that the event A=(number of points on the first die > 4) and event C=(sum of points is 8) dependent. Let's make a relation
 .
.
This relationship can be interpreted as follows. Let us assume that the result of the first throw is known to be that the number of points on the first die is > 4. It follows that throwing the second die can lead to one of the 12 outcomes that make up the event A:
(5,1) (5,2) (5,3) (5,4) (5,5) (5,6)
(6,1) (6,2) (6,3) (6,4) (6,5) (6,6) .
At this event C only two of them can match (5,3) (6,2). In this case, the probability of the event C
will be equal 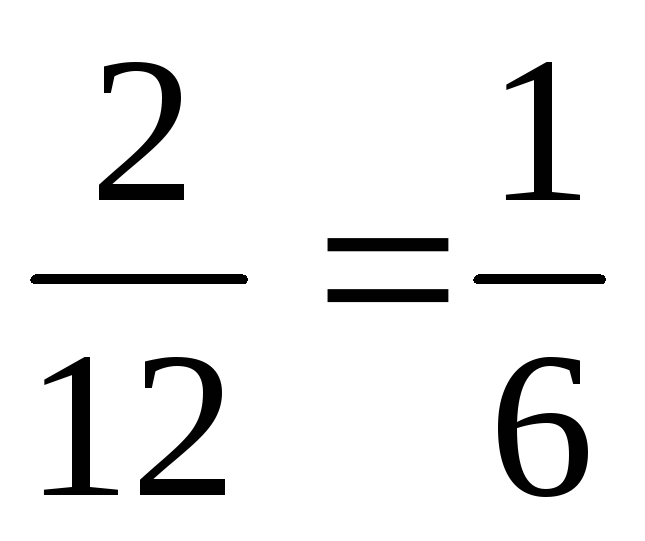 . Thus, information about the occurrence of an event A influenced the likelihood of an event C.
. Thus, information about the occurrence of an event A influenced the likelihood of an event C.
Probability of events happening
Multiplication theorem
Probability of events happeningA 1 A 2 A n is determined by the formula
p(A 1 A 2 A n)= p(A 1)p(A 2 A 1)) p(A n A 1 A 2 A n- 1). (1.8)
For the product of two events it follows that
p(AB)= p(A B)p{B)= p(B A)p{A). (1.9)
Example 1.18. In a batch of 25 products, 5 products are defective. 3 items are selected at random in succession. Determine the probability that all selected products are defective.
Solution. Let's denote the events:
A 1 = (first product is defective),
A 2 = (second product is defective),
A 3 = (third product is defective),
A = (all products are defective).
Event A is the product of three events A = A 1 A 2 A 3 .
From the multiplication theorem (1.6) we get
p(A)= p( A 1 A 2 A 3 ) = p(A 1) p(A 2 A 1))p(A 3 A 1 A 2).
The classical definition of probability allows us to find p(A 1) is the ratio of the number of defective products to total number products:
p(A 1)=
 ;
;
p(A 2) – This the ratio of the number of defective products remaining after the removal of one to the total number of remaining products:
p(A 2
A 1))=
 ;
;
p(A 3) – this is the ratio of the number of defective products remaining after the removal of two defective ones to the total number of remaining products:
p(A 3
A 1 A 2)= .
.
Then the probability of the event A will be equal
p(A)
=

 =
= .
.
This is the ratio of the number of those observations in which the event in question occurred to the total number of observations. This interpretation is acceptable in the case of sufficient large quantity observations or experiments. For example, if about half of the people you meet on the street are women, then you can say that the probability that the person you meet on the street will be a woman is 1/2. In other words, an estimate of the probability of an event can be the frequency of its occurrence in a long series of independent repetitions of a random experiment.
Probability in mathematics
In the modern mathematical approach, classical (that is, not quantum) probability is given by the Kolmogorov axiomatics. Probability is a measure P, which is defined on the set X, called probability space. This measure must have the following properties:
From these conditions it follows that the probability measure P also has the property additivity: if sets A 1 and A 2 do not intersect, then . To prove you need to put everything A 3 , A 4 , ... equal to the empty set and apply the property of countable additivity.
The probability measure may not be defined for all subsets of the set X. It is enough to define it on a sigma algebra, consisting of some subsets of the set X. In this case, random events are defined as measurable subsets of space X, that is, as elements of sigma algebra.
Probability sense
When we find that the reasons for some possible fact actually occurring outweigh the contrary reasons, we consider that fact probable, otherwise - incredible. This preponderance of positive bases over negative ones, and vice versa, can represent an indefinite set of degrees, as a result of which probability(And improbability) It happens more or less .
Complex individual facts do not allow for an exact calculation of the degrees of their probability, but even here it is important to establish some large subdivisions. So, for example, in the legal field, when a personal fact subject to trial is established on the basis of testimony, it always remains, strictly speaking, only probable, and it is necessary to know how significant this probability is; in Roman law, a quadruple division was adopted here: probatio plena(where the probability practically turns into reliability), Further - probatio minus plena, then - probatio semiplena major and finally probatio semiplena minor .
In addition to the question of the probability of the case, the question may arise, both in the field of law and in the moral field (with a certain ethical point of view), of how likely it is that a given particular fact constitutes a violation of the general law. This question, which serves as the main motive in the religious jurisprudence of the Talmud, also gave rise to very complex systematic constructions and a huge literature, dogmatic and polemical, in Roman Catholic moral theology (especially from the end of the 16th century) (see Probabilism).
The concept of probability allows for a certain numerical expression when applied only to such facts that are part of certain homogeneous series. So (in the simplest example), when someone throws a coin a hundred times in a row, we find here one general or large series (the sum of all falls of the coin), consisting of two private or smaller, in this case numerically equal, series (falls " heads" and falls "tails"); The probability that this time the coin will land heads, that is, that this new member of the general series will belong to this of the two smaller series, is equal to the fraction expressing the numerical relationship between this small series and the larger one, namely 1/2, that is, the same probability belongs to one or the other of two particular series. In less simple examples the conclusion cannot be deduced directly from the data of the problem itself, but requires preliminary induction. So, for example, the question is: what is the probability for a given newborn to live to be 80 years old? Here there must be a general, or large, series of a certain number of people born in similar conditions and dying at different ages (this number must be large enough to eliminate random deviations, and small enough to maintain the homogeneity of the series, for for a person, born, for example, in St. Petersburg into a wealthy, cultured family, the entire million-strong population of the city, a significant part of which consists of people from various groups who can die prematurely - soldiers, journalists, workers dangerous professions, - represents a group too heterogeneous for a true probability determination); let this general row consist of ten thousand human lives; it includes smaller series representing the number of people surviving to a particular age; one of these smaller series represents the number of people living to age 80. But it is impossible to determine the number of this smaller series (like all others) a priori; this is done purely inductively, through statistics. Suppose statistical studies have established that out of 10,000 middle-class St. Petersburg residents, only 45 live to be 80; thus this smaller series is related to the larger one as 45 to 10,000, and the probability for of this person to belong to this smaller series, that is, to live to be 80 years old, is expressed by the fraction 0.0045. The study of probability from a mathematical point of view constitutes a special discipline - probability theory.
see also
Notes
Literature
- Alfred Renyi. Letters on probability / trans. from Hungarian D. Saas and A. Crumley, eds. B.V. Gnedenko. M.: Mir. 1970
- Gnedenko B.V. Probability theory course. M., 2007. 42 p.
- Kuptsov V.I. Determinism and probability. M., 1976. 256 p.
Wikimedia Foundation. 2010.
Synonyms:Antonyms:
See what “Probability” is in other dictionaries:
General scientific and philosophical. a category denoting the quantitative degree of possibility of the occurrence of mass random events under fixed observation conditions, characterizing the stability of their relative frequencies. In logic, semantic degree... ... Philosophical Encyclopedia
PROBABILITY, a number in the range from zero to one inclusive, representing the possibility of a given event occurring. The probability of an event is defined as the ratio of the number of chances that an event can occur to the total number of possible... ... Scientific and technical encyclopedic dictionary
In all likelihood.. Dictionary of Russian synonyms and similar expressions. under. ed. N. Abramova, M.: Russian Dictionaries, 1999. probability possibility, likelihood, chance, objective possibility, maza, admissibility, risk. Ant. impossibility... ... Synonym dictionary
probability- A measure that an event is likely to occur. Note The mathematical definition of probability is: “a real number between 0 and 1 that is associated with a random event.” The number may reflect the relative frequency in a series of observations... ... Technical Translator's Guide
Probability- “mathematical, numerical characteristic the degree of possibility of the occurrence of any event in certain specific conditions that can be repeated an unlimited number of times.” Based on this classic... ... Economic and mathematical dictionary
- (probability) The possibility of the occurrence of an event or a certain result. It can be presented in the form of a scale with divisions from 0 to 1. If the probability of an event is zero, its occurrence is impossible. With a probability equal to 1, the onset of... Dictionary of business terms
Knowing how to estimate the likelihood of an event based on the odds is essential to choosing the right bet. If you don't understand how to convert a bookmaker's odds into a probability, you will never be able to determine how the bookmaker's odds compare to the actual odds of the event happening. You should understand that if the probability of an event according to the bookmakers is lower than the probability of the same event according to your own version, a bet on this event will be valuable. You can compare odds for different events on the website Odds.ru.
1.1. Types of odds
Bookmakers usually offer three types of odds - decimal, fractional and American. Let's look at each of the varieties.
1.2. Decimal odds
Decimal odds when multiplied by the bet size allow you to calculate the entire amount that you will receive in your hands if you win. For example, if you bet $1 on odds of 1.80, if you win, you will receive $1.80 ($1 is the bet amount returned, 0.80 is the winnings on the bet, which is also your net profit).
That is, the probability of outcome, according to bookmakers, is 55%.
1.3. Fractional odds
Fractional odds are the most traditional look coefficients The numerator shows the potential net winnings. The denominator is the amount of the bet that needs to be made in order to get this winning. For example, odds of 7/2 mean that in order to net a win of $7, you would need to bet $2.
In order to calculate the probability of an event based on a decimal coefficient, you should carry out simple calculations - divide the denominator by the sum of the numerator and denominator. For the above odds of 7/2, the calculation will be as follows:
2 / (7+2) = 2 / 9 = 0,22
That is, the probability of outcome, according to bookmakers, is 22%.
1.4. American odds
This type of odds is popular in North America. At first glance, they seem quite complex and incomprehensible, but do not be alarmed. Understanding American odds can be useful, for example, when playing in American casinos, to understand the quotes shown on North American sports broadcasts. Let's look at how to estimate the probability of an outcome based on American odds.
First of all, you need to understand that American odds can be positive and negative. A negative American coefficient always comes in the format, for example, “-150”. This means that in order to get 100 dollars net profit(win), you need to bet $150.
The positive American coefficient is calculated in reverse. For example, we have a coefficient of “+120”. This means that in order to get $120 in net profit (winnings), you need to bet $100.
The probability calculation based on negative American odds is done using the following formula:
(-(negative American coefficient)) / ((-(negative American coefficient)) + 100)
(-(-150)) / ((-(-150)) + 100) = 150 / (150 + 100) = 150 / 250 = 0,6
That is, the probability of an event for which a negative American coefficient of “-150” is given is 60%.
Now consider similar calculations for the positive American coefficient. The probability in this case is calculated using the following formula:
100 / (positive American coefficient + 100)
100 / (120 + 100) = 100 / 220 = 0.45
That is, the probability of an event for which a positive American coefficient of “+120” is given is 45%.
1.5. How to convert odds from one format to another?
The ability to convert odds from one format to another can serve you well later. Oddly enough, there are still offices in which the odds are not converted and are shown only in one format, which is unusual for us. Let's look at examples of how to do this. But first, we need to learn how to calculate the probability of an outcome based on the coefficient given to us.
1.6. How to calculate decimal odds based on probability?
Everything is very simple here. It is necessary to divide 100 by the probability of the event as a percentage. That is, if the estimated probability of an event is 60%, you need to:
With an estimated probability of an event of 60%, the decimal odds will be 1.66.
1.7. How to calculate fractional odds based on probability?
In this case, you need to divide 100 by the probability of the event and subtract one from the result obtained. For example, the probability of an event is 40%:
(100 / 40) — 1 = 2,5 — 1 = 1,5
That is, we get fractional coefficient 1.5/1 or, for ease of counting, 3/2.
1.8. How to calculate the American odds based on the probable outcome?
Here, much will depend on the probability of the event - whether it will be more than 50% or less. If the probability of an event is more than 50%, then the calculation will be made using the following formula:
- ((probability) / (100 - probability)) * 100
For example, if the probability of an event is 80%, then:
— (80 / (100 — 80)) * 100 = — (80 / 20) * 100 = -4 * 100 = (-400)
With an estimated probability of an event of 80%, we received a negative American coefficient of “-400”.
If the probability of an event is less than 50 percent, then the formula will be:
((100 - probability) / probability) * 100
For example, if the probability of an event is 40%, then:
((100-40) / 40) * 100 = (60 / 40) * 100 = 1,5 * 100 = 150
With an estimated probability of an event of 40%, we received a positive American coefficient of “+150”.
These calculations will help you better understand the concept of bets and odds, and learn how to evaluate the true value of a particular bet.
In fact, formulas (1) and (2) are a short record of conditional probability based on a contingency table of features. Let's return to the example discussed (Fig. 1). Suppose we learn that a family is planning to buy a wide-screen television. What is the probability that this family will actually buy such a TV?

Rice. 1. Widescreen TV Buying Behavior
In this case, we need to calculate the conditional probability P (purchase completed | purchase planned). Since we know that the family is planning to buy, the sample space does not consist of all 1000 families, but only those planning to buy a wide-screen TV. Of the 250 such families, 200 actually bought this TV. Therefore, the probability that a family will actually buy a wide-screen TV if they have planned to do so can be calculated using the following formula:
P (purchase completed | purchase planned) = number of families who planned and bought a wide-screen TV / number of families planning to buy a wide-screen TV = 200 / 250 = 0.8
Formula (2) gives the same result:

where is the event A is that the family is planning to purchase a widescreen TV, and the event IN- that she will actually buy it. Substituting real data into the formula, we get:
Decision tree
In Fig. 1 families are divided into four categories: those who planned to buy a wide-screen TV and those who did not, as well as those who bought such a TV and those who did not. A similar classification can be performed using a decision tree (Fig. 2). The tree shown in Fig. 2 has two branches corresponding to families who planned to purchase a widescreen TV and families who did not. Each of these branches splits into two additional branches corresponding to households that did and did not purchase a widescreen TV. The probabilities written at the ends of the two main branches are the unconditional probabilities of events A And A'. The probabilities written at the ends of the four additional branches are the conditional probabilities of each combination of events A And IN. Conditional probabilities are calculated by dividing the joint probability of events by the corresponding unconditional probability of each of them.

Rice. 2. Decision tree
For example, to calculate the probability that a family will buy a wide-screen television if it has planned to do so, one must determine the probability of the event purchase planned and completed, and then divide it by the probability of the event purchase planned. Moving along the decision tree shown in Fig. 2, we get the following (similar to the previous) answer:
Statistical independence
In the example of buying a wide-screen TV, the probability that a randomly selected family purchased a wide-screen TV given that they planned to do so is 200/250 = 0.8. Recall that the unconditional probability that a randomly selected family purchased a wide-screen TV is 300/1000 = 0.3. This leads to a very important conclusion. Prior information that the family was planning a purchase influences the likelihood of the purchase itself. In other words, these two events depend on each other. In contrast to this example, there are statistically independent events whose probabilities do not depend on each other. Statistical independence is expressed by the identity: P(A|B) = P(A), Where P(A|B)- probability of event A provided that the event occurred IN, P(A)- unconditional probability of event A.
Please note that events A And IN P(A|B) = P(A). If in a contingency table of characteristics having a size of 2×2, this condition is satisfied for at least one combination of events A And IN, it will be valid for any other combination. In our example events purchase planned And purchase completed are not statistically independent because information about one event affects the probability of another.
Let's look at an example that shows how to test the statistical independence of two events. Let's ask 300 families who bought a widescreen TV if they were satisfied with their purchase (Fig. 3). Determine whether the degree of satisfaction with the purchase and the type of TV are related.

Rice. 3. Data characterizing the degree of satisfaction of buyers of widescreen TVs
Judging by these data,
In the same time,
P (customer satisfied) = 240 / 300 = 0.80
Therefore, the probability that the customer is satisfied with the purchase and that the family purchased an HDTV are equal, and these events are statistically independent because they are not related in any way.
Probability multiplication rule
The formula for calculating conditional probability allows you to determine the probability of a joint event A and B. Having resolved formula (1)
![]()
relative to joint probability P(A and B), we obtain a general rule for multiplying probabilities. Probability of event A and B equal to the probability of the event A provided that the event occurs IN IN:
(3) P(A and B) = P(A|B) * P(B)
Let's take as an example 80 families who bought a widescreen HDTV television (Fig. 3). The table shows that 64 families are satisfied with the purchase and 16 are not. Let us assume that two families are randomly selected from among them. Determine the probability that both customers will be satisfied. Using formula (3), we obtain:
P(A and B) = P(A|B) * P(B)
where is the event A is that the second family is satisfied with their purchase, and the event IN- that the first family is satisfied with their purchase. The probability that the first family is satisfied with their purchase is 64/80. However, the likelihood that the second family is also satisfied with their purchase depends on the first family's response. If the first family does not return to the sample after the survey (selection without return), the number of respondents is reduced to 79. If the first family is satisfied with their purchase, the probability that the second family will also be satisfied is 63/79, since there are only 63 left in the sample families satisfied with their purchase. Thus, substituting specific data into formula (3), we obtain the following answer:
P(A and B) = (63/79)(64/80) = 0.638.
Therefore, the probability that both families are satisfied with their purchases is 63.8%.
Suppose that after the survey the first family returns to the sample. Determine the probability that both families will be satisfied with their purchase. In this case, the probability that both families are satisfied with their purchase is the same, equal to 64/80. Therefore, P(A and B) = (64/80)(64/80) = 0.64. Thus, the probability that both families are satisfied with their purchases is 64.0%. This example shows that the choice of the second family does not depend on the choice of the first. Thus, replacing the conditional probability in formula (3) P(A|B) probability P(A), we obtain a formula for multiplying the probabilities of independent events.
The rule for multiplying the probabilities of independent events. If events A And IN are statistically independent, the probability of an event A and B equal to the probability of the event A, multiplied by the probability of the event IN.
(4) P(A and B) = P(A)P(B)
If this rule is true for events A And IN, which means they are statistically independent. Thus, there are two ways to determine the statistical independence of two events:
- Events A And IN are statistically independent of each other if and only if P(A|B) = P(A).
- Events A And B are statistically independent of each other if and only if P(A and B) = P(A)P(B).
If in a 2x2 contingency table, one of these conditions is met for at least one combination of events A And B, it will be valid for any other combination.
Unconditional probability of an elementary event
(5) P(A) = P(A|B 1)P(B 1) + P(A|B 2)P(B 2) + … + P(A|B k)P(B k)
where events B 1, B 2, ... B k are mutually exclusive and exhaustive.
Let us illustrate the application of this formula using the example of Fig. 1. Using formula (5), we obtain:
P(A) = P(A|B 1)P(B 1) + P(A|B 2)P(B 2)
Where P(A)- the likelihood that the purchase was planned, P(B 1)- the probability that the purchase is made, P(B 2)- the probability that the purchase is not completed.
BAYES' THEOREM
The conditional probability of an event takes into account information that some other event has occurred. This approach can be used both to refine the probability taking into account newly received information, and to calculate the probability that the observed effect is a consequence of a specific cause. The procedure for refining these probabilities is called Bayes' theorem. It was first developed by Thomas Bayes in the 18th century.
Let's assume that the company mentioned above is researching the market for a new TV model. In the past, 40% of the TVs created by the company were successful, while 60% of the models were not recognized. Before announcing the release of a new model, marketing specialists carefully research the market and record demand. In the past, 80% of successful models were predicted to be successful, while 30% of successful predictions turned out to be wrong. The marketing department gave a favorable forecast for the new model. What is the likelihood that a new TV model will be in demand?
Bayes' theorem can be derived from the definitions of conditional probability (1) and (2). To calculate the probability P(B|A), take formula (2):
and substitute instead of P(A and B) the value from formula (3):
P(A and B) = P(A|B) * P(B)

Substituting formula (5) instead of P(A), we obtain Bayes’ theorem:
where events B 1, B 2, ... B k are mutually exclusive and exhaustive.
Let us introduce the following notation: event S - TV is in demand, event S’ - TV is not in demand, event F - favorable prognosis, event F’ - poor prognosis. Let’s assume that P(S) = 0.4, P(S’) = 0.6, P(F|S) = 0.8, P(F|S’) = 0.3. Applying Bayes' theorem we get:
Probability of demand for new model TV, subject to a favorable prognosis, is 0.64. Thus, the probability of lack of demand given a favorable forecast is 1–0.64=0.36. The calculation process is shown in Fig. 4.

Rice. 4. (a) Calculations using the Bayes formula to estimate the probability of demand for televisions; (b) Decision tree when studying demand for a new TV model
Let's look at an example of using Bayes' theorem for medical diagnostics. The probability that a person suffers from a particular disease is 0.03. A medical test can check if this is true. If a person is truly sick, the probability of an accurate diagnosis (saying that the person is sick when he really is sick) is 0.9. If a person is healthy, the probability of a false positive diagnosis (saying that a person is sick when he is healthy) is 0.02. Let's say that the medical test gives a positive result. What is the probability that a person is actually sick? What is the likelihood of an accurate diagnosis?
Let us introduce the following notation: event D - the person is sick, event D’ - the person is healthy, event T - diagnosis is positive, event T’ - diagnosis negative. From the conditions of the problem it follows that P(D) = 0.03, P(D’) = 0.97, P(T|D) = 0.90, P(T|D’) = 0.02. Applying formula (6), we obtain:
The probability that with a positive diagnosis a person is really sick is 0.582 (see also Fig. 5). Please note that the denominator of the Bayes formula is equal to the probability of a positive diagnosis, i.e. 0.0464.
